 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Apr 03, 2026Robotic manipulation requires understanding both the 3D spatial structure of the environment and its temporal evolution, yet most existing policies overlook one or both. They typically rely on 2D visual observations and backbones pretrained on static image--text pairs, resulting in high data requirements and limited understanding of environment dynamics. To address this, we introduce MV-VDP, a multi-view video diffusion policy that jointly models the 3D spatio-temporal state of the environment. The core idea is to simultaneously predict multi-view heatmap videos and RGB videos, which 1) align the representation format of video pretraining with action finetuning, and 2) specify not only what actions the robot should take, but also how the environment is expected to evolve in response to those actions. Extensive experiments show that MV-VDP enables data-efficient, robust, generalizable, and interpretable manipulation. With only ten demonstration trajectories and without additional pretraining, MV-VDP successfully performs complex real-world tasks, demonstrates strong robustness across a range of model hyperparameters, generalizes to out-of-distribution settings, and predicts realistic future videos. Experiments on Meta-World and real-world robotic platforms demonstrate that MV-VDP consistently outperforms video-prediction--based, 3D-based, and vision--language--action models, establishing a new state of the art in data-efficient multi-task manipulation.
Symbolic Graph Networks for Robust PDE Discovery from Noisy Sparse Data
Mar 23, 2026Data-driven discovery of partial differential equations (PDEs) offers a promising paradigm for uncovering governing physical laws from observational data. However, in practical scenarios, measurements are often contaminated by noise and limited by sparse sampling, which poses significant challenges to existing approaches based on numerical differentiation or integral formulations. In this work, we propose a Symbolic Graph Network (SGN) framework for PDE discovery under noisy and sparse conditions. Instead of relying on local differential approximations, SGN leverages graph message passing to model spatial interactions, providing a non-local representation that is less sensitive to high frequency noise. Based on this representation, the learned latent features are further processed by a symbolic regression module to extract interpretable mathematical expressions. We evaluate the proposed method on several benchmark systems, including the wave equation, convection-diffusion equation, and incompressible Navier-Stokes equations. Experimental results show that SGN can recover meaningful governing relations or solution forms under varying noise levels, and demonstrates improved robustness compared to baseline methods in sparse and noisy settings. These results suggest that combining graph-based representations with symbolic regression provides a viable direction for robust data-driven discovery of physical laws from imperfect observations. The code is available at https://github.com/CXY0112/SGN
Diff-Muscle: Efficient Learning for Musculoskeletal Robotic Table Tennis
Mar 09, 2026Musculoskeletal robots provide superior advantages in flexibility and dexterity, positioning them as a promising frontier towards embodied intelligence. However, current research is largely confined to relative simple tasks, restricting the exploration of their full potential in multi-segment coordination. Furthermore, efficient learning remains a challenge, primarily due to the high-dimensional action space and inherent overactuated structures. To address these challenges, we propose Diff-Muscle, a musculoskeletal robot control algorithm that leverages differential flatness to reformulate policy learning from the redundant muscle-activation space into a significantly lower-dimensional joint space. Furthermore, we utilize the highly dynamic robotic table tennis task to evaluate our algorithm. Specifically, we propose a hierarchical reinforcement learning framework that integrates a Kinematics-based Muscle Actuation Controller (K-MAC) with high-level trajectory planning, enabling a musculoskeletal robot to perform dexterous and precise rallies. Experimental results demonstrate that Diff-Muscle significantly outperforms state-of-the-art baselines in success rates while maintaining minimal muscle activation. Notably, the proposed framework successfully enables the musculoskeletal robots to achieve continuous rallies in a challenging dual-robot setting.
Benchmarking Semantic Segmentation Models via Appearance and Geometry Attribute Editing
Mar 02, 2026Semantic segmentation takes pivotal roles in various applications such as autonomous driving and medical image analysis. When deploying segmentation models in practice, it is critical to test their behaviors in varied and complex scenes in advance. In this paper, we construct an automatic data generation pipeline Gen4Seg to stress-test semantic segmentation models by generating various challenging samples with different attribute changes. Beyond previous evaluation paradigms focusing solely on global weather and style transfer, we investigate variations in both appearance and geometry attributes at the object and image level. These include object color, material, size, position, as well as image-level variations such as weather and style. To achieve this, we propose to edit visual attributes of existing real images with precise control of structural information, empowered by diffusion models. In this way, the existing segmentation labels can be reused for the edited images, which greatly reduces the labor costs. Using our pipeline, we construct two new benchmarks, Pascal-EA and COCO-EA. We benchmark a wide variety of semantic segmentation models, spanning from closed-set models to open-vocabulary large models. We have several key findings: 1) advanced open-vocabulary models do not exhibit greater robustness compared to closed-set methods under geometric variations; 2) data augmentation techniques, such as CutOut and CutMix, are limited in enhancing robustness against appearance variations; 3) our pipeline can also be employed as a data augmentation tool and improve both in-distribution and out-of-distribution performances. Our work suggests the potential of generative models as effective tools for automatically analyzing segmentation models, and we hope our findings will assist practitioners and researchers in developing more robust and reliable segmentation models.
