 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Efficient Reinforcement Learning with Stochastic Stateful Policies
Nov 07, 2023



Stateful policies play an important role in reinforcement learning, such as handling partially observable environments, enhancing robustness, or imposing an inductive bias directly into the policy structure. The conventional method for training stateful policies is Backpropagation Through Time (BPTT), which comes with significant drawbacks, such as slow training due to sequential gradient propagation and the occurrence of vanishing or exploding gradients. The gradient is often truncated to address these issues, resulting in a biased policy update. We present a novel approach for training stateful policies by decomposing the latter into a stochastic internal state kernel and a stateless policy, jointly optimized by following the stateful policy gradient. We introduce different versions of the stateful policy gradient theorem, enabling us to easily instantiate stateful variants of popular reinforcement learning and imitation learning algorithms. Furthermore, we provide a theoretical analysis of our new gradient estimator and compare it with BPTT. We evaluate our approach on complex continuous control tasks, e.g., humanoid locomotion, and demonstrate that our gradient estimator scales effectively with task complexity while offering a faster and simpler alternative to BPTT.
LocoMuJoCo: A Comprehensive Imitation Learning Benchmark for Locomotion
Nov 04, 2023
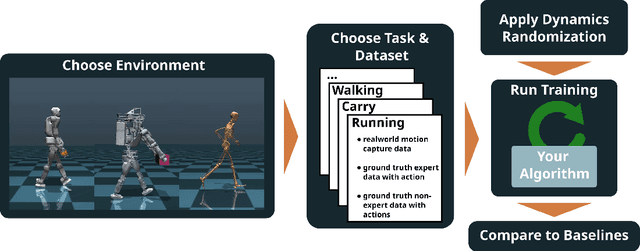
Imitation Learning (IL) holds great promise for enabling agile locomotion in embodied agents. However, many existing locomotion benchmarks primarily focus on simplified toy tasks, often failing to capture the complexity of real-world scenarios and steering research toward unrealistic domains. To advance research in IL for locomotion, we present a novel benchmark designed to facilitate rigorous evaluation and comparison of IL algorithms. This benchmark encompasses a diverse set of environments, including quadrupeds, bipeds, and musculoskeletal human models, each accompanied by comprehensive datasets, such as real noisy motion capture data, ground truth expert data, and ground truth sub-optimal data, enabling evaluation across a spectrum of difficulty levels. To increase the robustness of learned agents, we provide an easy interface for dynamics randomization and offer a wide range of partially observable tasks to train agents across different embodiments. Finally, we provide handcrafted metrics for each task and ship our benchmark with state-of-the-art baseline algorithms to ease evaluation and enable fast benchmarking.
LS-IQ: Implicit Reward Regularization for Inverse Reinforcement Learning
