 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLo-Token: Input-Adaptive High-Low Frequency Token Compression for Efficient Image Editing
Jun 11, 2026Creative image editing tools, such as Photoshop's Remove or Generative Fill buttons, are central to everyday customer use and account for a major share of traffic in Photoshop and Lightroom. However, current generative AI models face significant latency challenges, which become even more pronounced when transitioning from convolution-based U-Nets to Diffusion Transformers (DiTs). In our evaluation on hundreds of representative image editing samples spanning a wide range of mask ratios, the DiT module alone accounts for an average of 73% of the total model latency, even after being distilled from 50 timesteps down to 8 timesteps. To tackle this challenge, we propose $\textbf{HiLo-Token}$, an input-adaptive token compression framework that allocates more token budget to high-frequency, rich-context regions while assigning fewer tokens to low-frequency areas. Specifically, for the editing region specified by the user mask, we retain all tokens within a dilated mask to preserve strong locality and contextual relevance. Outside the editing region, we introduce a simple yet effective high-frequency token selection strategy based on spatial frequency to capture important local details, while using tokens from a 16x downsampled image to represent low-frequency components and preserve the blurry but global structure. Extensive experiments on production-level evaluation data validate the effectiveness of the proposed method, achieving 3.13x, 2.59x, and 1.67x DiT speedups on A100-80GB for image editing tasks across small, medium, and large mask ratio categories with average ratios of 6.38%, 15.92%, and 35.36%, respectively, without any regression in generation quality.
Complete-muE: Optimal Hyperparameter Transfer and Scaling for MoE Models
May 22, 2026We propose Complete-muE, a framework which targets hyperparameter transfer across dense FFN and any Mixture-of-Experts (MoE) setups in transformer blocks. Existing tools such as $μ$P (requires fixed architectue) or SDE (requires fixed per-step token count) cannot directly solve the hyperparameter transfer problem in MoE setups because Dense to MoE transfer or MoE total experts scaling changes both architecture and tokens per expert. Complete-muE solves this challenge with a two-bridge system: Bridge~I maps between dense FFN and Dense MoE by active-width $μ$P with a normalized router scale. Bridge~II maps between Dense MoE and sparse MoE by activated-expert scaling, where the first-order SDE LR/WD correction cancels while a bounded residual $σ_0$ shift remains. The resulting transfer rule, which we term as Complete muE, covers changes in activated experts, total capacity, granularity, and shared/group-balanced hybrids for MoE models as well as network width/depth, batch size, and duration changes for general Transformer models. Extensive language model and diffusion model pretraining experiments confirm that complete-muE yields relatively stable hyperparameter optima across model architectures and parameter counts -- with only minor drift consistent with the non-strict SDE behavior of Bridge~II. In practice this drift is small enough that hyperparameters tuned on a single dense reference transfer near-optimally to all MoE configurations -- \emph{tune dense once, transfer to all} is the practical recipe at the core of Complete-muE. This enables MoE models to achieve accelerated convergence speedup over dense models when scaling model capacity without costly hyperparameter search.
Sparsity-Controllable Dynamic Top-p MoE for Large Foundation Model Pre-training
Dec 16, 2025Sparse Mixture-of-Experts (MoE) architectures effectively scale model capacity by activating only a subset of experts for each input token. However, the standard Top-k routing strategy imposes a uniform sparsity pattern that ignores the varying difficulty of tokens. While Top-p routing offers a flexible alternative, existing implementations typically rely on a fixed global probability threshold, which results in uncontrolled computational costs and sensitivity to hyperparameter selection. In this paper, we propose DTop-p MoE, a sparsity-controllable dynamic Top-p routing mechanism. To resolve the challenge of optimizing a non-differentiable threshold, we utilize a Proportional-Integral (PI) Controller that dynamically adjusts the probability threshold to align the running activated-expert sparsity with a specified target. Furthermore, we introduce a dynamic routing normalization mechanism that adapts layer-wise routing logits, allowing different layers to learn distinct expert-selection patterns while utilizing a global probability threshold. Extensive experiments on Large Language Models and Diffusion Transformers demonstrate that DTop-p consistently outperforms both Top-k and fixed-threshold Top-p baselines. Our analysis confirms that DTop-p maintains precise control over the number of activated experts while adaptively allocating resources across different tokens and layers. Furthermore, DTop-p exhibits strong scaling properties with respect to expert granularity, expert capacity, model size, and dataset size, offering a robust framework for large-scale MoE pre-training.
