 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Hand Object Pose Estimation via Visual-Tactile Fusion
Jun 12, 2025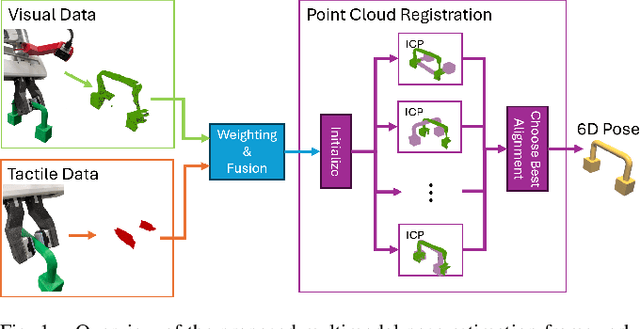
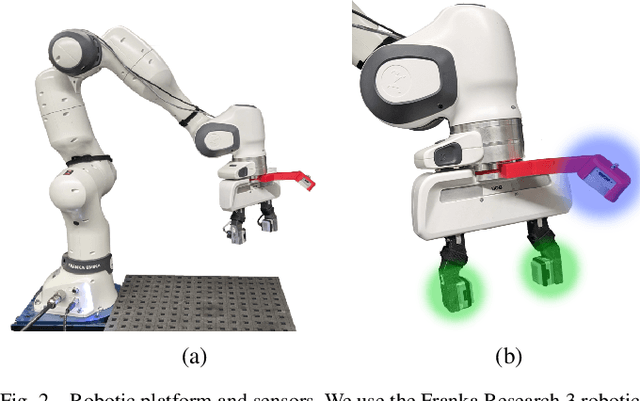
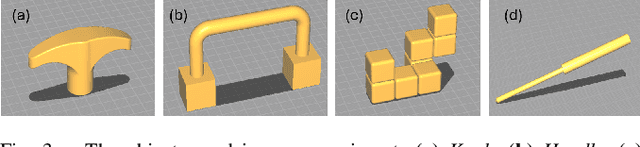
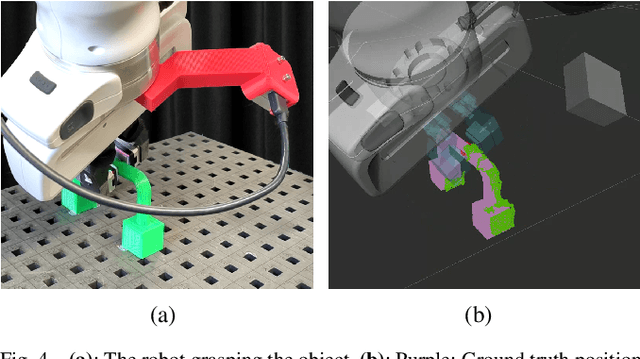
Accurate in-hand pose estimation is crucial for robotic object manipulation, but visual occlusion remains a major challenge for vision-based approaches. This paper presents an approach to robotic in-hand object pose estimation, combining visual and tactile information to accurately determine the position and orientation of objects grasped by a robotic hand. We address the challenge of visual occlusion by fusing visual information from a wrist-mounted RGB-D camera with tactile information from vision-based tactile sensors mounted on the fingertips of a robotic gripper. Our approach employs a weighting and sensor fusion module to combine point clouds from heterogeneous sensor types and control each modality's contribution to the pose estimation process. We use an augmented Iterative Closest Point (ICP) algorithm adapted for weighted point clouds to estimate the 6D object pose. Our experiments show that incorporating tactile information significantly improves pose estimation accuracy, particularly when occlusion is high. Our method achieves an average pose estimation error of 7.5 mm and 16.7 degrees, outperforming vision-only baselines by up to 20%. We also demonstrate the ability of our method to perform precise object manipulation in a real-world insertion task.
Investigating Active Sampling for Hardness Classification with Vision-Based Tactile Sensors
May 19, 2025One of the most important object properties that humans and robots perceive through touch is hardness. This paper investigates information-theoretic active sampling strategies for sample-efficient hardness classification with vision-based tactile sensors. We evaluate three probabilistic classifier models and two model-uncertainty-based sampling strategies on a robotic setup as well as on a previously published dataset of samples collected by human testers. Our findings indicate that the active sampling approaches, driven by uncertainty metrics, surpass a random sampling baseline in terms of accuracy and stability. Additionally, while in our human study, the participants achieve an average accuracy of 48.00%, our best approach achieves an average accuracy of 88.78% on the same set of objects, demonstrating the effectiveness of vision-based tactile sensors for object hardness classification.
