 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Foundation Models for Crystal Structure Prediction
Mar 13, 2025



Crystal Structure Prediction (CSP), which aims to generate stable crystal structures from compositions, represents a critical pathway for discovering novel materials. While structure prediction tasks in other domains, such as proteins, have seen remarkable progress, CSP remains a relatively underexplored area due to the more complex geometries inherent in crystal structures. In this paper, we propose Siamese foundation models specifically designed to address CSP. Our pretrain-finetune framework, named DAO, comprises two complementary foundation models: DAO-G for structure generation and DAO-P for energy prediction. Experiments on CSP benchmarks (MP-20 and MPTS-52) demonstrate that our DAO-G significantly surpasses state-of-the-art (SOTA) methods across all metrics. Extensive ablation studies further confirm that DAO-G excels in generating diverse polymorphic structures, and the dataset relaxation and energy guidance provided by DAO-P are essential for enhancing DAO-G's performance. When applied to three real-world superconductors ($\text{CsV}_3\text{Sb}_5$, $ \text{Zr}_{16}\text{Rh}_8\text{O}_4$ and $\text{Zr}_{16}\text{Pd}_8\text{O}_4$) that are known to be challenging to analyze, our foundation models achieve accurate critical temperature predictions and structure generations. For instance, on $\text{CsV}_3\text{Sb}_5$, DAO-G generates a structure close to the experimental one with an RMSE of 0.0085; DAO-P predicts the $T_c$ value with high accuracy (2.26 K vs. the ground-truth value of 2.30 K). In contrast, conventional DFT calculators like Quantum Espresso only successfully derive the structure of the first superconductor within an acceptable time, while the RMSE is nearly 8 times larger, and the computation speed is more than 1000 times slower. These compelling results collectively highlight the potential of our approach for advancing materials science research and development.
Enabling Large Language Models to Learn from Rules
Nov 15, 2023Large language models (LLMs) have shown incredible performance in completing various real-world tasks. The current knowledge learning paradigm of LLMs is mainly based on learning from examples, in which LLMs learn the internal rule implicitly from a certain number of supervised examples. However, the learning paradigm may not well learn those complicated rules, especially when the training examples are limited. We are inspired that humans can learn the new tasks or knowledge in another way by learning from rules. That is, humans can grasp the new tasks or knowledge quickly and generalize well given only a detailed rule and a few optional examples. Therefore, in this paper, we aim to explore the feasibility of this new learning paradigm, which encodes the rule-based knowledge into LLMs. We propose rule distillation, which first uses the strong in-context abilities of LLMs to extract the knowledge from the textual rules and then explicitly encode the knowledge into LLMs' parameters by learning from the above in-context signals produced inside the model. Our experiments show that making LLMs learn from rules by our method is much more efficient than example-based learning in both the sample size and generalization ability.
