 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexGR: Efficient Generative Recommendation Serving at Scale
Dec 19, 2025Recommendation system delivers substantial economic benefits by providing personalized predictions. Generative recommendation (GR) integrates LLMs to enhance the understanding of long user-item sequences. Despite employing attention-based architectures, GR's workload differs markedly from that of LLM serving. GR typically processes long prompt while producing short, fixed-length outputs, yet the computational cost of each decode phase is especially high due to the large beam width. In addition, since the beam search involves a vast item space, the sorting overhead becomes particularly time-consuming. We propose xGR, a GR-oriented serving system that meets strict low-latency requirements under highconcurrency scenarios. First, xGR unifies the processing of prefill and decode phases through staged computation and separated KV cache. Second, xGR enables early sorting termination and mask-based item filtering with data structure reuse. Third, xGR reconstructs the overall pipeline to exploit multilevel overlap and multi-stream parallelism. Our experiments with real-world recommendation service datasets demonstrate that xGR achieves at least 3.49x throughput compared to the state-of-the-art baseline under strict latency constraints.
PRAGMA: A Profiling-Reasoned Multi-Agent Framework for Automatic Kernel Optimization
Nov 09, 2025Designing high-performance kernels requires expert-level tuning and a deep understanding of hardware characteristics. Recent advances in large language models (LLMs) have enabled automated kernel generation, yet most existing systems rely solely on correctness or execution time feedback, lacking the ability to reason about low-level performance bottlenecks. In this paper, we introduce PRAGMA, a profile-guided AI kernel generation framework that integrates execution feedback and fine-grained hardware profiling into the reasoning loop. PRAGMA enables LLMs to identify performance bottlenecks, preserve historical best versions, and iteratively refine code quality. We evaluate PRAGMA on KernelBench, covering GPU and CPU backends. Results show that PRAGMA consistently outperforms baseline AIKG without profiling enabled and achieves 2.81$\times$ and 2.30$\times$ averaged speedups against Torch on CPU and GPU platforms, respectively.
Flexible Operator Fusion for Fast Sparse Transformer with Diverse Masking on GPU
Jun 06, 2025Large language models are popular around the world due to their powerful understanding capabilities. As the core component of LLMs, accelerating Transformer through parallelization has gradually become a hot research topic. Mask layers introduce sparsity into Transformer to reduce calculations. However, previous works rarely focus on the performance optimization of sparse Transformer. Moreover, rule-based mechanisms ignore the fusion opportunities of mixed-type operators and fail to adapt to various sequence lengths. To address the above problems, we propose STOF, a framework that incorporates optimizations for Sparse Transformer via flexible masking and operator fusion on GPU. We firstly unify the storage format and kernel implementation for the multi-head attention. Then, we map fusion schemes to compilation templates and determine the optimal parameter setting through a two-stage search engine. The experimental results show that compared to the state-of-the-art work, STOF achieves maximum speedups of 1.7x in MHA computation and 1.5x in end-to-end inference.
Pre$^3$: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation
Jun 04, 2025Extensive LLM applications demand efficient structured generations, particularly for LR(1) grammars, to produce outputs in specified formats (e.g., JSON). Existing methods primarily parse LR(1) grammars into a pushdown automaton (PDA), leading to runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. To address these issues, we propose Pre$^3$ that exploits deterministic pushdown automata (DPDA) to optimize the constrained LLM decoding efficiency. First, by precomputing prefix-conditioned edges during the preprocessing, Pre$^3$ enables ahead-of-time edge analysis and thus makes parallel transition processing possible. Second, by leveraging the prefix-conditioned edges, Pre$^3$ introduces a novel approach that transforms LR(1) transition graphs into DPDA, eliminating the need for runtime path exploration and achieving edge transitions with minimal overhead. Pre$^3$ can be seamlessly integrated into standard LLM inference frameworks, reducing time per output token (TPOT) by up to 40% and increasing throughput by up to 36% in our experiments. Our code is available at https://github.com/ModelTC/lightllm.
Beyond Window-Based Detection: A Graph-Centric Framework for Discrete Log Anomaly Detection
Jan 21, 2025



Detecting anomalies in discrete event logs is critical for ensuring system reliability, security, and efficiency. Traditional window-based methods for log anomaly detection often suffer from context bias and fuzzy localization, which hinder their ability to precisely and efficiently identify anomalies. To address these challenges, we propose a graph-centric framework, TempoLog, which leverages multi-scale temporal graph networks for discrete log anomaly detection. Unlike conventional methods, TempoLog constructs continuous-time dynamic graphs directly from event logs, eliminating the need for fixed-size window grouping. By representing log templates as nodes and their temporal relationships as edges, the framework dynamically captures both local and global dependencies across multiple temporal scales. Additionally, a semantic-aware model enhances detection by incorporating rich contextual information. Extensive experiments on public datasets demonstrate that our method achieves state-of-the-art performance in event-level anomaly detection, significantly outperforming existing approaches in both accuracy and efficiency.