Xiaomi-Robotics-0: An Open-Sourced Vision-Language-Action Model with Real-Time Execution
Feb 13, 2026In this report, we introduce Xiaomi-Robotics-0, an advanced vision-language-action (VLA) model optimized for high performance and fast and smooth real-time execution. The key to our method lies in a carefully designed training recipe and deployment strategy. Xiaomi-Robotics-0 is first pre-trained on large-scale cross-embodiment robot trajectories and vision-language data, endowing it with broad and generalizable action-generation capabilities while avoiding catastrophic forgetting of the visual-semantic knowledge of the underlying pre-trained VLM. During post-training, we propose several techniques for training the VLA model for asynchronous execution to address the inference latency during real-robot rollouts. During deployment, we carefully align the timesteps of consecutive predicted action chunks to ensure continuous and seamless real-time rollouts. We evaluate Xiaomi-Robotics-0 extensively in simulation benchmarks and on two challenging real-robot tasks that require precise and dexterous bimanual manipulation. Results show that our method achieves state-of-the-art performance across all simulation benchmarks. Moreover, Xiaomi-Robotics-0 can roll out fast and smoothly on real robots using a consumer-grade GPU, achieving high success rates and throughput on both real-robot tasks. To facilitate future research, code and model checkpoints are open-sourced at https://xiaomi-robotics-0.github.io
Architecture-Optimization Co-Design for Physics-Informed Neural Networks Via Attentive Representations and Conflict-Resolved Gradients
Jan 19, 2026Physics-Informed Neural Networks (PINNs) provide a learning-based framework for solving partial differential equations (PDEs) by embedding governing physical laws into neural network training. In practice, however, their performance is often hindered by limited representational capacity and optimization difficulties caused by competing physical constraints and conflicting gradients. In this work, we study PINN training from a unified architecture-optimization perspective. We first propose a layer-wise dynamic attention mechanism to enhance representational flexibility, resulting in the Layer-wise Dynamic Attention PINN (LDA-PINN). We then reformulate PINN training as a multi-task learning problem and introduce a conflict-resolved gradient update strategy to alleviate gradient interference, leading to the Gradient-Conflict-Resolved PINN (GC-PINN). By integrating these two components, we develop the Architecture-Conflict-Resolved PINN (ACR-PINN), which combines attentive representations with conflict-aware optimization while preserving the standard PINN loss formulation. Extensive experiments on benchmark PDEs, including the Burgers, Helmholtz, Klein-Gordon, and lid-driven cavity flow problems, demonstrate that ACR-PINN achieves faster convergence and significantly lower relative $L_2$ and $L_\infty$ errors than standard PINNs. These results highlight the effectiveness of architecture-optimization co-design for improving the robustness and accuracy of PINN-based solvers.
OneTrans: Unified Feature Interaction and Sequence Modeling with One Transformer in Industrial Recommender
Oct 30, 2025In recommendation systems, scaling up feature-interaction modules (e.g., Wukong, RankMixer) or user-behavior sequence modules (e.g., LONGER) has achieved notable success. However, these efforts typically proceed on separate tracks, which not only hinders bidirectional information exchange but also prevents unified optimization and scaling. In this paper, we propose OneTrans, a unified Transformer backbone that simultaneously performs user-behavior sequence modeling and feature interaction. OneTrans employs a unified tokenizer to convert both sequential and non-sequential attributes into a single token sequence. The stacked OneTrans blocks share parameters across similar sequential tokens while assigning token-specific parameters to non-sequential tokens. Through causal attention and cross-request KV caching, OneTrans enables precomputation and caching of intermediate representations, significantly reducing computational costs during both training and inference. Experimental results on industrial-scale datasets demonstrate that OneTrans scales efficiently with increasing parameters, consistently outperforms strong baselines, and yields a 5.68% lift in per-user GMV in online A/B tests.
