 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior-Constrained Reinforcement Learning with Receding-Horizon Credit Assignment for High-Performance Control
Apr 03, 2026Learning high-performance control policies that remain consistent with expert behavior is a fundamental challenge in robotics. Reinforcement learning can discover high-performing strategies but often departs from desirable human behavior, whereas imitation learning is limited by demonstration quality and struggles to improve beyond expert data. We propose a behavior-constrained reinforcement learning framework that improves beyond demonstrations while explicitly controlling deviation from expert behavior. Because expert-consistent behavior in dynamic control is inherently trajectory-level, we introduce a receding-horizon predictive mechanism that models short-term future trajectories and provides look-ahead rewards during training. To account for the natural variability of human behavior under disturbances and changing conditions, we further condition the policy on reference trajectories, allowing it to represent a distribution of expert-consistent behaviors rather than a single deterministic target. Empirically, we evaluate the approach in high-fidelity race car simulation using data from professional drivers, a domain characterized by extreme dynamics and narrow performance margins. The learned policies achieve competitive lap times while maintaining close alignment with expert driving behavior, outperforming baseline methods in both performance and imitation quality. Beyond standard benchmarks, we conduct human-grounded evaluation in a driver-in-the-loop simulator and show that the learned policies reproduce setup-dependent driving characteristics consistent with the feedback of top-class professional race drivers. These results demonstrate that our method enables learning high-performance control policies that are both optimal and behavior-consistent, and can serve as reliable surrogates for human decision-making in complex control systems.
GaussTwin: Unified Simulation and Correction with Gaussian Splatting for Robotic Digital Twins
Mar 05, 2026Digital twins promise to enhance robotic manipulation by maintaining a consistent link between real-world perception and simulation. However, most existing systems struggle with the lack of a unified model, complex dynamic interactions, and the real-to-sim gap, which limits downstream applications such as model predictive control. Thus, we propose GaussTwin, a real-time digital twin that combines position-based dynamics with discrete Cosserat rod formulations for physically grounded simulation, and Gaussian splatting for efficient rendering and visual correction. By anchoring Gaussians to physical primitives and enforcing coherent SE(3) updates driven by photometric error and segmentation masks, GaussTwin achieves stable prediction-correction while preserving physical fidelity. Through experiments in both simulation and on a Franka Research 3 platform, we show that GaussTwin consistently improves tracking accuracy and robustness compared to shape-matching and rigid-only baselines, while also enabling downstream tasks such as push-based planning. These results highlight GaussTwin as a step toward unified, physically meaningful digital twins that can support closed-loop robotic interaction and learning.
Context-Aware Deep Lagrangian Networks for Model Predictive Control
Jun 18, 2025Controlling a robot based on physics-informed dynamic models, such as deep Lagrangian networks (DeLaN), can improve the generalizability and interpretability of the resulting behavior. However, in complex environments, the number of objects to potentially interact with is vast, and their physical properties are often uncertain. This complexity makes it infeasible to employ a single global model. Therefore, we need to resort to online system identification of context-aware models that capture only the currently relevant aspects of the environment. While physical principles such as the conservation of energy may not hold across varying contexts, ensuring physical plausibility for any individual context-aware model can still be highly desirable, particularly when using it for receding horizon control methods such as Model Predictive Control (MPC). Hence, in this work, we extend DeLaN to make it context-aware, combine it with a recurrent network for online system identification, and integrate it with a MPC for adaptive, physics-informed control. We also combine DeLaN with a residual dynamics model to leverage the fact that a nominal model of the robot is typically available. We evaluate our method on a 7-DOF robot arm for trajectory tracking under varying loads. Our method reduces the end-effector tracking error by 39%, compared to a 21% improvement achieved by a baseline that uses an extended Kalman filter.
Maximum Total Correlation Reinforcement Learning
May 22, 2025Simplicity is a powerful inductive bias. In reinforcement learning, regularization is used for simpler policies, data augmentation for simpler representations, and sparse reward functions for simpler objectives, all that, with the underlying motivation to increase generalizability and robustness by focusing on the essentials. Supplementary to these techniques, we investigate how to promote simple behavior throughout the episode. To that end, we introduce a modification of the reinforcement learning problem that additionally maximizes the total correlation within the induced trajectories. We propose a practical algorithm that optimizes all models, including policy and state representation, based on a lower-bound approximation. In simulated robot environments, our method naturally generates policies that induce periodic and compressible trajectories, and that exhibit superior robustness to noise and changes in dynamics compared to baseline methods, while also improving performance in the original tasks.