Mar 01, 2023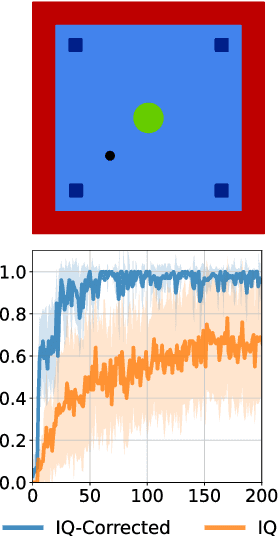
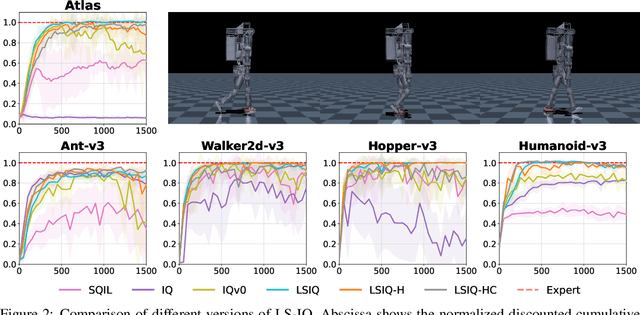
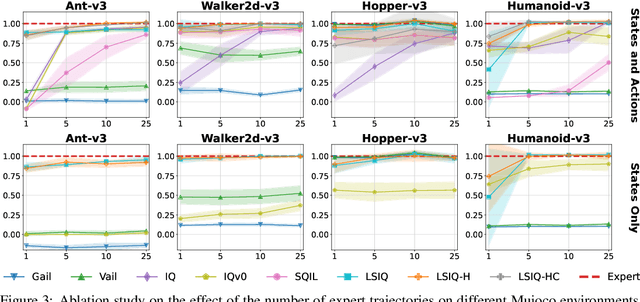
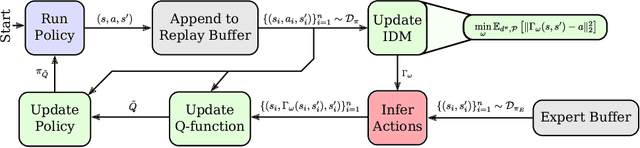
Recent methods for imitation learning directly learn a $Q$-function using an implicit reward formulation rather than an explicit reward function. However, these methods generally require implicit reward regularization to improve stability and often mistreat absorbing states. Previous works show that a squared norm regularization on the implicit reward function is effective, but do not provide a theoretical analysis of the resulting properties of the algorithms. In this work, we show that using this regularizer under a mixture distribution of the policy and the expert provides a particularly illuminating perspective: the original objective can be understood as squared Bellman error minimization, and the corresponding optimization problem minimizes a bounded $\chi^2$-Divergence between the expert and the mixture distribution. This perspective allows us to address instabilities and properly treat absorbing states. We show that our method, Least Squares Inverse Q-Learning (LS-IQ), outperforms state-of-the-art algorithms, particularly in environments with absorbing states. Finally, we propose to use an inverse dynamics model to learn from observations only. Using this approach, we retain performance in settings where no expert actions are available.
STAR-GNN: Spatial-Temporal Video Representation for Content-based Retrieval
Aug 15, 2022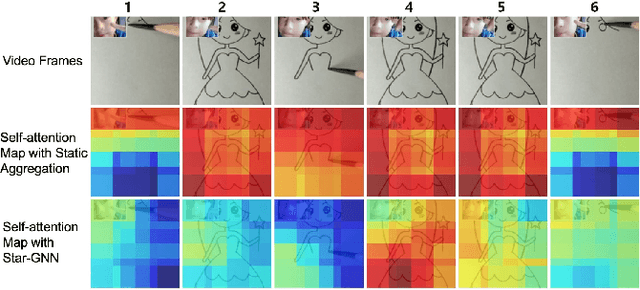
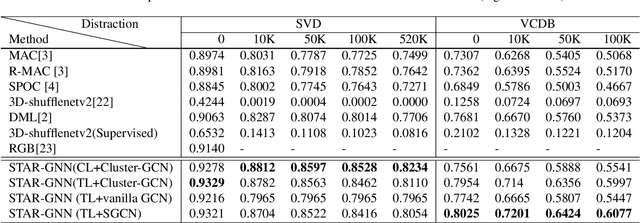
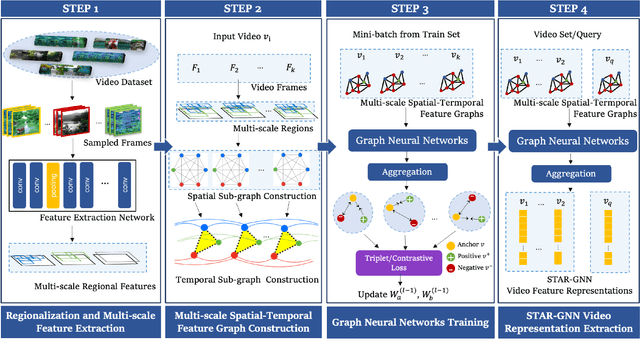
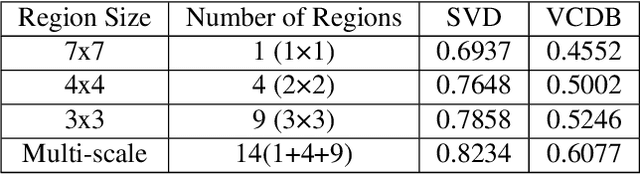
We propose a video feature representation learning framework called STAR-GNN, which applies a pluggable graph neural network component on a multi-scale lattice feature graph. The essence of STAR-GNN is to exploit both the temporal dynamics and spatial contents as well as visual connections between regions at different scales in the frames. It models a video with a lattice feature graph in which the nodes represent regions of different granularity, with weighted edges that represent the spatial and temporal links. The contextual nodes are aggregated simultaneously by graph neural networks with parameters trained with retrieval triplet loss. In the experiments, we show that STAR-GNN effectively implements a dynamic attention mechanism on video frame sequences, resulting in the emphasis for dynamic and semantically rich content in the video, and is robust to noise and redundancies. Empirical results show that STAR-GNN achieves state-of-the-art performance for Content-Based Video Retrieval.