Atomic and Subgraph-aware Bilateral Aggregation for Molecular Representation Learning
May 22, 2023
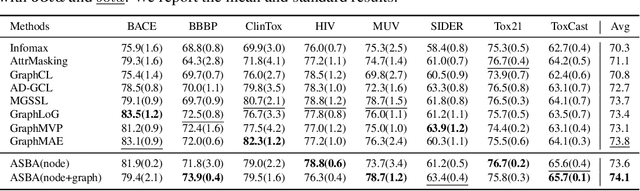
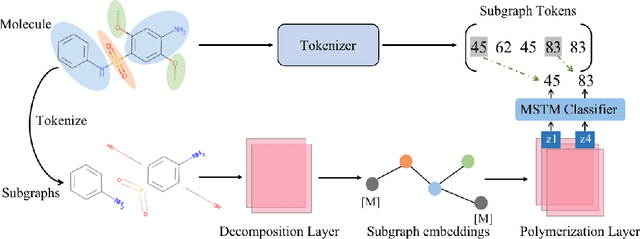
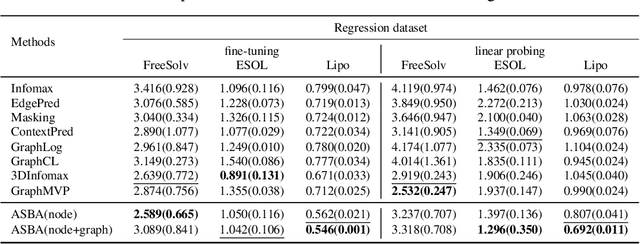
Molecular representation learning is a crucial task in predicting molecular properties. Molecules are often modeled as graphs where atoms and chemical bonds are represented as nodes and edges, respectively, and Graph Neural Networks (GNNs) have been commonly utilized to predict atom-related properties, such as reactivity and solubility. However, functional groups (subgraphs) are closely related to some chemical properties of molecules, such as efficacy, and metabolic properties, which cannot be solely determined by individual atoms. In this paper, we introduce a new model for molecular representation learning called the Atomic and Subgraph-aware Bilateral Aggregation (ASBA), which addresses the limitations of previous atom-wise and subgraph-wise models by incorporating both types of information. ASBA consists of two branches, one for atom-wise information and the other for subgraph-wise information. Considering existing atom-wise GNNs cannot properly extract invariant subgraph features, we propose a decomposition-polymerization GNN architecture for the subgraph-wise branch. Furthermore, we propose cooperative node-level and graph-level self-supervised learning strategies for ASBA to improve its generalization. Our method offers a more comprehensive way to learn representations for molecular property prediction and has broad potential in drug and material discovery applications. Extensive experiments have demonstrated the effectiveness of our method.
A Brief History of Recommender Systems
Sep 05, 2022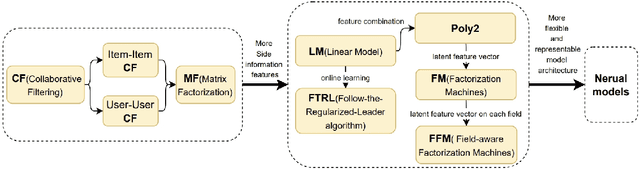
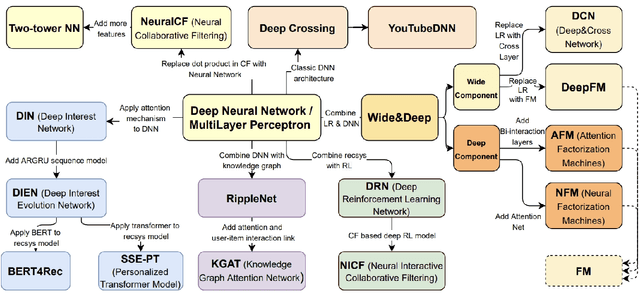
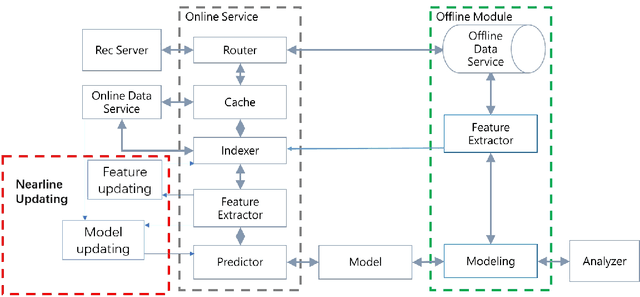
Soon after the invention of the Internet, the recommender system emerged and related technologies have been extensively studied and applied by both academia and industry. Currently, recommender system has become one of the most successful web applications, serving billions of people in each day through recommending different kinds of contents, including news feeds, videos, e-commerce products, music, movies, books, games, friends, jobs etc. These successful stories have proved that recommender system can transfer big data to high values. This article briefly reviews the history of web recommender systems, mainly from two aspects: (1) recommendation models, (2) architectures of typical recommender systems. We hope the brief review can help us to know the dots about the progress of web recommender systems, and the dots will somehow connect in the future, which inspires us to build more advanced recommendation services for changing the world better.