Learning from Less: Guiding Deep Reinforcement Learning with Differentiable Symbolic Planning
May 16, 2025



When tackling complex problems, humans naturally break them down into smaller, manageable subtasks and adjust their initial plans based on observations. For instance, if you want to make coffee at a friend's place, you might initially plan to grab coffee beans, go to the coffee machine, and pour them into the machine. Upon noticing that the machine is full, you would skip the initial steps and proceed directly to brewing. In stark contrast, state of the art reinforcement learners, such as Proximal Policy Optimization (PPO), lack such prior knowledge and therefore require significantly more training steps to exhibit comparable adaptive behavior. Thus, a central research question arises: \textit{How can we enable reinforcement learning (RL) agents to have similar ``human priors'', allowing the agent to learn with fewer training interactions?} To address this challenge, we propose differentiable symbolic planner (Dylan), a novel framework that integrates symbolic planning into Reinforcement Learning. Dylan serves as a reward model that dynamically shapes rewards by leveraging human priors, guiding agents through intermediate subtasks, thus enabling more efficient exploration. Beyond reward shaping, Dylan can work as a high level planner that composes primitive policies to generate new behaviors while avoiding common symbolic planner pitfalls such as infinite execution loops. Our experimental evaluations demonstrate that Dylan significantly improves RL agents' performance and facilitates generalization to unseen tasks.
Machine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024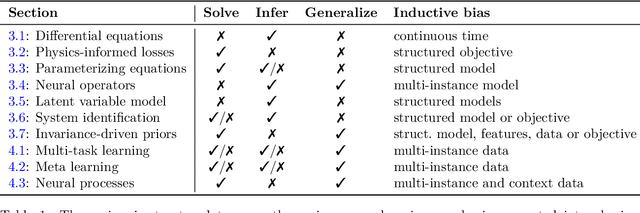
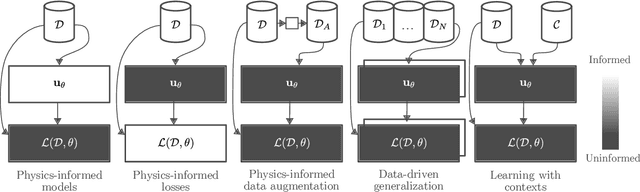
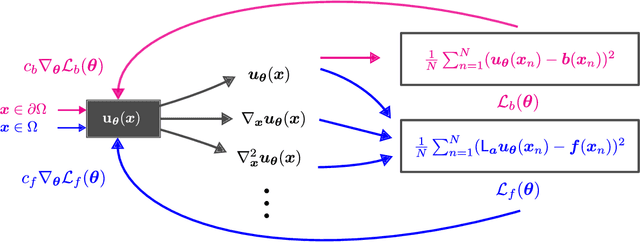
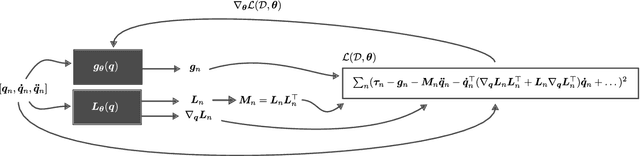
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning
Mar 01, 2023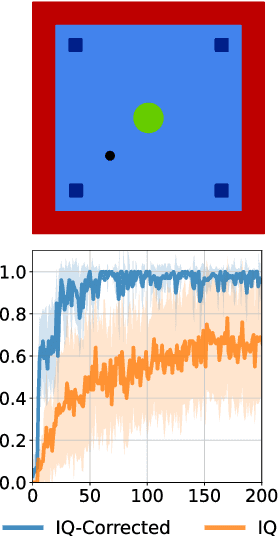
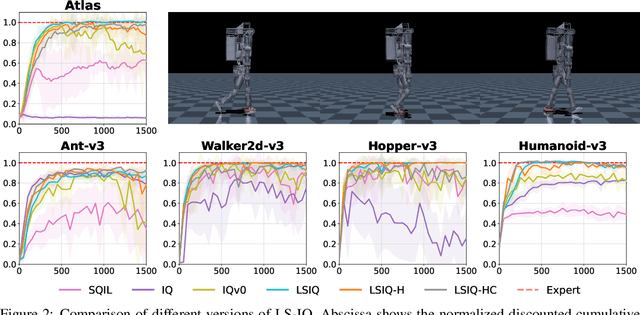
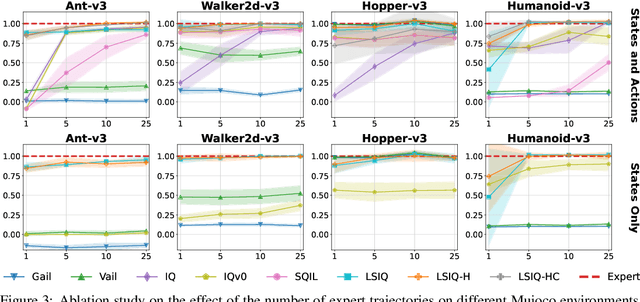
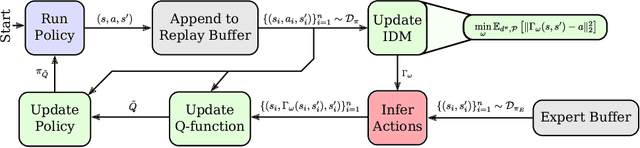
