 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartThinker: Progressive Chain-of-Thought Length Calibration for Efficient Large Language Model Reasoning
Mar 09, 2026Large reasoning models (LRMs) like OpenAI o1 and DeepSeek-R1 achieve high accuracy on complex tasks by adopting long chain-of-thought (CoT) reasoning paths. However, the inherent verbosity of these processes frequently results in redundancy and overthinking. To address this issue, existing works leverage Group Relative Policy Optimization (GRPO) to reduce LRM output length, but their static length reward design cannot dynamically adapt according to the relative problem difficulty and response length distribution, causing over-compression and compromised accuracy. Therefore, we propose SmartThinker, a novel GRPO-based efficient reasoning method with progressive CoT length calibration. SmartThinker makes a two-fold contribution: First, it dynamically estimates the optimal length with peak accuracy during training and guides overlong responses toward it to reduce response length while sustaining accuracy. Second, it dynamically modulates the length reward coefficient to avoid the unwarranted penalization of correct reasoning paths. Extensive experiment results show that SmartThinker achieves up to 52.5% average length compression with improved accuracy, and achieves up to 16.6% accuracy improvement on challenging benchmarks like AIME25. The source code can be found at https://github.com/SJTU-RTEAS/SmartThinker.
VINO: A Unified Visual Generator with Interleaved OmniModal Context
Jan 05, 2026We present VINO, a unified visual generator that performs image and video generation and editing within a single framework. Instead of relying on task-specific models or independent modules for each modality, VINO uses a shared diffusion backbone that conditions on text, images and videos, enabling a broad range of visual creation and editing tasks under one model. Specifically, VINO couples a vision-language model (VLM) with a Multimodal Diffusion Transformer (MMDiT), where multimodal inputs are encoded as interleaved conditioning tokens, and then used to guide the diffusion process. This design supports multi-reference grounding, long-form instruction following, and coherent identity preservation across static and dynamic content, while avoiding modality-specific architectural components. To train such a unified system, we introduce a multi-stage training pipeline that progressively expands a video generation base model into a unified, multi-task generator capable of both image and video input and output. Across diverse generation and editing benchmarks, VINO demonstrates strong visual quality, faithful instruction following, improved reference and attribute preservation, and more controllable multi-identity edits. Our results highlight a practical path toward scalable unified visual generation, and the promise of interleaved, in-context computation as a foundation for general-purpose visual creation.
WinT3R: Window-Based Streaming Reconstruction with Camera Token Pool
Sep 05, 2025We present WinT3R, a feed-forward reconstruction model capable of online prediction of precise camera poses and high-quality point maps. Previous methods suffer from a trade-off between reconstruction quality and real-time performance. To address this, we first introduce a sliding window mechanism that ensures sufficient information exchange among frames within the window, thereby improving the quality of geometric predictions without large computation. In addition, we leverage a compact representation of cameras and maintain a global camera token pool, which enhances the reliability of camera pose estimation without sacrificing efficiency. These designs enable WinT3R to achieve state-of-the-art performance in terms of online reconstruction quality, camera pose estimation, and reconstruction speed, as validated by extensive experiments on diverse datasets. Code and model are publicly available at https://github.com/LiZizun/WinT3R.
