 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc-V*:Coarse-to-Fine Interactive Visual Reasoning for Multi-Page Document VQA
Apr 15, 2026Multi-page Document Visual Question Answering requires reasoning over semantics, layouts, and visual elements in long, visually dense documents. Existing OCR-free methods face a trade-off between capacity and precision: end-to-end models scale poorly with document length, while visual retrieval-based pipelines are brittle and passive. We propose Doc-$V^*$, an \textbf{OCR-free agentic} framework that casts multi-page DocVQA as sequential evidence aggregation. Doc-$V^*$ begins with a thumbnail overview, then actively navigates via semantic retrieval and targeted page fetching, and aggregates evidence in a structured working memory for grounded reasoning. Trained by imitation learning from expert trajectories and further optimized with Group Relative Policy Optimization, Doc-$V^*$ balances answer accuracy with evidence-seeking efficiency. Across five benchmarks, Doc-$V^*$ outperforms open-source baselines and approaches proprietary models, improving out-of-domain performance by up to \textbf{47.9\%} over RAG baseline. Other results reveal effective evidence aggregation with selective attention, not increased input pages.
KVSmooth: Mitigating Hallucination in Multi-modal Large Language Models through Key-Value Smoothing
Feb 04, 2026Despite the significant progress of Multimodal Large Language Models (MLLMs) across diverse tasks, hallucination -- corresponding to the generation of visually inconsistent objects, attributes, or relations -- remains a major obstacle to their reliable deployment. Unlike pure language models, MLLMs must ground their generation process in visual inputs. However, existing models often suffer from semantic drift during decoding, causing outputs to diverge from visual facts as the sequence length increases. To address this issue, we propose KVSmooth, a training-free and plug-and-play method that mitigates hallucination by performing attention-entropy-guided adaptive smoothing on hidden states. Specifically, KVSmooth applies an exponential moving average (EMA) to both keys and values in the KV-Cache, while dynamically quantifying the sink degree of each token through the entropy of its attention distribution to adaptively adjust the smoothing strength. Unlike computationally expensive retraining or contrastive decoding methods, KVSmooth operates efficiently during inference without additional training or model modification. Extensive experiments demonstrate that KVSmooth significantly reduces hallucination ($\mathit{CHAIR}_{S}$ from $41.8 \rightarrow 18.2$) while improving overall performance ($F_1$ score from $77.5 \rightarrow 79.2$), achieving higher precision and recall simultaneously. In contrast, prior methods often improve one at the expense of the other, validating the effectiveness and generality of our approach.
Perturbation-Induced Linearization: Constructing Unlearnable Data with Solely Linear Classifiers
Jan 29, 2026Collecting web data to train deep models has become increasingly common, raising concerns about unauthorized data usage. To mitigate this issue, unlearnable examples introduce imperceptible perturbations into data, preventing models from learning effectively. However, existing methods typically rely on deep neural networks as surrogate models for perturbation generation, resulting in significant computational costs. In this work, we propose Perturbation-Induced Linearization (PIL), a computationally efficient yet effective method that generates perturbations using only linear surrogate models. PIL achieves comparable or better performance than existing surrogate-based methods while reducing computational time dramatically. We further reveal a key mechanism underlying unlearnable examples: inducing linearization to deep models, which explains why PIL can achieve competitive results in a very short time. Beyond this, we provide an analysis about the property of unlearnable examples under percentage-based partial perturbation. Our work not only provides a practical approach for data protection but also offers insights into what makes unlearnable examples effective.
FedSDAF: Leveraging Source Domain Awareness for Enhanced Federated Domain Generalization
May 05, 2025Traditional domain generalization approaches predominantly focus on leveraging target domain-aware features while overlooking the critical role of source domain-specific characteristics, particularly in federated settings with inherent data isolation. To address this gap, we propose the Federated Source Domain Awareness Framework (FedSDAF), the first method to systematically exploit source domain-aware features for enhanced federated domain generalization (FedDG). The FedSDAF framework consists of two synergistic components: the Domain-Invariant Adapter, which preserves critical domain-invariant features, and the Domain-Aware Adapter, which extracts and integrates source domain-specific knowledge using a Multihead Self-Attention mechanism (MHSA). Furthermore, we introduce a bidirectional knowledge distillation mechanism that fosters knowledge sharing among clients while safeguarding privacy. Our approach represents the first systematic exploitation of source domain-aware features, resulting in significant advancements in model generalization capability.Extensive experiments on four standard benchmarks (OfficeHome, PACS, VLCS, and DomainNet) show that our method consistently surpasses state-of-the-art federated domain generalization approaches, with accuracy gains of 5.2-13.8%. The source code is available at https://github.com/pizzareapers/FedSDAF.