Layer- and Timestep-Adaptive Differentiable Token Compression Ratios for Efficient Diffusion Transformers
Dec 22, 2024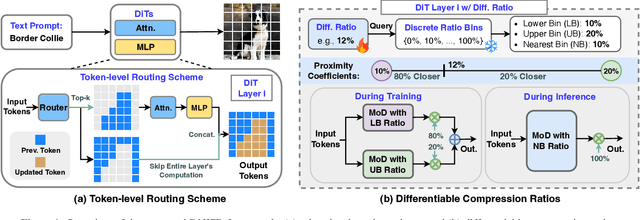



Diffusion Transformers (DiTs) have achieved state-of-the-art (SOTA) image generation quality but suffer from high latency and memory inefficiency, making them difficult to deploy on resource-constrained devices. One key efficiency bottleneck is that existing DiTs apply equal computation across all regions of an image. However, not all image tokens are equally important, and certain localized areas require more computation, such as objects. To address this, we propose DiffRatio-MoD, a dynamic DiT inference framework with differentiable compression ratios, which automatically learns to dynamically route computation across layers and timesteps for each image token, resulting in Mixture-of-Depths (MoD) efficient DiT models. Specifically, DiffRatio-MoD integrates three features: (1) A token-level routing scheme where each DiT layer includes a router that is jointly fine-tuned with model weights to predict token importance scores. In this way, unimportant tokens bypass the entire layer's computation; (2) A layer-wise differentiable ratio mechanism where different DiT layers automatically learn varying compression ratios from a zero initialization, resulting in large compression ratios in redundant layers while others remain less compressed or even uncompressed; (3) A timestep-wise differentiable ratio mechanism where each denoising timestep learns its own compression ratio. The resulting pattern shows higher ratios for noisier timesteps and lower ratios as the image becomes clearer. Extensive experiments on both text-to-image and inpainting tasks show that DiffRatio-MoD effectively captures dynamism across token, layer, and timestep axes, achieving superior trade-offs between generation quality and efficiency compared to prior works.
DOLLAR: Few-Step Video Generation via Distillation and Latent Reward Optimization
Dec 20, 2024Diffusion probabilistic models have shown significant progress in video generation; however, their computational efficiency is limited by the large number of sampling steps required. Reducing sampling steps often compromises video quality or generation diversity. In this work, we introduce a distillation method that combines variational score distillation and consistency distillation to achieve few-step video generation, maintaining both high quality and diversity. We also propose a latent reward model fine-tuning approach to further enhance video generation performance according to any specified reward metric. This approach reduces memory usage and does not require the reward to be differentiable. Our method demonstrates state-of-the-art performance in few-step generation for 10-second videos (128 frames at 12 FPS). The distilled student model achieves a score of 82.57 on VBench, surpassing the teacher model as well as baseline models Gen-3, T2V-Turbo, and Kling. One-step distillation accelerates the teacher model's diffusion sampling by up to 278.6 times, enabling near real-time generation. Human evaluations further validate the superior performance of our 4-step student models compared to teacher model using 50-step DDIM sampling.
FedCoLLM: A Parameter-Efficient Federated Co-tuning Framework for Large and Small Language Models
Nov 18, 2024


By adapting Large Language Models (LLMs) to domain-specific tasks or enriching them with domain-specific knowledge, we can fully harness the capabilities of LLMs. Nonetheless, a gap persists in achieving simultaneous mutual enhancement between the server's LLM and the downstream clients' Small Language Models (SLMs). To address this, we propose FedCoLLM, a novel and parameter-efficient federated framework designed for co-tuning LLMs and SLMs. This approach is aimed at adaptively transferring server-side LLMs knowledge to clients' SLMs while simultaneously enriching the LLMs with domain insights from the clients. To accomplish this, FedCoLLM utilizes lightweight adapters in conjunction with SLMs, facilitating knowledge exchange between server and clients in a manner that respects data privacy while also minimizing computational and communication overhead. Our evaluation of FedCoLLM, utilizing various public LLMs and SLMs across a range of NLP text generation tasks, reveals that the performance of clients' SLMs experiences notable improvements with the assistance of the LLMs. Simultaneously, the LLMs enhanced via FedCoLLM achieves comparable performance to that obtained through direct fine-tuning on clients' data.