Reinforcement Learning for Robust Athletic Intelligence: Lessons from the 2nd 'AI Olympics with RealAIGym' Competition
Mar 19, 2025In the field of robotics many different approaches ranging from classical planning over optimal control to reinforcement learning (RL) are developed and borrowed from other fields to achieve reliable control in diverse tasks. In order to get a clear understanding of their individual strengths and weaknesses and their applicability in real world robotic scenarios is it important to benchmark and compare their performances not only in a simulation but also on real hardware. The '2nd AI Olympics with RealAIGym' competition was held at the IROS 2024 conference to contribute to this cause and evaluate different controllers according to their ability to solve a dynamic control problem on an underactuated double pendulum system with chaotic dynamics. This paper describes the four different RL methods submitted by the participating teams, presents their performance in the swing-up task on a real double pendulum, measured against various criteria, and discusses their transferability from simulation to real hardware and their robustness to external disturbances.
TacEx: GelSight Tactile Simulation in Isaac Sim -- Combining Soft-Body and Visuotactile Simulators
Nov 07, 2024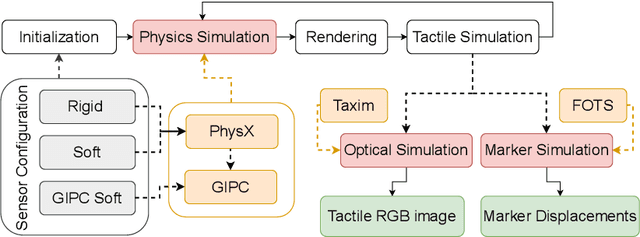
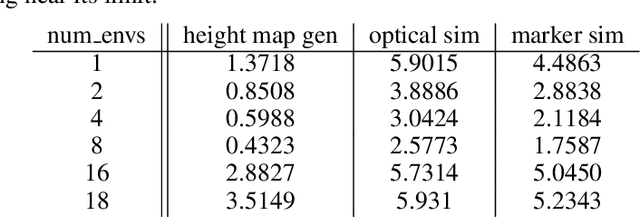
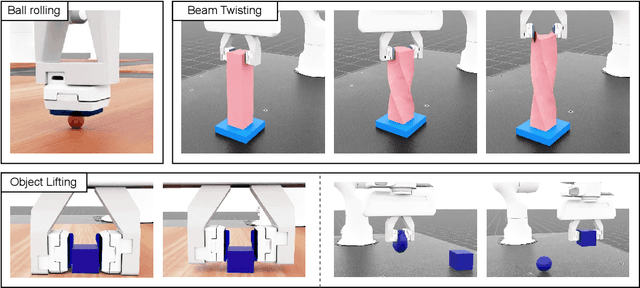

Training robot policies in simulation is becoming increasingly popular; nevertheless, a precise, reliable, and easy-to-use tactile simulator for contact-rich manipulation tasks is still missing. To close this gap, we develop TacEx -- a modular tactile simulation framework. We embed a state-of-the-art soft-body simulator for contacts named GIPC and vision-based tactile simulators Taxim and FOTS into Isaac Sim to achieve robust and plausible simulation of the visuotactile sensor GelSight Mini. We implement several Isaac Lab environments for Reinforcement Learning (RL) leveraging our TacEx simulation, including object pushing, lifting, and pole balancing. We validate that the simulation is stable and that the high-dimensional observations, such as the gel deformation and the RGB images from the GelSight camera, can be used for training. The code, videos, and additional results will be released online https://sites.google.com/view/tacex.
The Role of Domain Randomization in Training Diffusion Policies for Whole-Body Humanoid Control
Nov 02, 2024Humanoids have the potential to be the ideal embodiment in environments designed for humans. Thanks to the structural similarity to the human body, they benefit from rich sources of demonstration data, e.g., collected via teleoperation, motion capture, or even using videos of humans performing tasks. However, distilling a policy from demonstrations is still a challenging problem. While Diffusion Policies (DPs) have shown impressive results in robotic manipulation, their applicability to locomotion and humanoid control remains underexplored. In this paper, we investigate how dataset diversity and size affect the performance of DPs for humanoid whole-body control. In a simulated IsaacGym environment, we generate synthetic demonstrations by training Adversarial Motion Prior (AMP) agents under various Domain Randomization (DR) conditions, and we compare DPs fitted to datasets of different size and diversity. Our findings show that, although DPs can achieve stable walking behavior, successful training of locomotion policies requires significantly larger and more diverse datasets compared to manipulation tasks, even in simple scenarios.
Velocity-History-Based Soft Actor-Critic Tackling IROS'24 Competition "AI Olympics with RealAIGym"
Oct 26, 2024The ``AI Olympics with RealAIGym'' competition challenges participants to stabilize chaotic underactuated dynamical systems with advanced control algorithms. In this paper, we present a novel solution submitted to IROS'24 competition, which builds upon Soft Actor-Critic (SAC), a popular model-free entropy-regularized Reinforcement Learning (RL) algorithm. We add a `context' vector to the state, which encodes the immediate history via a Convolutional Neural Network (CNN) to counteract the unmodeled effects on the real system. Our method achieves high performance scores and competitive robustness scores on both tracks of the competition: Pendubot and Acrobot.