FedEM: A Privacy-Preserving Framework for Concurrent Utility Preservation in Federated Learning
Mar 08, 2025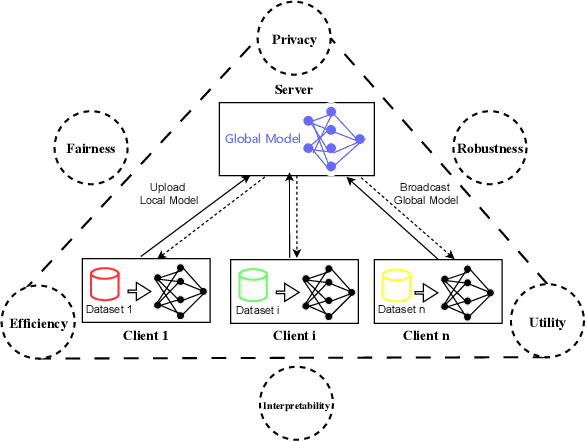
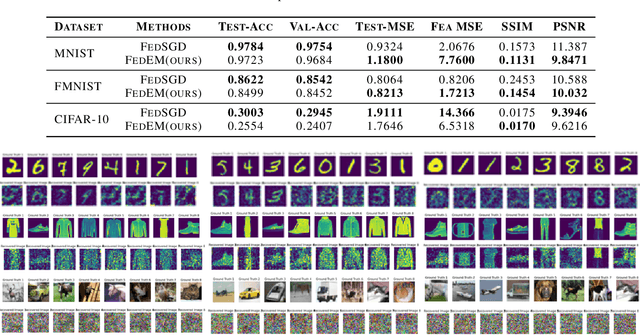
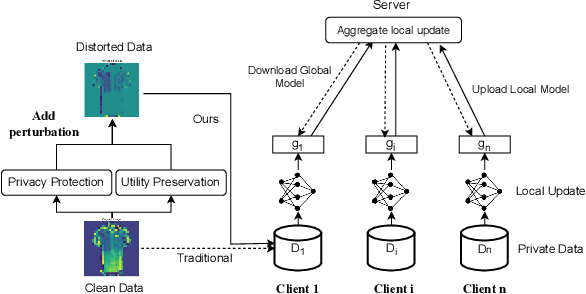
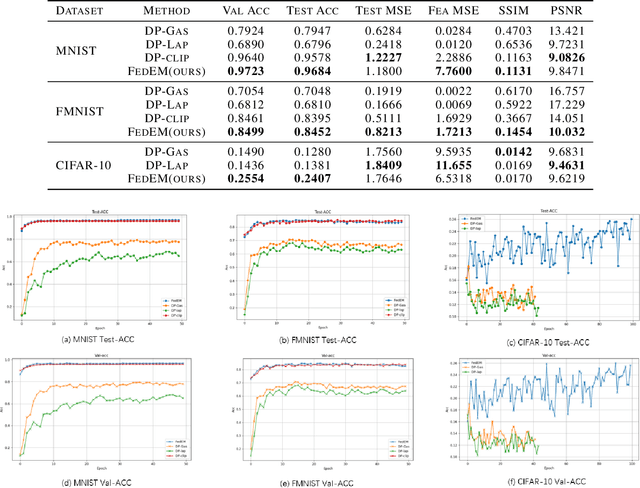
Federated Learning (FL) enables collaborative training of models across distributed clients without sharing local data, addressing privacy concerns in decentralized systems. However, the gradient-sharing process exposes private data to potential leakage, compromising FL's privacy guarantees in real-world applications. To address this issue, we propose Federated Error Minimization (FedEM), a novel algorithm that incorporates controlled perturbations through adaptive noise injection. This mechanism effectively mitigates gradient leakage attacks while maintaining model performance. Experimental results on benchmark datasets demonstrate that FedEM significantly reduces privacy risks and preserves model accuracy, achieving a robust balance between privacy protection and utility preservation.