InvisibiliTee: Angle-agnostic Cloaking from Person-Tracking Systems with a Tee
Aug 15, 2022
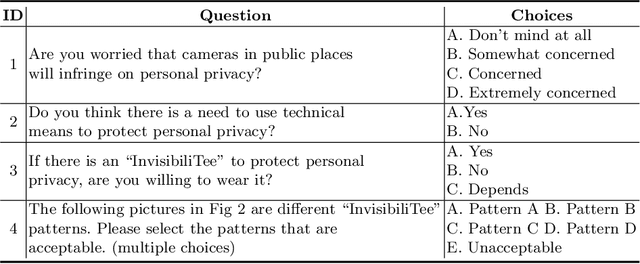


After a survey for person-tracking system-induced privacy concerns, we propose a black-box adversarial attack method on state-of-the-art human detection models called InvisibiliTee. The method learns printable adversarial patterns for T-shirts that cloak wearers in the physical world in front of person-tracking systems. We design an angle-agnostic learning scheme which utilizes segmentation of the fashion dataset and a geometric warping process so the adversarial patterns generated are effective in fooling person detectors from all camera angles and for unseen black-box detection models. Empirical results in both digital and physical environments show that with the InvisibiliTee on, person-tracking systems' ability to detect the wearer drops significantly.
AdarGCN: Adaptive Aggregation GCN for Few-Shot Learning
Mar 09, 2020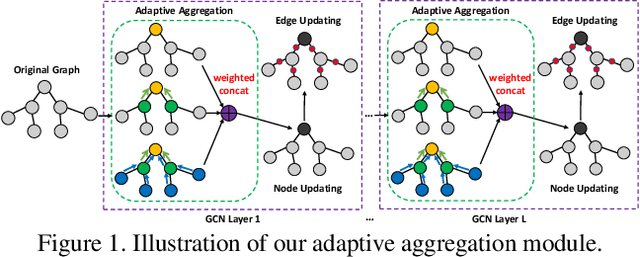
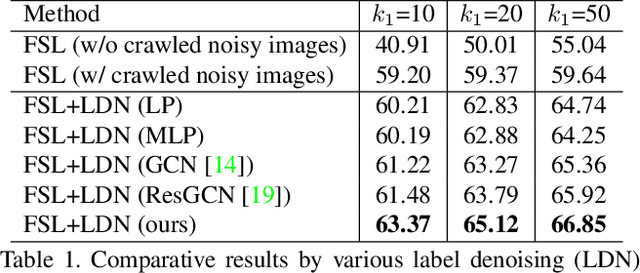
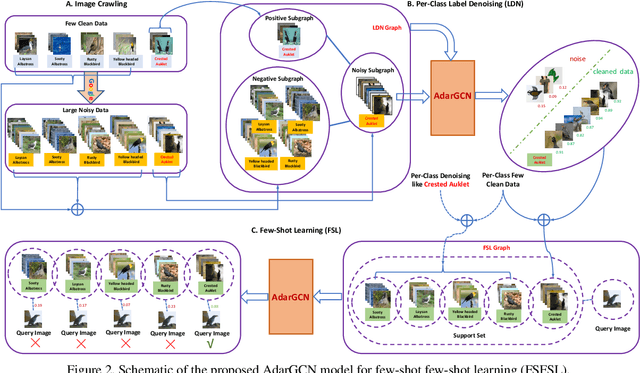
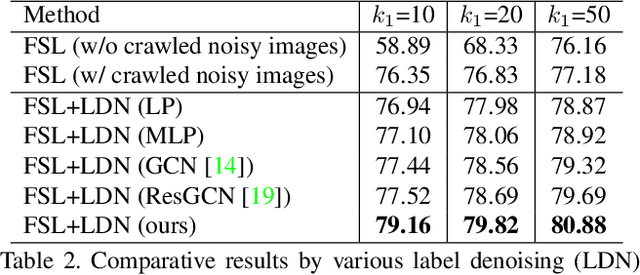
Existing few-shot learning (FSL) methods assume that there exist sufficient training samples from source classes for knowledge transfer to target classes with few training samples. However, this assumption is often invalid, especially when it comes to fine-grained recognition. In this work, we define a new FSL setting termed few-shot fewshot learning (FSFSL), under which both the source and target classes have limited training samples. To overcome the source class data scarcity problem, a natural option is to crawl images from the web with class names as search keywords. However, the crawled images are inevitably corrupted by large amount of noise (irrelevant images) and thus may harm the performance. To address this problem, we propose a graph convolutional network (GCN)-based label denoising (LDN) method to remove the irrelevant images. Further, with the cleaned web images as well as the original clean training images, we propose a GCN-based FSL method. For both the LDN and FSL tasks, a novel adaptive aggregation GCN (AdarGCN) model is proposed, which differs from existing GCN models in that adaptive aggregation is performed based on a multi-head multi-level aggregation module. With AdarGCN, how much and how far information carried by each graph node is propagated in the graph structure can be determined automatically, therefore alleviating the effects of both noisy and outlying training samples. Extensive experiments show the superior performance of our AdarGCN under both the new FSFSL and the conventional FSL settings.
