 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPUS: Towards Efficient and Principled Data Selection in Large Language Model Pre-training in Every Iteration
Feb 05, 2026As high-quality public text approaches exhaustion, a phenomenon known as the Data Wall, pre-training is shifting from more tokens to better tokens. However, existing methods either rely on heuristic static filters that ignore training dynamics, or use dynamic yet optimizer-agnostic criteria based on raw gradients. We propose OPUS (Optimizer-induced Projected Utility Selection), a dynamic data selection framework that defines utility in the optimizer-induced update space. OPUS scores candidates by projecting their effective updates, shaped by modern optimizers, onto a target direction derived from a stable, in-distribution proxy. To ensure scalability, we employ Ghost technique with CountSketch for computational efficiency, and Boltzmann sampling for data diversity, incurring only 4.7\% additional compute overhead. OPUS achieves remarkable results across diverse corpora, quality tiers, optimizers, and model scales. In pre-training of GPT-2 Large/XL on FineWeb and FineWeb-Edu with 30B tokens, OPUS outperforms industrial-level baselines and even full 200B-token training. Moreover, when combined with industrial-level static filters, OPUS further improves pre-training efficiency, even with lower-quality data. Furthermore, in continued pre-training of Qwen3-8B-Base on SciencePedia, OPUS achieves superior performance using only 0.5B tokens compared to full training with 3B tokens, demonstrating significant data efficiency gains in specialized domains.
Grounding and Enhancing Informativeness and Utility in Dataset Distillation
Jan 29, 2026Dataset Distillation (DD) seeks to create a compact dataset from a large, real-world dataset. While recent methods often rely on heuristic approaches to balance efficiency and quality, the fundamental relationship between original and synthetic data remains underexplored. This paper revisits knowledge distillation-based dataset distillation within a solid theoretical framework. We introduce the concepts of Informativeness and Utility, capturing crucial information within a sample and essential samples in the training set, respectively. Building on these principles, we define optimal dataset distillation mathematically. We then present InfoUtil, a framework that balances informativeness and utility in synthesizing the distilled dataset. InfoUtil incorporates two key components: (1) game-theoretic informativeness maximization using Shapley Value attribution to extract key information from samples, and (2) principled utility maximization by selecting globally influential samples based on Gradient Norm. These components ensure that the distilled dataset is both informative and utility-optimized. Experiments demonstrate that our method achieves a 6.1\% performance improvement over the previous state-of-the-art approach on ImageNet-1K dataset using ResNet-18.
M2G-Eval: Enhancing and Evaluating Multi-granularity Multilingual Code Generation
Dec 27, 2025The rapid advancement of code large language models (LLMs) has sparked significant research interest in systematically evaluating their code generation capabilities, yet existing benchmarks predominantly assess models at a single structural granularity and focus on limited programming languages, obscuring fine-grained capability variations across different code scopes and multilingual scenarios. We introduce M2G-Eval, a multi-granularity, multilingual framework for evaluating code generation in large language models (LLMs) across four levels: Class, Function, Block, and Line. Spanning 18 programming languages, M2G-Eval includes 17K+ training tasks and 1,286 human-annotated, contamination-controlled test instances. We develop M2G-Eval-Coder models by training Qwen3-8B with supervised fine-tuning and Group Relative Policy Optimization. Evaluating 30 models (28 state-of-the-art LLMs plus our two M2G-Eval-Coder variants) reveals three main findings: (1) an apparent difficulty hierarchy, with Line-level tasks easiest and Class-level most challenging; (2) widening performance gaps between full- and partial-granularity languages as task complexity increases; and (3) strong cross-language correlations, suggesting that models learn transferable programming concepts. M2G-Eval enables fine-grained diagnosis of code generation capabilities and highlights persistent challenges in synthesizing complex, long-form code.