FedEAT: A Robustness Optimization Framework for Federated LLMs
Feb 17, 2025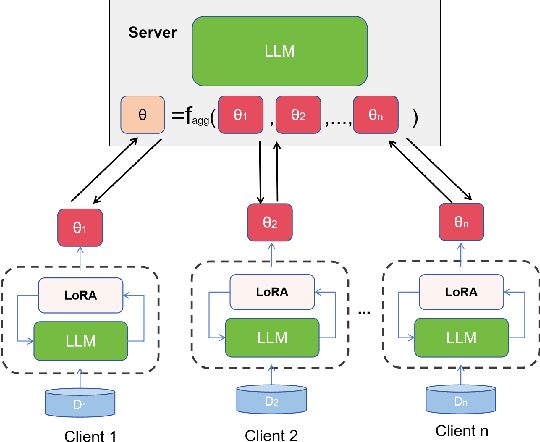
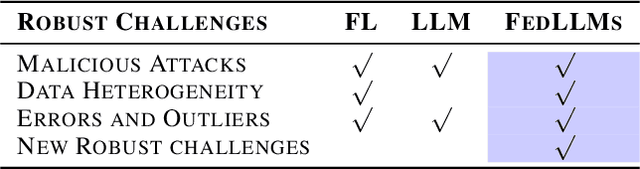
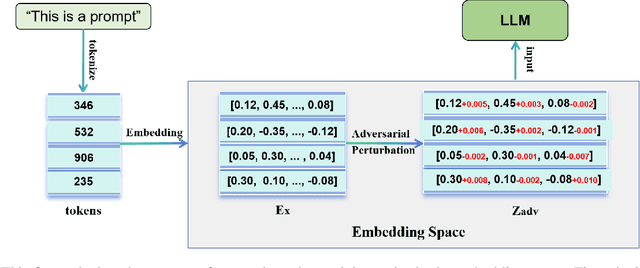
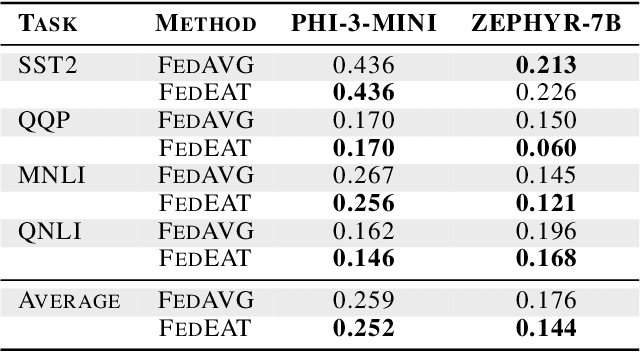
Significant advancements have been made by Large Language Models (LLMs) in the domains of natural language understanding and automated content creation. However, they still face persistent problems, including substantial computational costs and inadequate availability of training data. The combination of Federated Learning (FL) and LLMs (federated LLMs) offers a solution by leveraging distributed data while protecting privacy, which positions it as an ideal choice for sensitive domains. However, Federated LLMs still suffer from robustness challenges, including data heterogeneity, malicious clients, and adversarial attacks, which greatly hinder their applications. We first introduce the robustness problems in federated LLMs, to address these challenges, we propose FedEAT (Federated Embedding space Adversarial Training), a novel framework that applies adversarial training in the embedding space of client LLM and employs a robust aggregation approach, specifically geometric median aggregation, to enhance the robustness of Federated LLMs. Our experiments demonstrate that FedEAT effectively improves the robustness of Federated LLMs with minimal performance loss.