Pre-training of Context-aware Item Representation for Next Basket Recommendation
Apr 14, 2019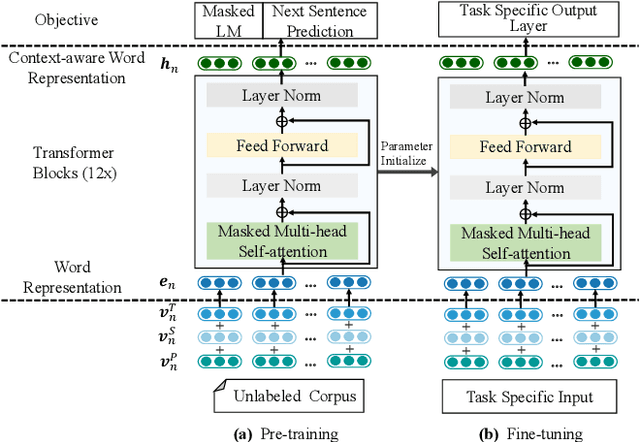
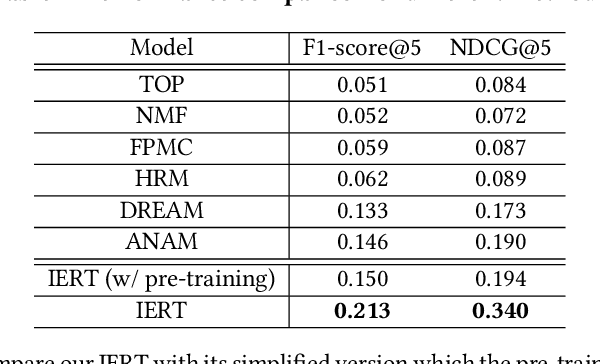
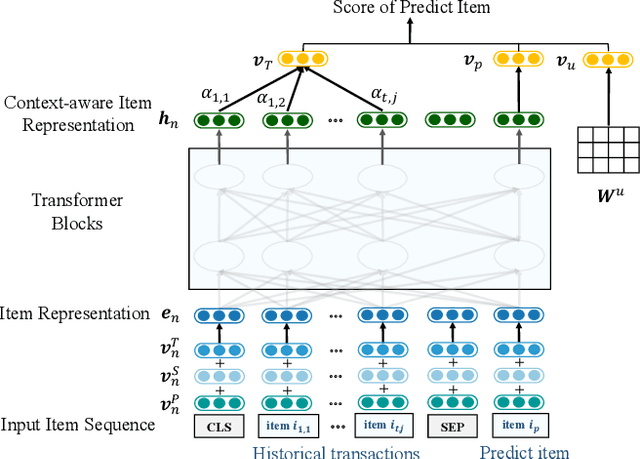
Next basket recommendation, which aims to predict the next a few items that a user most probably purchases given his historical transactions, plays a vital role in market basket analysis. From the viewpoint of item, an item could be purchased by different users together with different items, for different reasons. Therefore, an ideal recommender system should represent an item considering its transaction contexts. Existing state-of-the-art deep learning methods usually adopt the static item representations, which are invariant among all of the transactions and thus cannot achieve the full potentials of deep learning. Inspired by the pre-trained representations of BERT in natural language processing, we propose to conduct context-aware item representation for next basket recommendation, called Item Encoder Representations from Transformers (IERT). In the offline phase, IERT pre-trains deep item representations conditioning on their transaction contexts. In the online recommendation phase, the pre-trained model is further fine-tuned with an additional output layer. The output contextualized item embeddings are used to capture users' sequential behaviors and general tastes to conduct recommendation. Experimental results on the Ta-Feng data set show that IERT outperforms the state-of-the-art baseline methods, which demonstrated the effectiveness of IERT in next basket representation.