InvisibiliTee: Angle-agnostic Cloaking from Person-Tracking Systems with a Tee
Aug 15, 2022
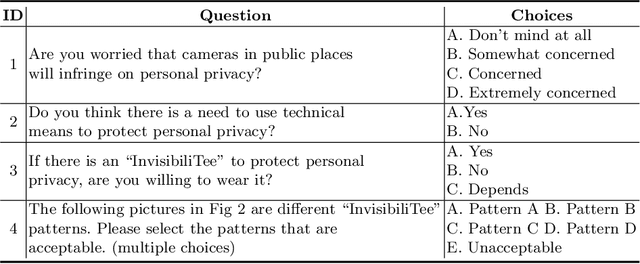


After a survey for person-tracking system-induced privacy concerns, we propose a black-box adversarial attack method on state-of-the-art human detection models called InvisibiliTee. The method learns printable adversarial patterns for T-shirts that cloak wearers in the physical world in front of person-tracking systems. We design an angle-agnostic learning scheme which utilizes segmentation of the fashion dataset and a geometric warping process so the adversarial patterns generated are effective in fooling person detectors from all camera angles and for unseen black-box detection models. Empirical results in both digital and physical environments show that with the InvisibiliTee on, person-tracking systems' ability to detect the wearer drops significantly.
Unsupervised Adversarial Attacks on Deep Feature-based Retrieval with GAN
Jul 12, 2019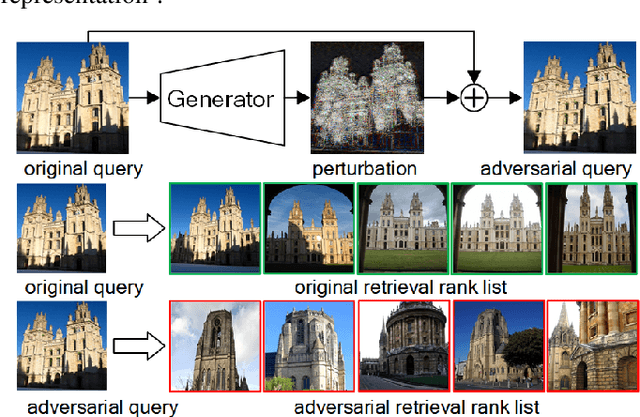
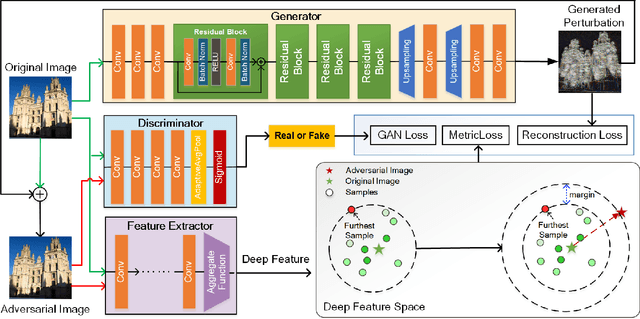
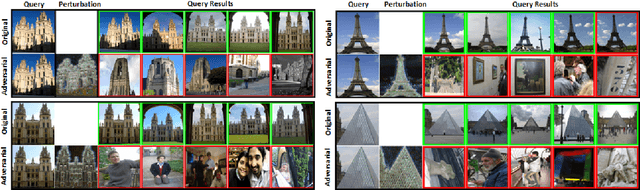

Studies show that Deep Neural Network (DNN)-based image classification models are vulnerable to maliciously constructed adversarial examples. However, little effort has been made to investigate how DNN-based image retrieval models are affected by such attacks. In this paper, we introduce Unsupervised Adversarial Attacks with Generative Adversarial Networks (UAA-GAN) to attack deep feature-based image retrieval systems. UAA-GAN is an unsupervised learning model that requires only a small amount of unlabeled data for training. Once trained, it produces query-specific perturbations for query images to form adversarial queries. The core idea is to ensure that the attached perturbation is barely perceptible to human yet effective in pushing the query away from its original position in the deep feature space. UAA-GAN works with various application scenarios that are based on deep features, including image retrieval, person Re-ID and face search. Empirical results show that UAA-GAN cripples retrieval performance without significant visual changes in the query images. UAA-GAN generated adversarial examples are less distinguishable because they tend to incorporate subtle perturbations in textured or salient areas of the images, such as key body parts of human, dominant structural patterns/textures or edges, rather than in visually insignificant areas (e.g., background and sky). Such tendency indicates that the model indeed learned how to toy with both image retrieval systems and human eyes.