Quantum Machine Learning in Log-based Anomaly Detection: Challenges and Opportunities
Dec 18, 2024Log-based anomaly detection (LogAD) is the main component of Artificial Intelligence for IT Operations (AIOps), which can detect anomalous that occur during the system on-the-fly. Existing methods commonly extract log sequence features using classical machine learning techniques to identify whether a new sequence is an anomaly or not. However, these classical approaches often require trade-offs between efficiency and accuracy. The advent of quantum machine learning (QML) offers a promising alternative. By transforming parts of classical machine learning computations into parameterized quantum circuits (PQCs), QML can significantly reduce the number of trainable parameters while maintaining accuracy comparable to classical counterparts. In this work, we introduce a unified framework, \ourframework{}, for evaluating QML models in the context of LogAD. This framework incorporates diverse log data, integrated QML models, and comprehensive evaluation metrics. State-of-the-art methods such as DeepLog, LogAnomaly, and LogRobust, along with their quantum-transformed counterparts, are included in our framework.Beyond standard metrics like F1 score, precision, and recall, our evaluation extends to factors critical to QML performance, such as specificity, the number of circuits, circuit design, and quantum state encoding. Using \ourframework{}, we conduct extensive experiments to assess the performance of these models and their quantum counterparts, uncovering valuable insights and paving the way for future research in QML model selection and design for LogAD.
XAgents: A Framework for Interpretable Rule-Based Multi-Agents Cooperation
Nov 21, 2024



Extracting implicit knowledge and logical reasoning abilities from large language models (LLMs) has consistently been a significant challenge. The advancement of multi-agent systems has further en-hanced the capabilities of LLMs. Inspired by the structure of multi-polar neurons (MNs), we propose the XAgents framework, an in-terpretable multi-agent cooperative framework based on the IF-THEN rule-based system. The IF-Parts of the rules are responsible for logical reasoning and domain membership calculation, while the THEN-Parts are comprised of domain expert agents that generate domain-specific contents. Following the calculation of the member-ship, XAgetns transmits the task to the disparate domain rules, which subsequently generate the various responses. These re-sponses are analogous to the answers provided by different experts to the same question. The final response is reached at by eliminat-ing the hallucinations and erroneous knowledge of the LLM through membership computation and semantic adversarial genera-tion of the various domain rules. The incorporation of rule-based interpretability serves to bolster user confidence in the XAgents framework. We evaluate the efficacy of XAgents through a com-parative analysis with the latest AutoAgents, in which XAgents demonstrated superior performance across three distinct datasets. We perform post-hoc interpretable studies with SHAP algorithm and case studies, proving the interpretability of XAgent in terms of input-output feature correlation and rule-based semantics.
Generative Fuzzy System for Sequence Generation
Nov 21, 2024



Generative Models (GMs), particularly Large Language Models (LLMs), have garnered significant attention in machine learning and artificial intelligence for their ability to generate new data by learning the statistical properties of training data and creating data that resemble the original. This capability offers a wide range of applications across various domains. However, the complex structures and numerous model parameters of GMs make the input-output processes opaque, complicating the understanding and control of outputs. Moreover, the purely data-driven learning mechanism limits GM's ability to acquire broader knowledge. There remains substantial potential for enhancing the robustness and generalization capabilities of GMs. In this work, we introduce the fuzzy system, a classical modeling method that combines data and knowledge-driven mechanisms, to generative tasks. We propose a novel Generative Fuzzy System framework, named GenFS, which integrates the deep learning capabilities of GM with the interpretability and dual-driven mechanisms of fuzzy systems. Specifically, we propose an end-to-end GenFS-based model for sequence generation, called FuzzyS2S. A series of experimental studies were conducted on 12 datasets, covering three distinct categories of generative tasks: machine translation, code generation, and summary generation. The results demonstrate that FuzzyS2S outperforms the Transformer in terms of accuracy and fluency. Furthermore, it exhibits better performance on some datasets compared to state-of-the-art models T5 and CodeT5.
Logic-of-Thought: Injecting Logic into Contexts for Full Reasoning in Large Language Models
Sep 26, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks but their performance in complex logical reasoning tasks remains unsatisfactory. Although some prompting methods, such as Chain-of-Thought, can improve the reasoning ability of LLMs to some extent, they suffer from an unfaithful issue where derived conclusions may not align with the generated reasoning chain. To address this issue, some studies employ the approach of propositional logic to further enhance logical reasoning abilities of LLMs. However, the potential omissions in the extraction of logical expressions in these methods can cause information loss in the logical reasoning process, thereby generating incorrect results. To this end, we propose Logic-of-Thought (LoT) prompting which employs propositional logic to generate expanded logical information from input context, and utilizes the generated logical information as an additional augmentation to the input prompts, thereby enhancing the capability of logical reasoning. The LoT is orthogonal to existing prompting methods and can be seamlessly integrated with them. Extensive experiments demonstrate that LoT boosts the performance of various prompting methods with a striking margin across five logical reasoning tasks. In particular, the LoT enhances Chain-of-Thought's performance on the ReClor dataset by +4.35%; moreover, it improves Chain-of-Thought with Self-Consistency's performance on LogiQA by +5%; additionally, it boosts performance of Tree-of-Thoughts on ProofWriter dataset by +8%.