Personalized Federated Continual Learning via Multi-granularity Prompt
Jun 27, 2024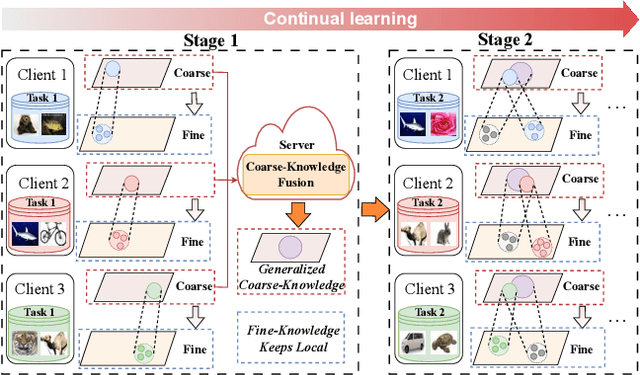

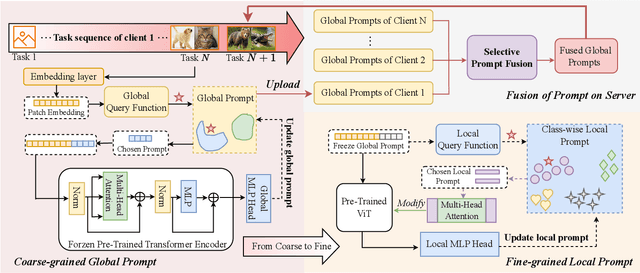

Personalized Federated Continual Learning (PFCL) is a new practical scenario that poses greater challenges in sharing and personalizing knowledge. PFCL not only relies on knowledge fusion for server aggregation at the global spatial-temporal perspective but also needs model improvement for each client according to the local requirements. Existing methods, whether in Personalized Federated Learning (PFL) or Federated Continual Learning (FCL), have overlooked the multi-granularity representation of knowledge, which can be utilized to overcome Spatial-Temporal Catastrophic Forgetting (STCF) and adopt generalized knowledge to itself by coarse-to-fine human cognitive mechanisms. Moreover, it allows more effectively to personalized shared knowledge, thus serving its own purpose. To this end, we propose a novel concept called multi-granularity prompt, i.e., coarse-grained global prompt acquired through the common model learning process, and fine-grained local prompt used to personalize the generalized representation. The former focuses on efficiently transferring shared global knowledge without spatial forgetting, and the latter emphasizes specific learning of personalized local knowledge to overcome temporal forgetting. In addition, we design a selective prompt fusion mechanism for aggregating knowledge of global prompts distilled from different clients. By the exclusive fusion of coarse-grained knowledge, we achieve the transmission and refinement of common knowledge among clients, further enhancing the performance of personalization. Extensive experiments demonstrate the effectiveness of the proposed method in addressing STCF as well as improving personalized performance. Our code now is available at https://github.com/SkyOfBeginning/FedMGP.
PDSS: A Privacy-Preserving Framework for Step-by-Step Distillation of Large Language Models
Jun 18, 2024



In the context of real-world applications, leveraging large language models (LLMs) for domain-specific tasks often faces two major challenges: domain-specific knowledge privacy and constrained resources. To address these issues, we propose PDSS, a privacy-preserving framework for step-by-step distillation of LLMs. PDSS works on a server-client architecture, wherein client transmits perturbed prompts to the server's LLM for rationale generation. The generated rationales are then decoded by the client and used to enrich the training of task-specific small language model(SLM) within a multi-task learning paradigm. PDSS introduces two privacy protection strategies: the Exponential Mechanism Strategy and the Encoder-Decoder Strategy, balancing prompt privacy and rationale usability. Experiments demonstrate the effectiveness of PDSS in various text generation tasks, enabling the training of task-specific SLM with enhanced performance while prioritizing data privacy protection.
FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
Jun 04, 2024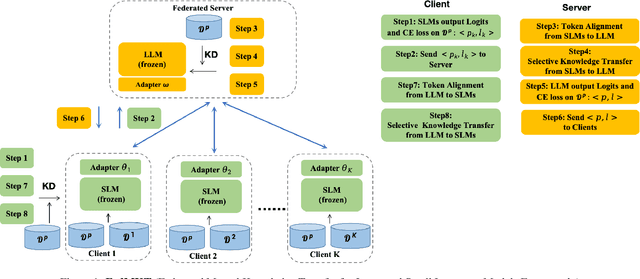
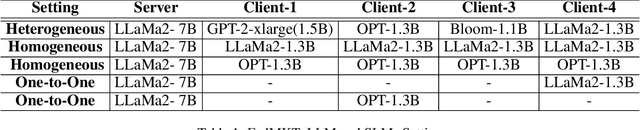

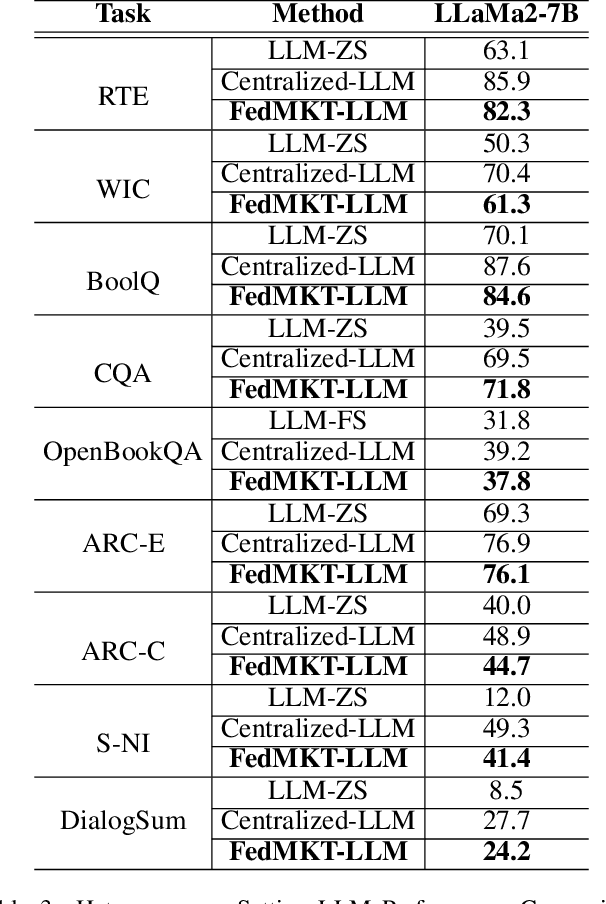
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, heterogeneous, homogeneous, and one-to-one, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate significant performance improvements in clients' SLMs with the aid of the LLM. Furthermore, the LLM optimized by FedMKT achieves a performance comparable to that achieved through direct fine-tuning based on clients' data, highlighting the effectiveness and adaptability of FedMKT.
FedAdOb: Privacy-Preserving Federated Deep Learning with Adaptive Obfuscation
Jun 03, 2024Federated learning (FL) has emerged as a collaborative approach that allows multiple clients to jointly learn a machine learning model without sharing their private data. The concern about privacy leakage, albeit demonstrated under specific conditions, has triggered numerous follow-up research in designing powerful attacking methods and effective defending mechanisms aiming to thwart these attacking methods. Nevertheless, privacy-preserving mechanisms employed in these defending methods invariably lead to compromised model performances due to a fixed obfuscation applied to private data or gradients. In this article, we, therefore, propose a novel adaptive obfuscation mechanism, coined FedAdOb, to protect private data without yielding original model performances. Technically, FedAdOb utilizes passport-based adaptive obfuscation to ensure data privacy in both horizontal and vertical federated learning settings. The privacy-preserving capabilities of FedAdOb, specifically with regard to private features and labels, are theoretically proven through Theorems 1 and 2. Furthermore, extensive experimental evaluations conducted on various datasets and network architectures demonstrate the effectiveness of FedAdOb by manifesting its superior trade-off between privacy preservation and model performance, surpassing existing methods.