Recent methods for imitation learning directly learn a $Q$-function using an implicit reward formulation rather than an explicit reward function. However, these methods generally require implicit reward regularization to improve stability and often mistreat absorbing states. Previous works show that a squared norm regularization on the implicit reward function is effective, but do not provide a theoretical analysis of the resulting properties of the algorithms. In this work, we show that using this regularizer under a mixture distribution of the policy and the expert provides a particularly illuminating perspective: the original objective can be understood as squared Bellman error minimization, and the corresponding optimization problem minimizes a bounded $\chi^2$-Divergence between the expert and the mixture distribution. This perspective allows us to address instabilities and properly treat absorbing states. We show that our method, Least Squares Inverse Q-Learning (LS-IQ), outperforms state-of-the-art algorithms, particularly in environments with absorbing states. Finally, we propose to use an inverse dynamics model to learn from observations only. Using this approach, we retain performance in settings where no expert actions are available.
A Unified Perspective on Natural Gradient Variational Inference with Gaussian Mixture Models
Sep 23, 2022
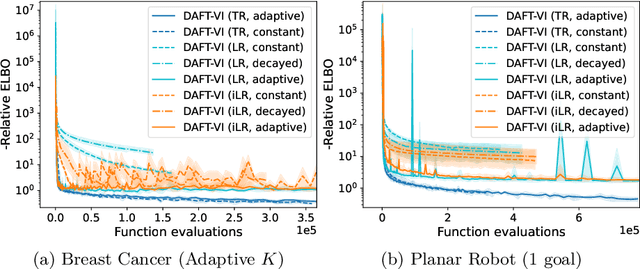
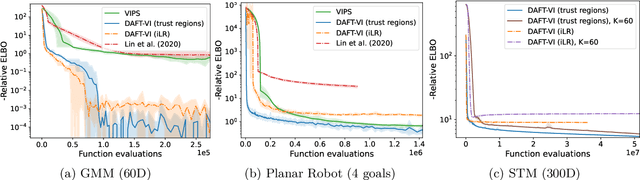
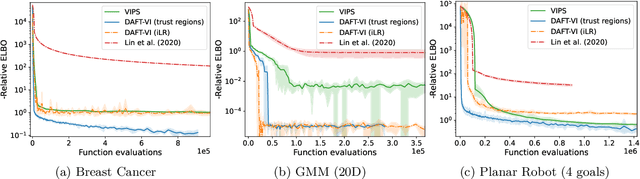
Variational inference with Gaussian mixture models (GMMs) enables learning of highly-tractable yet multi-modal approximations of intractable target distributions. GMMs are particular relevant for problem settings with up to a few hundred dimensions, for example in robotics, for modelling distributions over trajectories or joint distributions. This work focuses on two very effective methods for GMM-based variational inference that both employ independent natural gradient updates for the individual components and the categorical distribution of the weights. We show for the first time, that their derived updates are equivalent, although their practical implementations and theoretical guarantees differ. We identify several design choices that distinguish both approaches, namely with respect to sample selection, natural gradient estimation, stepsize adaptation, and whether trust regions are enforced or the number of components adapted. We perform extensive ablations on these design choices and show that they strongly affect the efficiency of the optimization and the variability of the learned distribution. Based on our insights, we propose a novel instantiation of our generalized framework, that combines first-order natural gradient estimates with trust-regions and component adaption, and significantly outperforms both previous methods in all our experiments.