GroupDebate: Enhancing the Efficiency of Multi-Agent Debate Using Group Discussion
Sep 21, 2024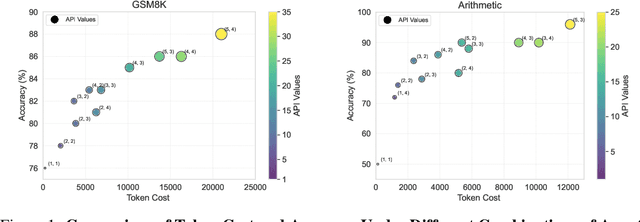
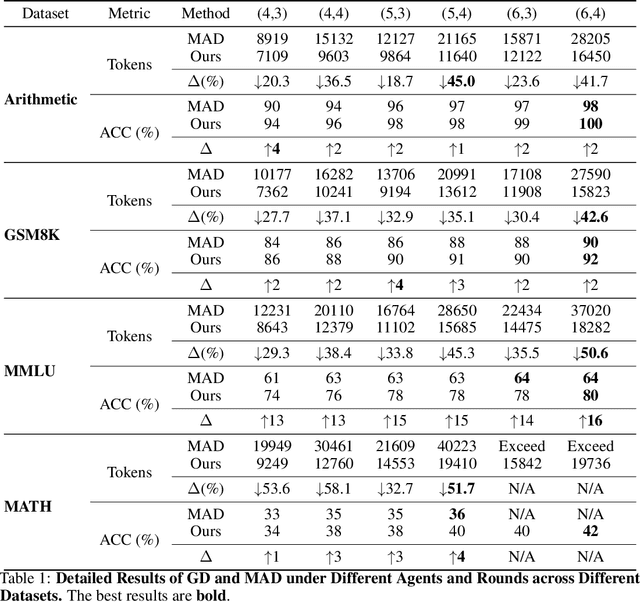
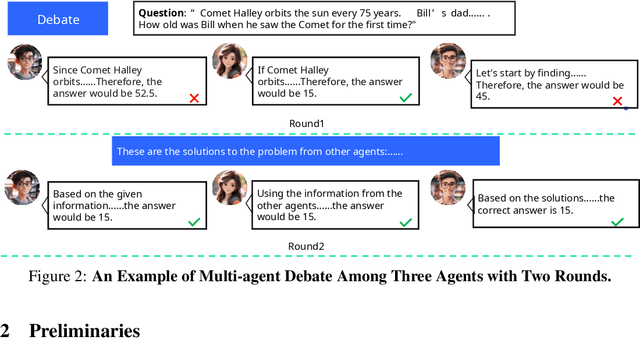
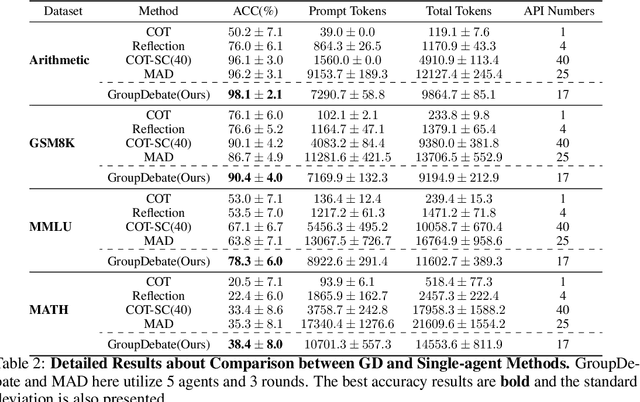
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse NLP tasks. Extensive research has explored how to enhance the logical reasoning abilities such as Chain-of-Thought, Chain-of-Thought with Self-Consistency, Tree-Of-Thoughts, and multi-agent debates. In the context of multi-agent debates, significant performance improvements can be achieved with an increasing number of agents and debate rounds. However, the escalation in the number of agents and debate rounds can drastically raise the tokens cost of debates, thereby limiting the scalability of the multi-agent debate technique. To better harness the advantages of multi-agent debates in logical reasoning tasks, this paper proposes a method to significantly reduce token cost in multi-agent debates. This approach involves dividing all agents into multiple debate groups, with agents engaging in debates within their respective groups and sharing interim debate results between groups. Comparative experiments across multiple datasets have demonstrated that this method can reduce the total tokens by up to 51.7% during debates and while potentially enhancing accuracy by as much as 25%. Our method significantly enhances the performance and efficiency of interactions in the multi-agent debate.