 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLo-Token: Input-Adaptive High-Low Frequency Token Compression for Efficient Image Editing
Jun 11, 2026Creative image editing tools, such as Photoshop's Remove or Generative Fill buttons, are central to everyday customer use and account for a major share of traffic in Photoshop and Lightroom. However, current generative AI models face significant latency challenges, which become even more pronounced when transitioning from convolution-based U-Nets to Diffusion Transformers (DiTs). In our evaluation on hundreds of representative image editing samples spanning a wide range of mask ratios, the DiT module alone accounts for an average of 73% of the total model latency, even after being distilled from 50 timesteps down to 8 timesteps. To tackle this challenge, we propose $\textbf{HiLo-Token}$, an input-adaptive token compression framework that allocates more token budget to high-frequency, rich-context regions while assigning fewer tokens to low-frequency areas. Specifically, for the editing region specified by the user mask, we retain all tokens within a dilated mask to preserve strong locality and contextual relevance. Outside the editing region, we introduce a simple yet effective high-frequency token selection strategy based on spatial frequency to capture important local details, while using tokens from a 16x downsampled image to represent low-frequency components and preserve the blurry but global structure. Extensive experiments on production-level evaluation data validate the effectiveness of the proposed method, achieving 3.13x, 2.59x, and 1.67x DiT speedups on A100-80GB for image editing tasks across small, medium, and large mask ratio categories with average ratios of 6.38%, 15.92%, and 35.36%, respectively, without any regression in generation quality.
Symbolic Graph Networks for Robust PDE Discovery from Noisy Sparse Data
Mar 23, 2026Data-driven discovery of partial differential equations (PDEs) offers a promising paradigm for uncovering governing physical laws from observational data. However, in practical scenarios, measurements are often contaminated by noise and limited by sparse sampling, which poses significant challenges to existing approaches based on numerical differentiation or integral formulations. In this work, we propose a Symbolic Graph Network (SGN) framework for PDE discovery under noisy and sparse conditions. Instead of relying on local differential approximations, SGN leverages graph message passing to model spatial interactions, providing a non-local representation that is less sensitive to high frequency noise. Based on this representation, the learned latent features are further processed by a symbolic regression module to extract interpretable mathematical expressions. We evaluate the proposed method on several benchmark systems, including the wave equation, convection-diffusion equation, and incompressible Navier-Stokes equations. Experimental results show that SGN can recover meaningful governing relations or solution forms under varying noise levels, and demonstrates improved robustness compared to baseline methods in sparse and noisy settings. These results suggest that combining graph-based representations with symbolic regression provides a viable direction for robust data-driven discovery of physical laws from imperfect observations. The code is available at https://github.com/CXY0112/SGN
Tri-Prompting: Video Diffusion with Unified Control over Scene, Subject, and Motion
Mar 16, 2026Recent video diffusion models have made remarkable strides in visual quality, yet precise, fine-grained control remains a key bottleneck that limits practical customizability for content creation. For AI video creators, three forms of control are crucial: (i) scene composition, (ii) multi-view consistent subject customization, and (iii) camera-pose or object-motion adjustment. Existing methods typically handle these dimensions in isolation, with limited support for multi-view subject synthesis and identity preservation under arbitrary pose changes. This lack of a unified architecture makes it difficult to support versatile, jointly controllable video. We introduce Tri-Prompting, a unified framework and two-stage training paradigm that integrates scene composition, multi-view subject consistency, and motion control. Our approach leverages a dual-condition motion module driven by 3D tracking points for background scenes and downsampled RGB cues for foreground subjects. To ensure a balance between controllability and visual realism, we further propose an inference ControlNet scale schedule. Tri-Prompting supports novel workflows, including 3D-aware subject insertion into any scenes and manipulation of existing subjects in an image. Experimental results demonstrate that Tri-Prompting significantly outperforms specialized baselines such as Phantom and DaS in multi-view subject identity, 3D consistency, and motion accuracy.
Rethinking Global Text Conditioning in Diffusion Transformers
Feb 09, 2026Diffusion transformers typically incorporate textual information via attention layers and a modulation mechanism using a pooled text embedding. Nevertheless, recent approaches discard modulation-based text conditioning and rely exclusively on attention. In this paper, we address whether modulation-based text conditioning is necessary and whether it can provide any performance advantage. Our analysis shows that, in its conventional usage, the pooled embedding contributes little to overall performance, suggesting that attention alone is generally sufficient for faithfully propagating prompt information. However, we reveal that the pooled embedding can provide significant gains when used from a different perspective-serving as guidance and enabling controllable shifts toward more desirable properties. This approach is training-free, simple to implement, incurs negligible runtime overhead, and can be applied to various diffusion models, bringing improvements across diverse tasks, including text-to-image/video generation and image editing.
Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
UniSER: A Foundation Model for Unified Soft Effects Removal
Nov 18, 2025Digital images are often degraded by soft effects such as lens flare, haze, shadows, and reflections, which reduce aesthetics even though the underlying pixels remain partially visible. The prevailing works address these degradations in isolation, developing highly specialized, specialist models that lack scalability and fail to exploit the shared underlying essences of these restoration problems. While specialist models are limited, recent large-scale pretrained generalist models offer powerful, text-driven image editing capabilities. while recent general-purpose systems (e.g., GPT-4o, Flux Kontext, Nano Banana) require detailed prompts and often fail to achieve robust removal on these fine-grained tasks or preserve identity of the scene. Leveraging the common essence of soft effects, i.e., semi-transparent occlusions, we introduce a foundational versatile model UniSER, capable of addressing diverse degradations caused by soft effects within a single framework. Our methodology centers on curating a massive 3.8M-pair dataset to ensure robustness and generalization, which includes novel, physically-plausible data to fill critical gaps in public benchmarks, and a tailored training pipeline that fine-tunes a Diffusion Transformer to learn robust restoration priors from this diverse data, integrating fine-grained mask and strength controls. This synergistic approach allows UniSER to significantly outperform both specialist and generalist models, achieving robust, high-fidelity restoration in the wild.
ZipIR: Latent Pyramid Diffusion Transformer for High-Resolution Image Restoration
Apr 11, 2025Recent progress in generative models has significantly improved image restoration capabilities, particularly through powerful diffusion models that offer remarkable recovery of semantic details and local fidelity. However, deploying these models at ultra-high resolutions faces a critical trade-off between quality and efficiency due to the computational demands of long-range attention mechanisms. To address this, we introduce ZipIR, a novel framework that enhances efficiency, scalability, and long-range modeling for high-res image restoration. ZipIR employs a highly compressed latent representation that compresses image 32x, effectively reducing the number of spatial tokens, and enabling the use of high-capacity models like the Diffusion Transformer (DiT). Toward this goal, we propose a Latent Pyramid VAE (LP-VAE) design that structures the latent space into sub-bands to ease diffusion training. Trained on full images up to 2K resolution, ZipIR surpasses existing diffusion-based methods, offering unmatched speed and quality in restoring high-resolution images from severely degraded inputs.
TurboFill: Adapting Few-step Text-to-image Model for Fast Image Inpainting
Apr 01, 2025This paper introduces TurboFill, a fast image inpainting model that enhances a few-step text-to-image diffusion model with an inpainting adapter for high-quality and efficient inpainting. While standard diffusion models generate high-quality results, they incur high computational costs. We overcome this by training an inpainting adapter on a few-step distilled text-to-image model, DMD2, using a novel 3-step adversarial training scheme to ensure realistic, structurally consistent, and visually harmonious inpainted regions. To evaluate TurboFill, we propose two benchmarks: DilationBench, which tests performance across mask sizes, and HumanBench, based on human feedback for complex prompts. Experiments show that TurboFill outperforms both multi-step BrushNet and few-step inpainting methods, setting a new benchmark for high-performance inpainting tasks. Our project page: https://liangbinxie.github.io/projects/TurboFill/
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024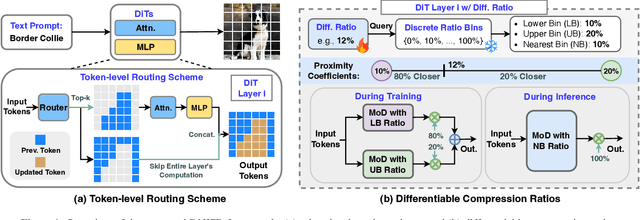



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
UniReal: Universal Image Generation and Editing via Learning Real-world Dynamics
Dec 10, 2024



We introduce UniReal, a unified framework designed to address various image generation and editing tasks. Existing solutions often vary by tasks, yet share fundamental principles: preserving consistency between inputs and outputs while capturing visual variations. Inspired by recent video generation models that effectively balance consistency and variation across frames, we propose a unifying approach that treats image-level tasks as discontinuous video generation. Specifically, we treat varying numbers of input and output images as frames, enabling seamless support for tasks such as image generation, editing, customization, composition, etc. Although designed for image-level tasks, we leverage videos as a scalable source for universal supervision. UniReal learns world dynamics from large-scale videos, demonstrating advanced capability in handling shadows, reflections, pose variation, and object interaction, while also exhibiting emergent capability for novel applications.