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022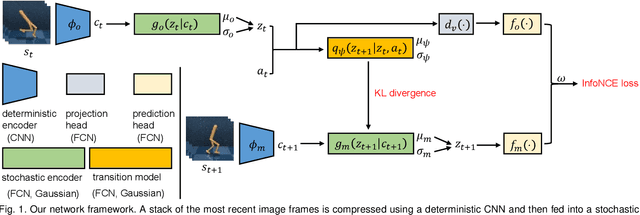
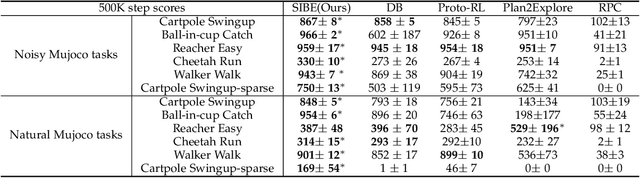
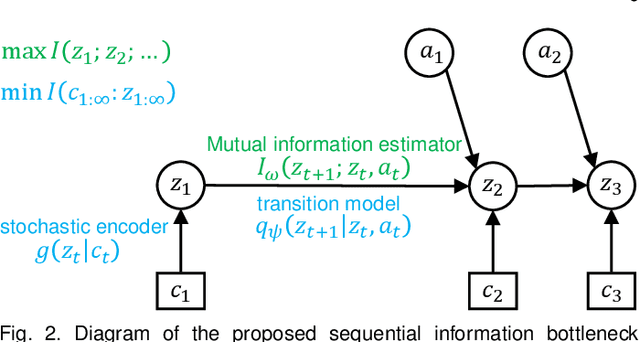

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
Integrating Contrastive Learning with Dynamic Models for Reinforcement Learning from Images
Mar 02, 2022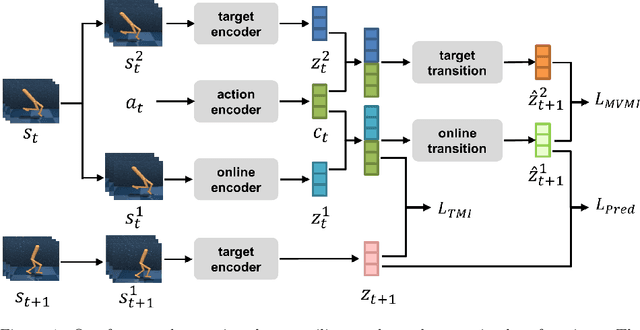

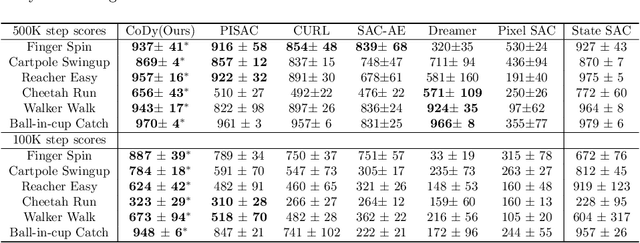
Recent methods for reinforcement learning from images use auxiliary tasks to learn image features that are used by the agent's policy or Q-function. In particular, methods based on contrastive learning that induce linearity of the latent dynamics or invariance to data augmentation have been shown to greatly improve the sample efficiency of the reinforcement learning algorithm and the generalizability of the learned embedding. We further argue, that explicitly improving Markovianity of the learned embedding is desirable and propose a self-supervised representation learning method which integrates contrastive learning with dynamic models to synergistically combine these three objectives: (1) We maximize the InfoNCE bound on the mutual information between the state- and action-embedding and the embedding of the next state to induce a linearly predictive embedding without explicitly learning a linear transition model, (2) we further improve Markovianity of the learned embedding by explicitly learning a non-linear transition model using regression, and (3) we maximize the mutual information between the two nonlinear predictions of the next embeddings based on the current action and two independent augmentations of the current state, which naturally induces transformation invariance not only for the state embedding, but also for the nonlinear transition model. Experimental evaluation on the Deepmind control suite shows that our proposed method achieves higher sample efficiency and better generalization than state-of-art methods based on contrastive learning or reconstruction.
* 28 pages, 11 figures, 5 tables