HLLM-Creator: Hierarchical LLM-based Personalized Creative Generation
Aug 25, 2025AI-generated content technologies are widely used in content creation. However, current AIGC systems rely heavily on creators' inspiration, rarely generating truly user-personalized content. In real-world applications such as online advertising, a single product may have multiple selling points, with different users focusing on different features. This underscores the significant value of personalized, user-centric creative generation. Effective personalized content generation faces two main challenges: (1) accurately modeling user interests and integrating them into the content generation process while adhering to factual constraints, and (2) ensuring high efficiency and scalability to handle the massive user base in industrial scenarios. Additionally, the scarcity of personalized creative data in practice complicates model training, making data construction another key hurdle. We propose HLLM-Creator, a hierarchical LLM framework for efficient user interest modeling and personalized content generation. During inference, a combination of user clustering and a user-ad-matching-prediction based pruning strategy is employed to significantly enhance generation efficiency and reduce computational overhead, making the approach suitable for large-scale deployment. Moreover, we design a data construction pipeline based on chain-of-thought reasoning, which generates high-quality, user-specific creative titles and ensures factual consistency despite limited personalized data. This pipeline serves as a critical foundation for the effectiveness of our model. Extensive experiments on personalized title generation for Douyin Search Ads show the effectiveness of HLLM-Creator. Online A/B test shows a 0.476% increase on Adss, paving the way for more effective and efficient personalized generation in industrial scenarios. Codes for academic dataset are available at https://github.com/bytedance/HLLM.
$π^3$: Scalable Permutation-Equivariant Visual Geometry Learning
Jul 17, 2025We introduce $\pi^3$, a feed-forward neural network that offers a novel approach to visual geometry reconstruction, breaking the reliance on a conventional fixed reference view. Previous methods often anchor their reconstructions to a designated viewpoint, an inductive bias that can lead to instability and failures if the reference is suboptimal. In contrast, $\pi^3$ employs a fully permutation-equivariant architecture to predict affine-invariant camera poses and scale-invariant local point maps without any reference frames. This design makes our model inherently robust to input ordering and highly scalable. These advantages enable our simple and bias-free approach to achieve state-of-the-art performance on a wide range of tasks, including camera pose estimation, monocular/video depth estimation, and dense point map reconstruction. Code and models are publicly available.
Pre$^3$: Enabling Deterministic Pushdown Automata for Faster Structured LLM Generation
Jun 04, 2025Extensive LLM applications demand efficient structured generations, particularly for LR(1) grammars, to produce outputs in specified formats (e.g., JSON). Existing methods primarily parse LR(1) grammars into a pushdown automaton (PDA), leading to runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. To address these issues, we propose Pre$^3$ that exploits deterministic pushdown automata (DPDA) to optimize the constrained LLM decoding efficiency. First, by precomputing prefix-conditioned edges during the preprocessing, Pre$^3$ enables ahead-of-time edge analysis and thus makes parallel transition processing possible. Second, by leveraging the prefix-conditioned edges, Pre$^3$ introduces a novel approach that transforms LR(1) transition graphs into DPDA, eliminating the need for runtime path exploration and achieving edge transitions with minimal overhead. Pre$^3$ can be seamlessly integrated into standard LLM inference frameworks, reducing time per output token (TPOT) by up to 40% and increasing throughput by up to 36% in our experiments. Our code is available at https://github.com/ModelTC/lightllm.
Investigating Active Sampling for Hardness Classification with Vision-Based Tactile Sensors
May 19, 2025One of the most important object properties that humans and robots perceive through touch is hardness. This paper investigates information-theoretic active sampling strategies for sample-efficient hardness classification with vision-based tactile sensors. We evaluate three probabilistic classifier models and two model-uncertainty-based sampling strategies on a robotic setup as well as on a previously published dataset of samples collected by human testers. Our findings indicate that the active sampling approaches, driven by uncertainty metrics, surpass a random sampling baseline in terms of accuracy and stability. Additionally, while in our human study, the participants achieve an average accuracy of 48.00%, our best approach achieves an average accuracy of 88.78% on the same set of objects, demonstrating the effectiveness of vision-based tactile sensors for object hardness classification.