Track Any Motions under Any Disturbances
Sep 17, 2025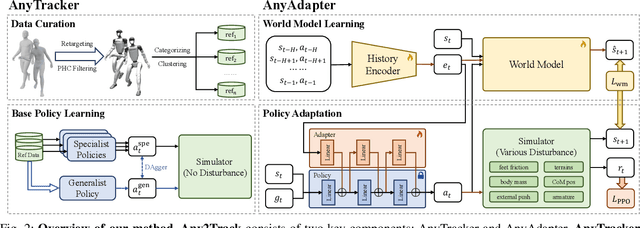

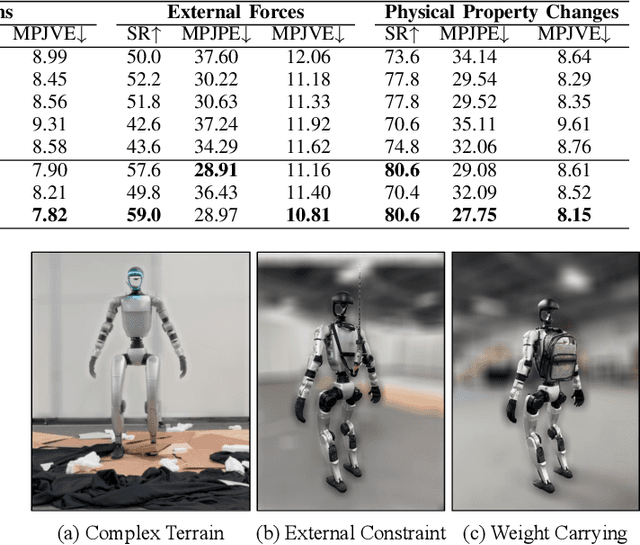

A foundational humanoid motion tracker is expected to be able to track diverse, highly dynamic, and contact-rich motions. More importantly, it needs to operate stably in real-world scenarios against various dynamics disturbances, including terrains, external forces, and physical property changes for general practical use. To achieve this goal, we propose Any2Track (Track Any motions under Any disturbances), a two-stage RL framework to track various motions under multiple disturbances in the real world. Any2Track reformulates dynamics adaptability as an additional capability on top of basic action execution and consists of two key components: AnyTracker and AnyAdapter. AnyTracker is a general motion tracker with a series of careful designs to track various motions within a single policy. AnyAdapter is a history-informed adaptation module that endows the tracker with online dynamics adaptability to overcome the sim2real gap and multiple real-world disturbances. We deploy Any2Track on Unitree G1 hardware and achieve a successful sim2real transfer in a zero-shot manner. Any2Track performs exceptionally well in tracking various motions under multiple real-world disturbances.
Robustness Feature Adapter for Efficient Adversarial Training
Aug 25, 2025Adversarial training (AT) with projected gradient descent is the most popular method to improve model robustness under adversarial attacks. However, computational overheads become prohibitively large when AT is applied to large backbone models. AT is also known to have the issue of robust overfitting. This paper contributes to solving both problems simultaneously towards building more trustworthy foundation models. In particular, we propose a new adapter-based approach for efficient AT directly in the feature space. We show that the proposed adapter-based approach can improve the inner-loop convergence quality by eliminating robust overfitting. As a result, it significantly increases computational efficiency and improves model accuracy by generalizing adversarial robustness to unseen attacks. We demonstrate the effectiveness of the new adapter-based approach in different backbone architectures and in AT at scale.
KG-Augmented Executable CoT for Mathematical Coding
Aug 06, 2025In recent years, large language models (LLMs) have excelled in natural language processing tasks but face significant challenges in complex reasoning tasks such as mathematical reasoning and code generation. To address these limitations, we propose KG-Augmented Executable Chain-of-Thought (KGA-ECoT), a novel framework that enhances code generation through knowledge graphs and improves mathematical reasoning via executable code. KGA-ECoT decomposes problems into a Structured Task Graph, leverages efficient GraphRAG for precise knowledge retrieval from mathematical libraries, and generates verifiable code to ensure computational accuracy. Evaluations on multiple mathematical reasoning benchmarks demonstrate that KGA-ECoT significantly outperforms existing prompting methods, achieving absolute accuracy improvements ranging from several to over ten percentage points. Further analysis confirms the critical roles of GraphRAG in enhancing code quality and external code execution in ensuring precision. These findings collectively establish KGA-ECoT as a robust and highly generalizable framework for complex mathematical reasoning tasks.