 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAVER: A Training-Free Hierarchical Prompt Compression Method via Structure-Aware Page Selection
Mar 20, 2026The exponential expansion of context windows in LLMs has unlocked capabilities for long-document understanding but introduced severe bottlenecks in inference latency and information utilization. Existing compression methods often suffer from high training costs or semantic fragmentation due to aggressive token pruning. In this paper, we propose BEAVER, a novel training-free framework that shifts compression from linear token removal to structure-aware hierarchical selection. BEAVER maximizes hardware parallelism by mapping variable-length contexts into dense page-level tensors via dual-path pooling, and preserves discourse integrity through a hybrid planner combining semantic and lexical dual-branch selection with sentence smoothing. Extensive evaluations on four long-context benchmarks demonstrate that BEAVER achieves comparable performance to state-of-the-art (SOTA) methods like LongLLMLingua. Notably, on the RULER benchmark, BEAVER maintains high fidelity in multi-needle retrieval where baselines deteriorate. Regarding efficiency, BEAVER reduces latency by 26.4x on 128k contexts, offering a scalable solution for high-throughput applications. Our code is available at https://cslikai.cn/BEAVER/.
Speech Codec Probing from Semantic and Phonetic Perspectives
Mar 11, 2026Speech tokenizers are essential for connecting speech to large language models (LLMs) in multimodal systems. These tokenizers are expected to preserve both semantic and acoustic information for downstream understanding and generation. However, emerging evidence suggests that what is termed "semantic" in speech representations does not align with text-derived semantics: a mismatch that can degrade multimodal LLM performance. In this paper, we systematically analyze the information encoded by several widely used speech tokenizers, disentangling their semantic and phonetic content through word-level probing tasks, layerwise representation analysis, and cross-modal alignment metrics such as CKA. Our results show that current tokenizers primarily capture phonetic rather than lexical-semantic structure, and we derive practical implications for the design of next-generation speech tokenization methods.
Towards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
ComGS: Efficient 3D Object-Scene Composition via Surface Octahedral Probes
Oct 09, 2025Gaussian Splatting (GS) enables immersive rendering, but realistic 3D object-scene composition remains challenging. Baked appearance and shadow information in GS radiance fields cause inconsistencies when combining objects and scenes. Addressing this requires relightable object reconstruction and scene lighting estimation. For relightable object reconstruction, existing Gaussian-based inverse rendering methods often rely on ray tracing, leading to low efficiency. We introduce Surface Octahedral Probes (SOPs), which store lighting and occlusion information and allow efficient 3D querying via interpolation, avoiding expensive ray tracing. SOPs provide at least a 2x speedup in reconstruction and enable real-time shadow computation in Gaussian scenes. For lighting estimation, existing Gaussian-based inverse rendering methods struggle to model intricate light transport and often fail in complex scenes, while learning-based methods predict lighting from a single image and are viewpoint-sensitive. We observe that 3D object-scene composition primarily concerns the object's appearance and nearby shadows. Thus, we simplify the challenging task of full scene lighting estimation by focusing on the environment lighting at the object's placement. Specifically, we capture a 360 degrees reconstructed radiance field of the scene at the location and fine-tune a diffusion model to complete the lighting. Building on these advances, we propose ComGS, a novel 3D object-scene composition framework. Our method achieves high-quality, real-time rendering at around 28 FPS, produces visually harmonious results with vivid shadows, and requires only 36 seconds for editing. Code and dataset are available at https://nju-3dv.github.io/projects/ComGS/.