MeshCraft: Exploring Efficient and Controllable Mesh Generation with Flow-based DiTs
Mar 29, 2025In the domain of 3D content creation, achieving optimal mesh topology through AI models has long been a pursuit for 3D artists. Previous methods, such as MeshGPT, have explored the generation of ready-to-use 3D objects via mesh auto-regressive techniques. While these methods produce visually impressive results, their reliance on token-by-token predictions in the auto-regressive process leads to several significant limitations. These include extremely slow generation speeds and an uncontrollable number of mesh faces. In this paper, we introduce MeshCraft, a novel framework for efficient and controllable mesh generation, which leverages continuous spatial diffusion to generate discrete triangle faces. Specifically, MeshCraft consists of two core components: 1) a transformer-based VAE that encodes raw meshes into continuous face-level tokens and decodes them back to the original meshes, and 2) a flow-based diffusion transformer conditioned on the number of faces, enabling the generation of high-quality 3D meshes with a predefined number of faces. By utilizing the diffusion model for the simultaneous generation of the entire mesh topology, MeshCraft achieves high-fidelity mesh generation at significantly faster speeds compared to auto-regressive methods. Specifically, MeshCraft can generate an 800-face mesh in just 3.2 seconds (35$\times$ faster than existing baselines). Extensive experiments demonstrate that MeshCraft outperforms state-of-the-art techniques in both qualitative and quantitative evaluations on ShapeNet dataset and demonstrates superior performance on Objaverse dataset. Moreover, it integrates seamlessly with existing conditional guidance strategies, showcasing its potential to relieve artists from the time-consuming manual work involved in mesh creation.
Aether: Geometric-Aware Unified World Modeling
Mar 25, 2025The integration of geometric reconstruction and generative modeling remains a critical challenge in developing AI systems capable of human-like spatial reasoning. This paper proposes Aether, a unified framework that enables geometry-aware reasoning in world models by jointly optimizing three core capabilities: (1) 4D dynamic reconstruction, (2) action-conditioned video prediction, and (3) goal-conditioned visual planning. Through task-interleaved feature learning, Aether achieves synergistic knowledge sharing across reconstruction, prediction, and planning objectives. Building upon video generation models, our framework demonstrates unprecedented synthetic-to-real generalization despite