LIR$^3$AG: A Lightweight Rerank Reasoning Strategy Framework for Retrieval-Augmented Generation
Dec 20, 2025Retrieval-Augmented Generation (RAG) effectively enhances Large Language Models (LLMs) by incorporating retrieved external knowledge into the generation process. Reasoning models improve LLM performance in multi-hop QA tasks, which require integrating and reasoning over multiple pieces of evidence across different documents to answer a complex question. However, they often introduce substantial computational costs, including increased token consumption and inference latency. To better understand and mitigate this trade-off, we conduct a comprehensive study of reasoning strategies for reasoning models in RAG multi-hop QA tasks. Our findings reveal that reasoning models adopt structured strategies to integrate retrieved and internal knowledge, primarily following two modes: Context-Grounded Reasoning, which relies directly on retrieved content, and Knowledge-Reconciled Reasoning, which resolves conflicts or gaps using internal knowledge. To this end, we propose a novel Lightweight Rerank Reasoning Strategy Framework for RAG (LiR$^3$AG) to enable non-reasoning models to transfer reasoning strategies by restructuring retrieved evidence into coherent reasoning chains. LiR$^3$AG significantly reduce the average 98% output tokens overhead and 58.6% inferencing time while improving 8B non-reasoning model's F1 performance ranging from 6.2% to 22.5% to surpass the performance of 32B reasoning model in RAG, offering a practical and efficient path forward for RAG systems.
NVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
VideoITG: Multimodal Video Understanding with Instructed Temporal Grounding
Jul 17, 2025Recent studies have revealed that selecting informative and relevant video frames can significantly improve the performance of Video Large Language Models (Video-LLMs). Current methods, such as reducing inter-frame redundancy, employing separate models for image-text relevance assessment, or utilizing temporal video grounding for event localization, substantially adopt unsupervised learning paradigms, whereas they struggle to address the complex scenarios in long video understanding. We propose Instructed Temporal Grounding for Videos (VideoITG), featuring customized frame sampling aligned with user instructions. The core of VideoITG is the VidThinker pipeline, an automated annotation framework that explicitly mimics the human annotation process. First, it generates detailed clip-level captions conditioned on the instruction; then, it retrieves relevant video segments through instruction-guided reasoning; finally, it performs fine-grained frame selection to pinpoint the most informative visual evidence. Leveraging VidThinker, we construct the VideoITG-40K dataset, containing 40K videos and 500K instructed temporal grounding annotations. We then design a plug-and-play VideoITG model, which takes advantage of visual language alignment and reasoning capabilities of Video-LLMs, for effective frame selection in a discriminative manner. Coupled with Video-LLMs, VideoITG achieves consistent performance improvements across multiple multimodal video understanding benchmarks, showing its superiority and great potentials for video understanding.
A Real-time Endoscopic Image Denoising System
Jun 18, 2025
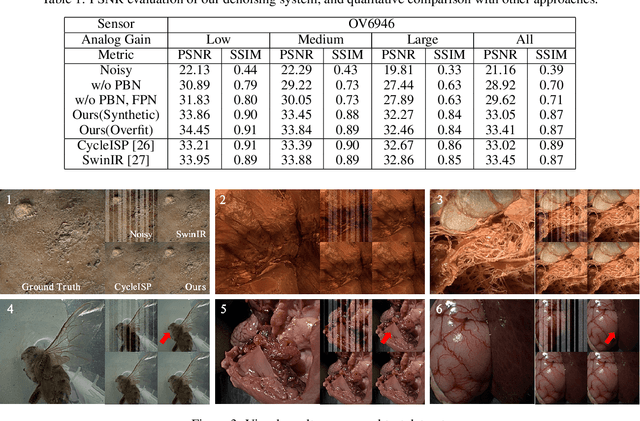

Endoscopes featuring a miniaturized design have significantly enhanced operational flexibility, portability, and diagnostic capability while substantially reducing the invasiveness of medical procedures. Recently, single-use endoscopes equipped with an ultra-compact analogue image sensor measuring less than 1mm x 1mm bring revolutionary advancements to medical diagnosis. They reduce the structural redundancy and large capital expenditures associated with reusable devices, eliminate the risk of patient infections caused by inadequate disinfection, and alleviate patient suffering. However, the limited photosensitive area results in reduced photon capture per pixel, requiring higher photon sensitivity settings to maintain adequate brightness. In high-contrast medical imaging scenarios, the small-sized sensor exhibits a constrained dynamic range, making it difficult to simultaneously capture details in both highlights and shadows, and additional localized digital gain is required to compensate. Moreover, the simplified circuit design and analog signal transmission introduce additional noise sources. These factors collectively contribute to significant noise issues in processed endoscopic images. In this work, we developed a comprehensive noise model for analog image sensors in medical endoscopes, addressing three primary noise types: fixed-pattern noise, periodic banding noise, and mixed Poisson-Gaussian noise. Building on this analysis, we propose a hybrid denoising system that synergistically combines traditional image processing algorithms with advanced learning-based techniques for captured raw frames from sensors. Experiments demonstrate that our approach effectively reduces image noise without fine detail loss or color distortion, while achieving real-time performance on FPGA platforms and an average PSNR improvement from 21.16 to 33.05 on our test dataset.
Bridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Jun 06, 2025



Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, enabling rich and complementary understanding of dynamic environments. In recent years, allowing the machines to leverage the synergistic potential of these dual perspectives has emerged as a compelling research direction in video understanding. In this survey, we provide a comprehensive review of video understanding from both exocentric and egocentric viewpoints. We begin by highlighting the practical applications of integrating egocentric and exocentric techniques, envisioning their potential collaboration across domains. We then identify key research tasks to realize these applications. Next, we systematically organize and review recent advancements into three main research directions: (1) leveraging egocentric data to enhance exocentric understanding, (2) utilizing exocentric data to improve egocentric analysis, and (3) joint learning frameworks that unify both perspectives. For each direction, we analyze a diverse set of tasks and relevant works. Additionally, we discuss benchmark datasets that support research in both perspectives, evaluating their scope, diversity, and applicability. Finally, we discuss limitations in current works and propose promising future research directions. By synthesizing insights from both perspectives, our goal is to inspire advancements in video understanding and artificial intelligence, bringing machines closer to perceiving the world in a human-like manner. A GitHub repo of related works can be found at https://github.com/ayiyayi/Awesome-Egocentric-and-Exocentric-Vision.
AV-Reasoner: Improving and Benchmarking Clue-Grounded Audio-Visual Counting for MLLMs
Jun 05, 2025Despite progress in video understanding, current MLLMs struggle with counting tasks. Existing benchmarks are limited by short videos, close-set queries, lack of clue annotations, and weak multimodal coverage. In this paper, we introduce CG-AV-Counting, a manually-annotated clue-grounded counting benchmark with 1,027 multimodal questions and 5,845 annotated clues over 497 long videos. It supports both black-box and white-box evaluation, serving as a comprehensive testbed for both end-to-end and reasoning-based counting. To explore ways to improve model's counting capability, we propose AV-Reasoner, a model trained with GRPO and curriculum learning to generalize counting ability from related tasks. AV-Reasoner achieves state-of-the-art results across multiple benchmarks, demonstrating the effectiveness of reinforcement learning. However, experiments show that on out-of-domain benchmarks, reasoning in the language space fails to bring performance gains. The code and benchmark have been realeased on https://av-reasoner.github.io.
Time-Frequency-Based Attention Cache Memory Model for Real-Time Speech Separation
May 19, 2025Existing causal speech separation models often underperform compared to non-causal models due to difficulties in retaining historical information. To address this, we propose the Time-Frequency Attention Cache Memory (TFACM) model, which effectively captures spatio-temporal relationships through an attention mechanism and cache memory (CM) for historical information storage. In TFACM, an LSTM layer captures frequency-relative positions, while causal modeling is applied to the time dimension using local and global representations. The CM module stores past information, and the causal attention refinement (CAR) module further enhances time-based feature representations for finer granularity. Experimental results showed that TFACM achieveed comparable performance to the SOTA TF-GridNet-Causal model, with significantly lower complexity and fewer trainable parameters. For more details, visit the project page: https://cslikai.cn/TFACM/.