SpatialVID: A Large-Scale Video Dataset with Spatial Annotations
Sep 11, 2025Significant progress has been made in spatial intelligence, spanning both spatial reconstruction and world exploration. However, the scalability and real-world fidelity of current models remain severely constrained by the scarcity of large-scale, high-quality training data. While several datasets provide camera pose information, they are typically limited in scale, diversity, and annotation richness, particularly for real-world dynamic scenes with ground-truth camera motion. To this end, we collect \textbf{SpatialVID}, a dataset consists of a large corpus of in-the-wild videos with diverse scenes, camera movements and dense 3D annotations such as per-frame camera poses, depth, and motion instructions. Specifically, we collect more than 21,000 hours of raw video, and process them into 2.7 million clips through a hierarchical filtering pipeline, totaling 7,089 hours of dynamic content. A subsequent annotation pipeline enriches these clips with detailed spatial and semantic information, including camera poses, depth maps, dynamic masks, structured captions, and serialized motion instructions. Analysis of SpatialVID's data statistics reveals a richness and diversity that directly foster improved model generalization and performance, establishing it as a key asset for the video and 3D vision research community.
Beyond Window-Based Detection: A Graph-Centric Framework for Discrete Log Anomaly Detection
Jan 21, 2025



Detecting anomalies in discrete event logs is critical for ensuring system reliability, security, and efficiency. Traditional window-based methods for log anomaly detection often suffer from context bias and fuzzy localization, which hinder their ability to precisely and efficiently identify anomalies. To address these challenges, we propose a graph-centric framework, TempoLog, which leverages multi-scale temporal graph networks for discrete log anomaly detection. Unlike conventional methods, TempoLog constructs continuous-time dynamic graphs directly from event logs, eliminating the need for fixed-size window grouping. By representing log templates as nodes and their temporal relationships as edges, the framework dynamically captures both local and global dependencies across multiple temporal scales. Additionally, a semantic-aware model enhances detection by incorporating rich contextual information. Extensive experiments on public datasets demonstrate that our method achieves state-of-the-art performance in event-level anomaly detection, significantly outperforming existing approaches in both accuracy and efficiency.
Quantum Machine Learning in Log-based Anomaly Detection: Challenges and Opportunities
Dec 18, 2024Log-based anomaly detection (LogAD) is the main component of Artificial Intelligence for IT Operations (AIOps), which can detect anomalous that occur during the system on-the-fly. Existing methods commonly extract log sequence features using classical machine learning techniques to identify whether a new sequence is an anomaly or not. However, these classical approaches often require trade-offs between efficiency and accuracy. The advent of quantum machine learning (QML) offers a promising alternative. By transforming parts of classical machine learning computations into parameterized quantum circuits (PQCs), QML can significantly reduce the number of trainable parameters while maintaining accuracy comparable to classical counterparts. In this work, we introduce a unified framework, \ourframework{}, for evaluating QML models in the context of LogAD. This framework incorporates diverse log data, integrated QML models, and comprehensive evaluation metrics. State-of-the-art methods such as DeepLog, LogAnomaly, and LogRobust, along with their quantum-transformed counterparts, are included in our framework.Beyond standard metrics like F1 score, precision, and recall, our evaluation extends to factors critical to QML performance, such as specificity, the number of circuits, circuit design, and quantum state encoding. Using \ourframework{}, we conduct extensive experiments to assess the performance of these models and their quantum counterparts, uncovering valuable insights and paving the way for future research in QML model selection and design for LogAD.