never observing real-world data during training. Furthermore, our approach achieves zero-shot generalization in both action following and reconstruction tasks, thanks to its intrinsic geometric modeling. Remarkably, even without real-world data, its reconstruction performance is comparable with or even better than that of domain-specific models. Additionally, Aether employs camera trajectories as geometry-informed action spaces, enabling effective action-conditioned prediction and visual planning. We hope our work inspires the community to explore new frontiers in physically-reasonable world modeling and its applications.
Make Full Use of Testing Information: An Integrated Accelerated Testing and Evaluation Method for Autonomous Driving Systems
Jan 21, 2025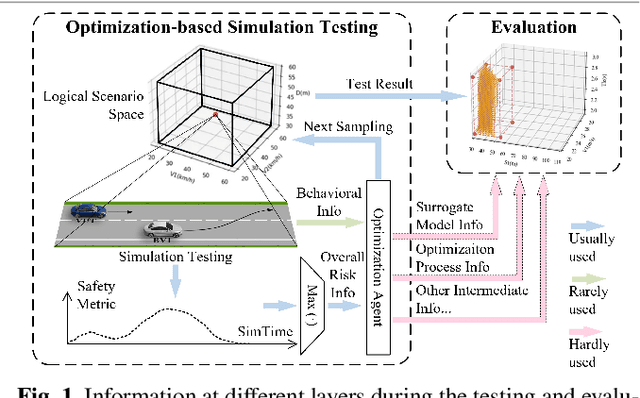
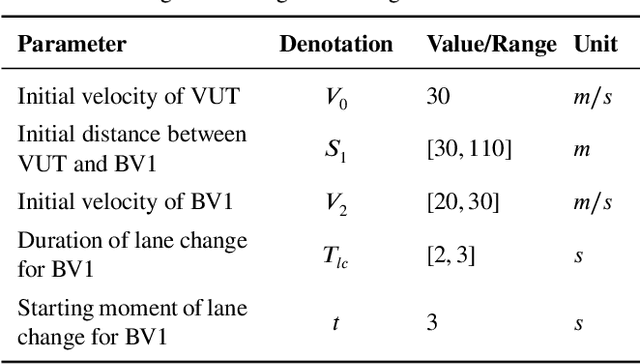
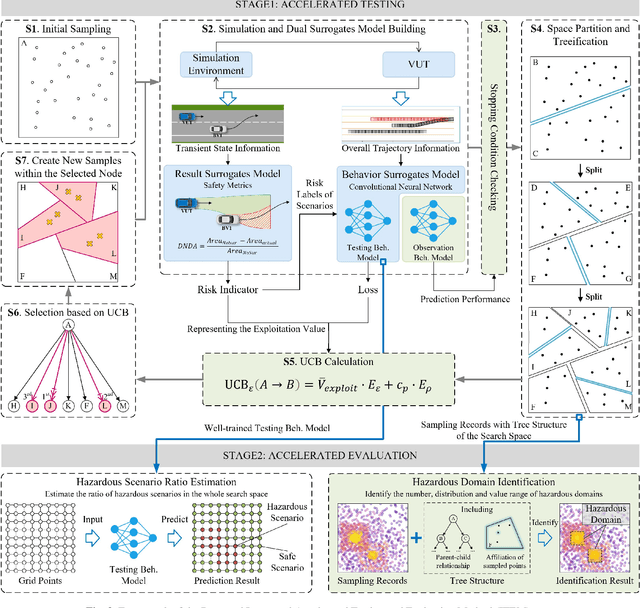
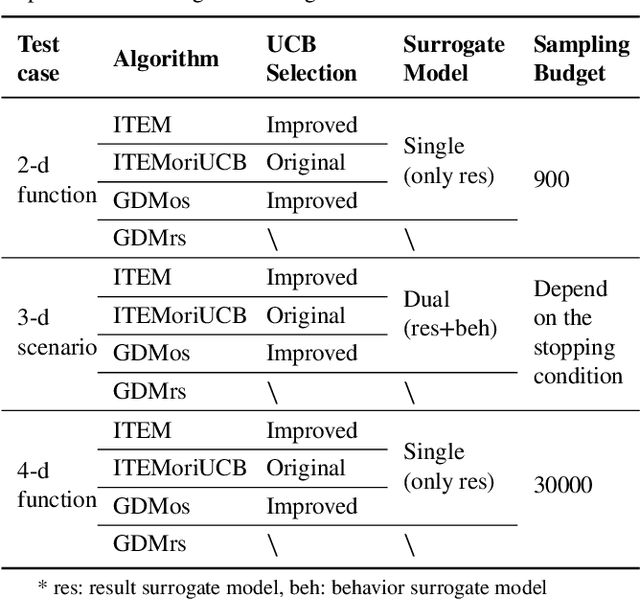
Testing and evaluation is an important step before the large-scale application of the autonomous driving systems (ADSs). Based on the three level of scenario abstraction theory, a testing can be performed within a logical scenario, followed by an evaluation stage which is inputted with the testing results of each concrete scenario generated from the logical parameter space. During the above process, abundant testing information is produced which is beneficial for comprehensive and accurate evaluations. To make full use of testing information, this paper proposes an Integrated accelerated Testing and Evaluation Method (ITEM). Based on a Monte Carlo Tree Search (MCTS) paradigm and a dual surrogates testing framework proposed in our previous work, this paper applies the intermediate information (i.e., the tree structure, including the affiliation of each historical sampled point with the subspaces and the parent-child relationship between subspaces) generated during the testing stage into the evaluation stage to achieve accurate hazardous domain identification. Moreover, to better serve this purpose, the UCB calculation method is improved to allow the search algorithm to focus more on the hazardous domain boundaries. Further, a stopping condition is constructed based on the convergence of the search algorithm. Ablation and comparative experiments are then conducted to verify the effectiveness of the improvements and the superiority of the proposed method. The experimental results show that ITEM could well identify the hazardous domains in both low- and high-dimensional cases, regardless of the shape of the hazardous domains, indicating its generality and potential for the safety evaluation of ADSs.