RUM: network Representation learning throUgh Multi-level structural information preservation
Oct 08, 2017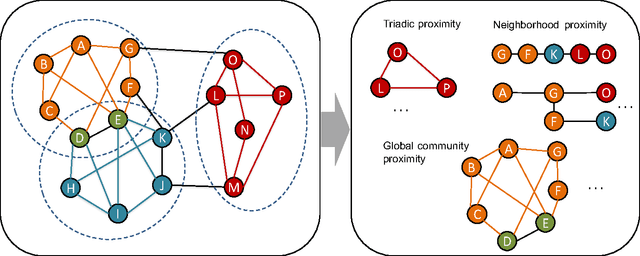
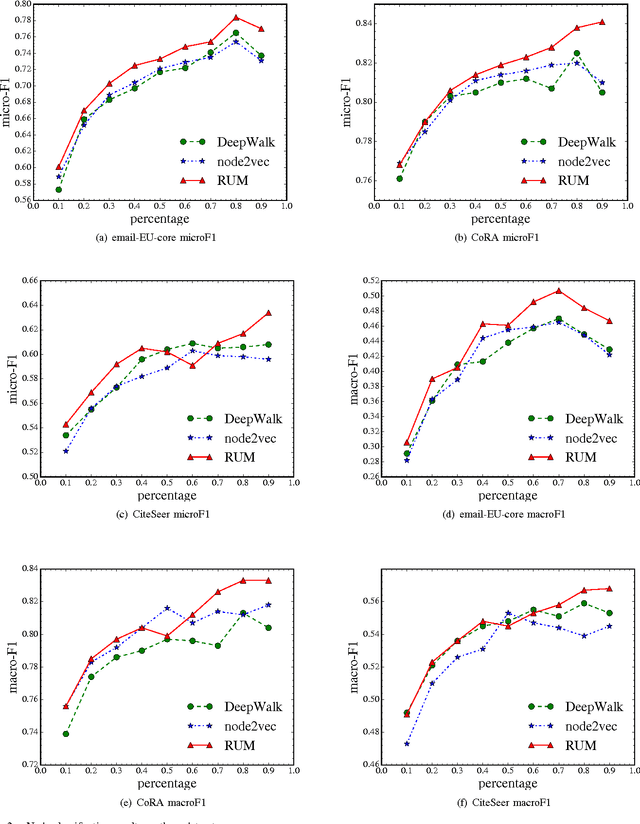
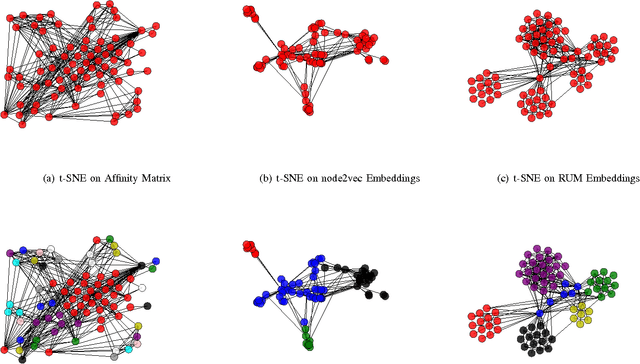
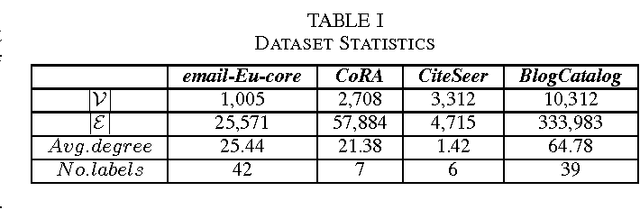
We have witnessed the discovery of many techniques for network representation learning in recent years, ranging from encoding the context in random walks to embedding the lower order connections, to finding latent space representations with auto-encoders. However, existing techniques are looking mostly into the local structures in a network, while higher-level properties such as global community structures are often neglected. We propose a novel network representations learning model framework called RUM (network Representation learning throUgh Multi-level structural information preservation). In RUM, we incorporate three essential aspects of a node that capture a network's characteristics in multiple levels: a node's affiliated local triads, its neighborhood relationships, and its global community affiliations. Therefore the framework explicitly and comprehensively preserves the structural information of a network, extending the encoding process both to the local end of the structural information spectrum and to the global end. The framework is also flexible enough to take various community discovery algorithms as its preprocessor. Empirical results show that the representations learned by RUM have demonstrated substantial performance advantages in real-life tasks.