 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedEM: A Privacy-Preserving Framework for Concurrent Utility Preservation in Federated Learning
Mar 08, 2025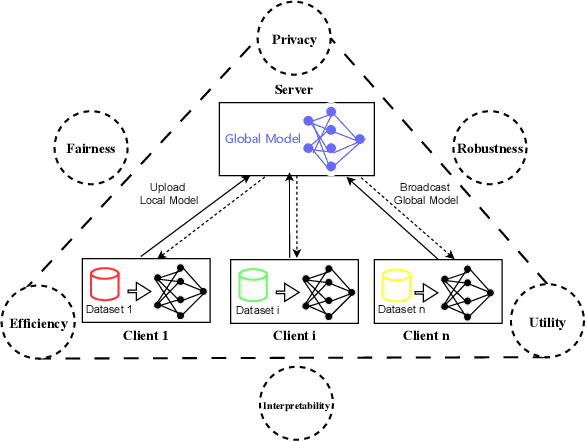
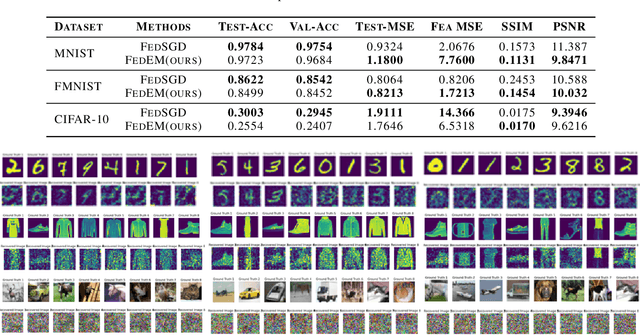
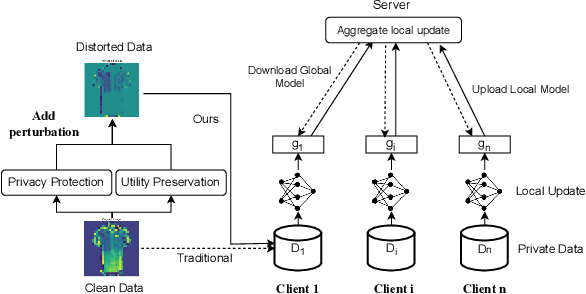
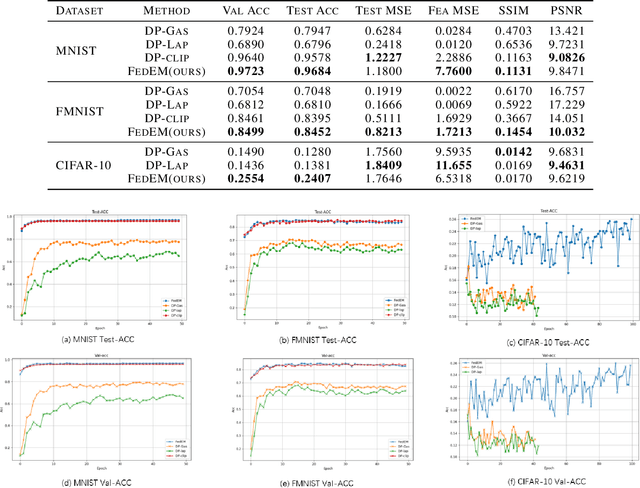
Federated Learning (FL) enables collaborative training of models across distributed clients without sharing local data, addressing privacy concerns in decentralized systems. However, the gradient-sharing process exposes private data to potential leakage, compromising FL's privacy guarantees in real-world applications. To address this issue, we propose Federated Error Minimization (FedEM), a novel algorithm that incorporates controlled perturbations through adaptive noise injection. This mechanism effectively mitigates gradient leakage attacks while maintaining model performance. Experimental results on benchmark datasets demonstrate that FedEM significantly reduces privacy risks and preserves model accuracy, achieving a robust balance between privacy protection and utility preservation.
A Unified Learn-to-Distort-Data Framework for Privacy-Utility Trade-off in Trustworthy Federated Learning
Jul 09, 2024

In this paper, we first give an introduction to the theoretical basis of the privacy-utility equilibrium in federated learning based on Bayesian privacy definitions and total variation distance privacy definitions. We then present the \textit{Learn-to-Distort-Data} framework, which provides a principled approach to navigate the privacy-utility equilibrium by explicitly modeling the distortion introduced by the privacy-preserving mechanism as a learnable variable and optimizing it jointly with the model parameters. We demonstrate the applicability of our framework to a variety of privacy-preserving mechanisms on the basis of data distortion and highlight its connections to related areas such as adversarial training, input robustness, and unlearnable examples. These connections enable leveraging techniques from these areas to design effective algorithms for privacy-utility equilibrium in federated learning under the \textit{Learn-to-Distort-Data} framework.