SonicSim: A customizable simulation platform for speech processing in moving sound source scenarios
Oct 02, 2024
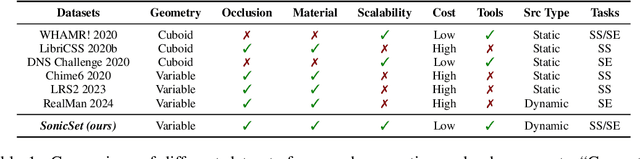

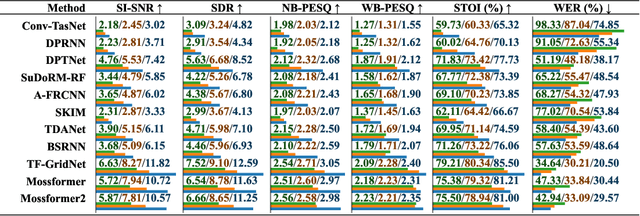
The systematic evaluation of speech separation and enhancement models under moving sound source conditions typically requires extensive data comprising diverse scenarios. However, real-world datasets often contain insufficient data to meet the training and evaluation requirements of models. Although synthetic datasets offer a larger volume of data, their acoustic simulations lack realism. Consequently, neither real-world nor synthetic datasets effectively fulfill practical needs. To address these issues, we introduce SonicSim, a synthetic toolkit de-designed to generate highly customizable data for moving sound sources. SonicSim is developed based on the embodied AI simulation platform, Habitat-sim, supporting multi-level adjustments, including scene-level, microphone-level, and source-level, thereby generating more diverse synthetic data. Leveraging SonicSim, we constructed a moving sound source benchmark dataset, SonicSet, using the Librispeech, the Freesound Dataset 50k (FSD50K) and Free Music Archive (FMA), and 90 scenes from the Matterport3D to evaluate speech separation and enhancement models. Additionally, to validate the differences between synthetic data and real-world data, we randomly selected 5 hours of raw data without reverberation from the SonicSet validation set to record a real-world speech separation dataset, which was then compared with the corresponding synthetic datasets. Similarly, we utilized the real-world speech enhancement dataset RealMAN to validate the acoustic gap between other synthetic datasets and the SonicSet dataset for speech enhancement. The results indicate that the synthetic data generated by SonicSim can effectively generalize to real-world scenarios. Demo and code are publicly available at https://cslikai.cn/SonicSim/.
InstructSing: High-Fidelity Singing Voice Generation via Instructing Yourself
Sep 10, 2024



It is challenging to accelerate the training process while ensuring both high-quality generated voices and acceptable inference speed. In this paper, we propose a novel neural vocoder called InstructSing, which can converge much faster compared with other neural vocoders while maintaining good performance by integrating differentiable digital signal processing and adversarial training. It includes one generator and two discriminators. Specifically, the generator incorporates a harmonic-plus-noise (HN) module to produce 8kHz audio as an instructive signal. Subsequently, the HN module is connected with an extended WaveNet by an UNet-based module, which transforms the output of the HN module to a latent variable sequence containing essential periodic and aperiodic information. In addition to the latent sequence, the extended WaveNet also takes the mel-spectrogram as input to generate 48kHz high-fidelity singing voices. In terms of discriminators, we combine a multi-period discriminator, as originally proposed in HiFiGAN, with a multi-resolution multi-band STFT discriminator. Notably, InstructSing achieves comparable voice quality to other neural vocoders but with only one-tenth of the training steps on a 4 NVIDIA V100 GPU machine\footnote{{Demo page: \href{https://wavelandspeech.github.io/instructsing/}{\texttt{https://wavelandspeech.github.io/inst\\ructsing/}}}}. We plan to open-source our code and pretrained model once the paper get accepted.
Spoofing-Aware Speaker Verification Robust Against Domain and Channel Mismatches
Sep 10, 2024In real-world applications, it is challenging to build a speaker verification system that is simultaneously robust against common threats, including spoofing attacks, channel mismatch, and domain mismatch. Traditional automatic speaker verification (ASV) systems often tackle these issues separately, leading to suboptimal performance when faced with simultaneous challenges. In this paper, we propose an integrated framework that incorporates pair-wise learning and spoofing attack simulation into the meta-learning paradigm to enhance robustness against these multifaceted threats. This novel approach employs an asymmetric dual-path model and a multi-task learning strategy to handle ASV, anti-spoofing, and spoofing-aware ASV tasks concurrently. A new testing dataset, CNComplex, is introduced to evaluate system performance under these combined threats. Experimental results demonstrate that our integrated model significantly improves performance over traditional ASV systems across various scenarios, showcasing its potential for real-world deployment. Additionally, the proposed framework's ability to generalize across different conditions highlights its robustness and reliability, making it a promising solution for practical ASV applications.