InsQABench: Benchmarking Chinese Insurance Domain Question Answering with Large Language Models
Jan 19, 2025The application of large language models (LLMs) has achieved remarkable success in various fields, but their effectiveness in specialized domains like the Chinese insurance industry remains underexplored. The complexity of insurance knowledge, encompassing specialized terminology and diverse data types, poses significant challenges for both models and users. To address this, we introduce InsQABench, a benchmark dataset for the Chinese insurance sector, structured into three categories: Insurance Commonsense Knowledge, Insurance Structured Database, and Insurance Unstructured Documents, reflecting real-world insurance question-answering tasks.We also propose two methods, SQL-ReAct and RAG-ReAct, to tackle challenges in structured and unstructured data tasks. Evaluations show that while LLMs struggle with domain-specific terminology and nuanced clause texts, fine-tuning on InsQABench significantly improves performance. Our benchmark establishes a solid foundation for advancing LLM applications in the insurance domain, with data and code available at https://github.com/HaileyFamo/InsQABench.git.
Do Current Video LLMs Have Strong OCR Abilities? A Preliminary Study
Dec 29, 2024



With the rise of multimodal large language models, accurately extracting and understanding textual information from video content, referred to as video based optical character recognition (Video OCR), has become a crucial capability. This paper introduces a novel benchmark designed to evaluate the video OCR performance of multi-modal models in videos. Comprising 1,028 videos and 2,961 question-answer pairs, this benchmark proposes several key challenges through 6 distinct subtasks: (1) Recognition of text content itself and its basic visual attributes, (2)Semantic and Spatial Comprehension of OCR objects in videos (3) Dynamic Motion detection and Temporal Localization. We developed this benchmark using a semi-automated approach that integrates the OCR ability of image LLMs with manual refinement, balancing efficiency, cost, and data quality. Our resource aims to help advance research in video LLMs and underscores the need for improving OCR ability for video LLMs. The benchmark will be released on https://github.com/YuHuiGao/FG-Bench.git.
RSL-SQL: Robust Schema Linking in Text-to-SQL Generation
Oct 31, 2024



Text-to-SQL generation aims to translate natural language questions into SQL statements. In large language models (LLMs) based Text-to-SQL, schema linking is a widely adopted strategy to streamline the input for LLMs by selecting only relevant schema elements, therefore reducing noise and computational overhead. However, schema linking faces risks that requires caution, including the potential omission of necessary elements and disruption of database structural integrity. To address these challenges, we propose a novel framework called RSL-SQL that combines bidirectional schema linking, contextual information augmentation, binary selection strategy, and multi-turn self-correction. Our approach improves the recall of schema linking through forward and backward pruning and hedges the risk by voting between full schema and contextual information augmented simplified schema. Experiments on the BIRD and Spider benchmarks demonstrate that our approach achieves state-of-the-art execution accuracy among open-source solutions, with 67.2% on BIRD and 87.9% on Spider using GPT-4o. Furthermore, our approach outperforms a series of GPT-4 based Text-to-SQL systems when adopting DeepSeek (much cheaper) with same intact prompts. Extensive analysis and ablation studies confirm the effectiveness of each component in our framework. The codes are available at https://github.com/Laqcce-cao/RSL-SQL.
MC-CoT: A Modular Collaborative CoT Framework for Zero-shot Medical-VQA with LLM and MLLM Integration
Oct 06, 2024



In recent advancements, multimodal large language models (MLLMs) have been fine-tuned on specific medical image datasets to address medical visual question answering (Med-VQA) tasks. However, this common approach of task-specific fine-tuning is costly and necessitates separate models for each downstream task, limiting the exploration of zero-shot capabilities. In this paper, we introduce MC-CoT, a modular cross-modal collaboration Chain-of-Thought (CoT) framework designed to enhance the zero-shot performance of MLLMs in Med-VQA by leveraging large language models (LLMs). MC-CoT improves reasoning and information extraction by integrating medical knowledge and task-specific guidance, where LLM provides various complex medical reasoning chains and MLLM provides various observations of medical images based on instructions of the LLM. Our experiments on datasets such as SLAKE, VQA-RAD, and PATH-VQA show that MC-CoT surpasses standalone MLLMs and various multimodality CoT frameworks in recall rate and accuracy. These findings highlight the importance of incorporating background information and detailed guidance in addressing complex zero-shot Med-VQA tasks.