 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Domain Randomization in Training Diffusion Policies for Whole-Body Humanoid Control
Nov 02, 2024Humanoids have the potential to be the ideal embodiment in environments designed for humans. Thanks to the structural similarity to the human body, they benefit from rich sources of demonstration data, e.g., collected via teleoperation, motion capture, or even using videos of humans performing tasks. However, distilling a policy from demonstrations is still a challenging problem. While Diffusion Policies (DPs) have shown impressive results in robotic manipulation, their applicability to locomotion and humanoid control remains underexplored. In this paper, we investigate how dataset diversity and size affect the performance of DPs for humanoid whole-body control. In a simulated IsaacGym environment, we generate synthetic demonstrations by training Adversarial Motion Prior (AMP) agents under various Domain Randomization (DR) conditions, and we compare DPs fitted to datasets of different size and diversity. Our findings show that, although DPs can achieve stable walking behavior, successful training of locomotion policies requires significantly larger and more diverse datasets compared to manipulation tasks, even in simple scenarios.
Exciting Action: Investigating Efficient Exploration for Learning Musculoskeletal Humanoid Locomotion
Jul 16, 2024Learning a locomotion controller for a musculoskeletal system is challenging due to over-actuation and high-dimensional action space. While many reinforcement learning methods attempt to address this issue, they often struggle to learn human-like gaits because of the complexity involved in engineering an effective reward function. In this paper, we demonstrate that adversarial imitation learning can address this issue by analyzing key problems and providing solutions using both current literature and novel techniques. We validate our methodology by learning walking and running gaits on a simulated humanoid model with 16 degrees of freedom and 92 Muscle-Tendon Units, achieving natural-looking gaits with only a few demonstrations.
Time-Efficient Reinforcement Learning with Stochastic Stateful Policies
Nov 07, 2023



Stateful policies play an important role in reinforcement learning, such as handling partially observable environments, enhancing robustness, or imposing an inductive bias directly into the policy structure. The conventional method for training stateful policies is Backpropagation Through Time (BPTT), which comes with significant drawbacks, such as slow training due to sequential gradient propagation and the occurrence of vanishing or exploding gradients. The gradient is often truncated to address these issues, resulting in a biased policy update. We present a novel approach for training stateful policies by decomposing the latter into a stochastic internal state kernel and a stateless policy, jointly optimized by following the stateful policy gradient. We introduce different versions of the stateful policy gradient theorem, enabling us to easily instantiate stateful variants of popular reinforcement learning and imitation learning algorithms. Furthermore, we provide a theoretical analysis of our new gradient estimator and compare it with BPTT. We evaluate our approach on complex continuous control tasks, e.g., humanoid locomotion, and demonstrate that our gradient estimator scales effectively with task complexity while offering a faster and simpler alternative to BPTT.
LocoMuJoCo: A Comprehensive Imitation Learning Benchmark for Locomotion
Nov 04, 2023
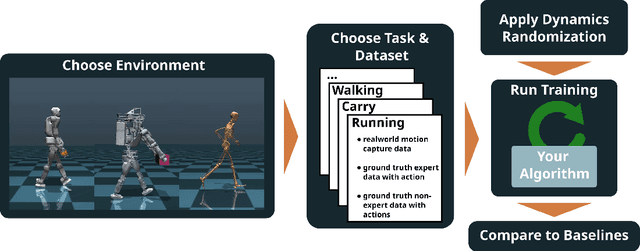
Imitation Learning (IL) holds great promise for enabling agile locomotion in embodied agents. However, many existing locomotion benchmarks primarily focus on simplified toy tasks, often failing to capture the complexity of real-world scenarios and steering research toward unrealistic domains. To advance research in IL for locomotion, we present a novel benchmark designed to facilitate rigorous evaluation and comparison of IL algorithms. This benchmark encompasses a diverse set of environments, including quadrupeds, bipeds, and musculoskeletal human models, each accompanied by comprehensive datasets, such as real noisy motion capture data, ground truth expert data, and ground truth sub-optimal data, enabling evaluation across a spectrum of difficulty levels. To increase the robustness of learned agents, we provide an easy interface for dynamics randomization and offer a wide range of partially observable tasks to train agents across different embodiments. Finally, we provide handcrafted metrics for each task and ship our benchmark with state-of-the-art baseline algorithms to ease evaluation and enable fast benchmarking.
LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning
Mar 01, 2023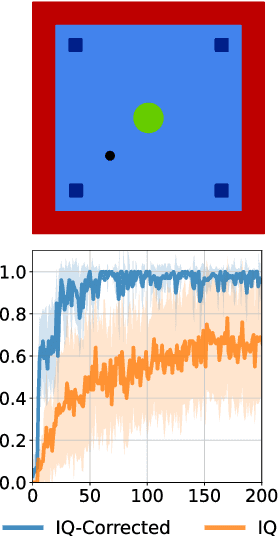
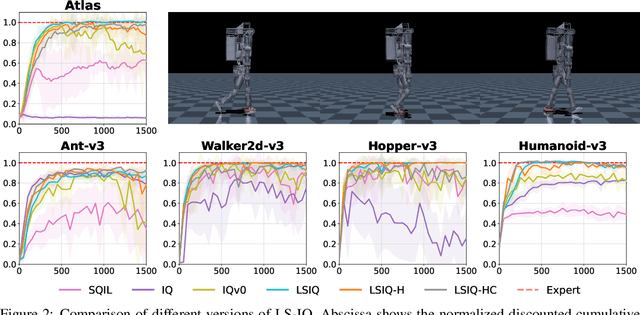
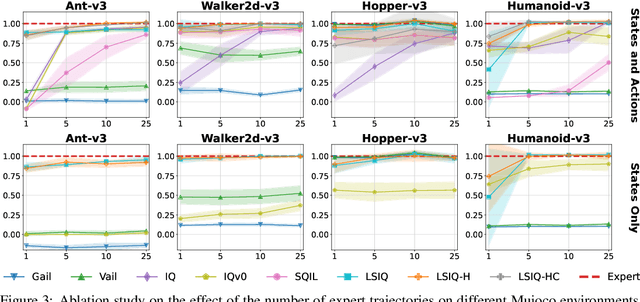
Recent methods for imitation learning directly learn a $Q$-function using an implicit reward formulation rather than an explicit reward function. However, these methods generally require implicit reward regularization to improve stability and often mistreat absorbing states. Previous works show that a squared norm regularization on the implicit reward function is effective, but do not provide a theoretical analysis of the resulting properties of the algorithms. In this work, we show that using this regularizer under a mixture distribution of the policy and the expert provides a particularly illuminating perspective: the original objective can be understood as squared Bellman error minimization, and the corresponding optimization problem minimizes a bounded $\chi^2$-Divergence between the expert and the mixture distribution. This perspective allows us to address instabilities and properly treat absorbing states. We show that our method, Least Squares Inverse Q-Learning (LS-IQ), outperforms state-of-the-art algorithms, particularly in environments with absorbing states. Finally, we propose to use an inverse dynamics model to learn from observations only. Using this approach, we retain performance in settings where no expert actions are available.