MuJoCo MPC for Humanoid Control: Evaluation on HumanoidBench
Aug 01, 2024We tackle the recently introduced benchmark for whole-body humanoid control HumanoidBench using MuJoCo MPC. We find that sparse reward functions of HumanoidBench yield undesirable and unrealistic behaviors when optimized; therefore, we propose a set of regularization terms that stabilize the robot behavior across tasks. Current evaluations on a subset of tasks demonstrate that our proposed reward function allows achieving the highest HumanoidBench scores while maintaining realistic posture and smooth control signals. Our code is publicly available and will become a part of MuJoCo MPC, enabling rapid prototyping of robot behaviors.
Adaptive $Q$-Network: On-the-fly Target Selection for Deep Reinforcement Learning
May 25, 2024

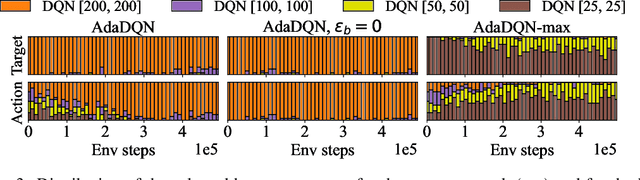
Deep Reinforcement Learning (RL) is well known for being highly sensitive to hyperparameters, requiring practitioners substantial efforts to optimize them for the problem at hand. In recent years, the field of automated Reinforcement Learning (AutoRL) has grown in popularity by trying to address this issue. However, these approaches typically hinge on additional samples to select well-performing hyperparameters, hindering sample-efficiency and practicality in RL. Furthermore, most AutoRL methods are heavily based on already existing AutoML methods, which were originally developed neglecting the additional challenges inherent to RL due to its non-stationarities. In this work, we propose a new approach for AutoRL, called Adaptive $Q$-Network (AdaQN), that is tailored to RL to take into account the non-stationarity of the optimization procedure without requiring additional samples. AdaQN learns several $Q$-functions, each one trained with different hyperparameters, which are updated online using the $Q$-function with the smallest approximation error as a shared target. Our selection scheme simultaneously handles different hyperparameters while coping with the non-stationarity induced by the RL optimization procedure and being orthogonal to any critic-based RL algorithm. We demonstrate that AdaQN is theoretically sound and empirically validate it in MuJoCo control problems, showing benefits in sample-efficiency, overall performance, training stability, and robustness to stochasticity.
What Matters for Active Texture Recognition With Vision-Based Tactile Sensors
Mar 20, 2024This paper explores active sensing strategies that employ vision-based tactile sensors for robotic perception and classification of fabric textures. We formalize the active sampling problem in the context of tactile fabric recognition and provide an implementation of information-theoretic exploration strategies based on minimizing predictive entropy and variance of probabilistic models. Through ablation studies and human experiments, we investigate which components are crucial for quick and reliable texture recognition. Along with the active sampling strategies, we evaluate neural network architectures, representations of uncertainty, influence of data augmentation, and dataset variability. By evaluating our method on a previously published Active Clothing Perception Dataset and on a real robotic system, we establish that the choice of the active exploration strategy has only a minor influence on the recognition accuracy, whereas data augmentation and dropout rate play a significantly larger role. In a comparison study, while humans achieve 66.9% recognition accuracy, our best approach reaches 90.0% in under 5 touches, highlighting that vision-based tactile sensors are highly effective for fabric texture recognition.
Iterated $Q$-Network: Beyond the One-Step Bellman Operator
Mar 04, 2024
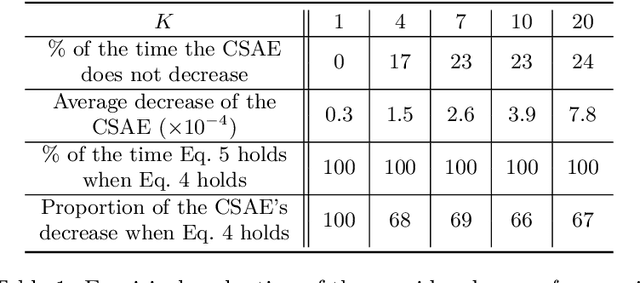


Value-based Reinforcement Learning (RL) methods rely on the application of the Bellman operator, which needs to be approximated from samples. Most approaches consist of an iterative scheme alternating the application of the Bellman operator and a subsequent projection step onto a considered function space. However, we observe that these algorithms can be improved by considering multiple iterations of the Bellman operator at once. Thus, we introduce iterated $Q$-Networks (iQN), a novel approach that learns a sequence of $Q$-function approximations where each $Q$-function serves as the target for the next one in a chain of consecutive Bellman iterations. We demonstrate that iQN is theoretically sound and show how it can be seamlessly used in value-based and actor-critic methods. We empirically demonstrate its advantages on Atari $2600$ games and in continuous-control MuJoCo environments.