 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterated $Q$-Network: Beyond the One-Step Bellman Operator
Paper and Code
Mar 04, 2024
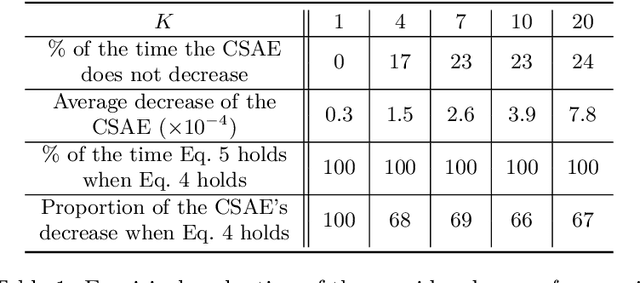


Value-based Reinforcement Learning (RL) methods rely on the application of the Bellman operator, which needs to be approximated from samples. Most approaches consist of an iterative scheme alternating the application of the Bellman operator and a subsequent projection step onto a considered function space. However, we observe that these algorithms can be improved by considering multiple iterations of the Bellman operator at once. Thus, we introduce iterated $Q$-Networks (iQN), a novel approach that learns a sequence of $Q$-function approximations where each $Q$-function serves as the target for the next one in a chain of consecutive Bellman iterations. We demonstrate that iQN is theoretically sound and show how it can be seamlessly used in value-based and actor-critic methods. We empirically demonstrate its advantages on Atari $2600$ games and in continuous-control MuJoCo environments.