 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimestep-Aware SVDQuant-GPTQ for W4A4 Quantization of Wan2.2-I2V
May 26, 2026W4A4 quantization of large video diffusion Transformers offers substantial memory savings but is hindered by two main challenges: sparse large-magnitude activation outliers, and strongly timestep-dependent activation distributions across the multi-step denoising trajectory. These difficulties are compounded by Wan2.2-I2V's two-expert Mixture-of-Experts DiT design, whose high-noise and low-noise experts exhibit distinct quantization sensitivities that a single global calibration policy cannot capture. We propose a post-training quantization framework combining SVDQuant-based low-rank outlier compensation, GPTQ-based reconstruction-aware residual weight quantization, and timestep-bin-wise per-layer activation clipping-ratio search conducted independently for each expert. On the OpenS2V-Eval benchmark, our method reduces peak GPU memory by 59.3\% relative to the BF16 baseline while incurring only a 0.9\% drop in VBench average score and a 2.3\% drop in Imaging Quality, demonstrating that expert- and timestep-aware calibration is essential for high-fidelity W4A4 inference on MoE video DiTs.
Neuromem: A Granular Decomposition of the Streaming Lifecycle in External Memory for LLMs
Feb 15, 2026Most evaluations of External Memory Module assume a static setting: memory is built offline and queried at a fixed state. In practice, memory is streaming: new facts arrive continuously, insertions interleave with retrievals, and the memory state evolves while the model is serving queries. In this regime, accuracy and cost are governed by the full memory lifecycle, which encompasses the ingestion, maintenance, retrieval, and integration of information into generation. We present Neuromem, a scalable testbed that benchmarks External Memory Modules under an interleaved insertion-and-retrieval protocol and decomposes its lifecycle into five dimensions including memory data structure, normalization strategy, consolidation policy, query formulation strategy, and context integration mechanism. Using three representative datasets LOCOMO, LONGMEMEVAL, and MEMORYAGENTBENCH, Neuromem evaluates interchangeable variants within a shared serving stack, reporting token-level F1 and insertion/retrieval latency. Overall, we observe that performance typically degrades as memory grows across rounds, and time-related queries remain the most challenging category. The memory data structure largely determines the attainable quality frontier, while aggressive compression and generative integration mechanisms mostly shift cost between insertion and retrieval with limited accuracy gain.
FedEM: A Privacy-Preserving Framework for Concurrent Utility Preservation in Federated Learning
Mar 08, 2025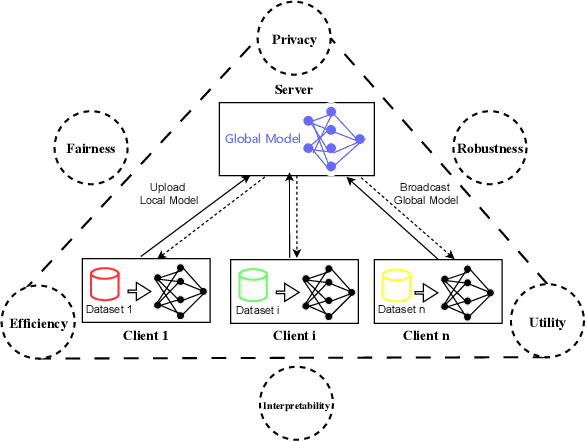
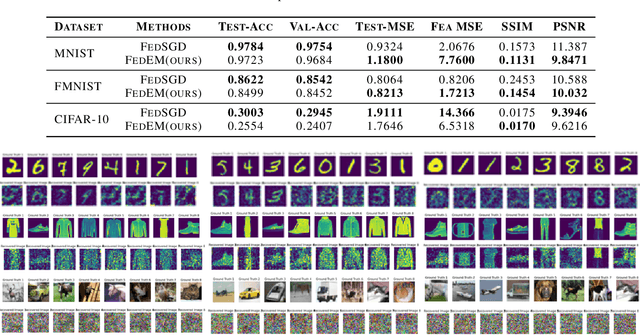
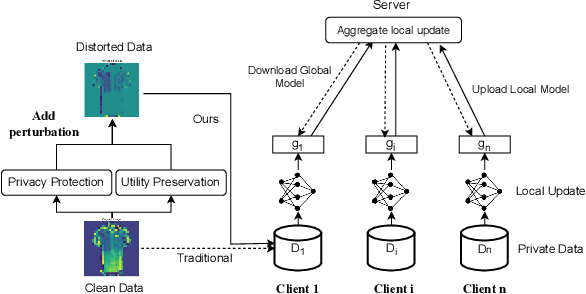
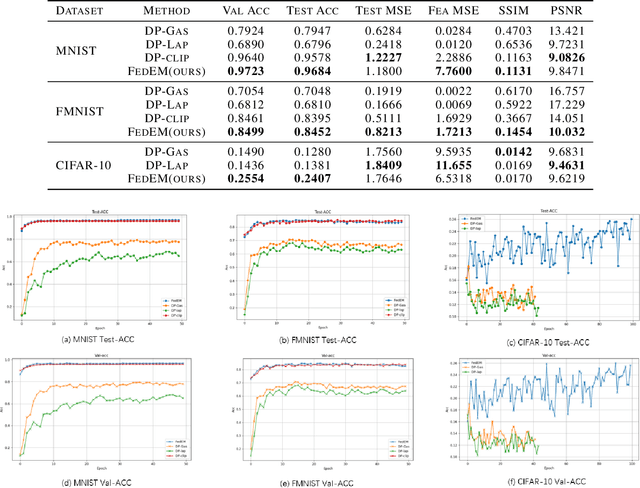
Federated Learning (FL) enables collaborative training of models across distributed clients without sharing local data, addressing privacy concerns in decentralized systems. However, the gradient-sharing process exposes private data to potential leakage, compromising FL's privacy guarantees in real-world applications. To address this issue, we propose Federated Error Minimization (FedEM), a novel algorithm that incorporates controlled perturbations through adaptive noise injection. This mechanism effectively mitigates gradient leakage attacks while maintaining model performance. Experimental results on benchmark datasets demonstrate that FedEM significantly reduces privacy risks and preserves model accuracy, achieving a robust balance between privacy protection and utility preservation.
FedEAT: A Robustness Optimization Framework for Federated LLMs
Feb 17, 2025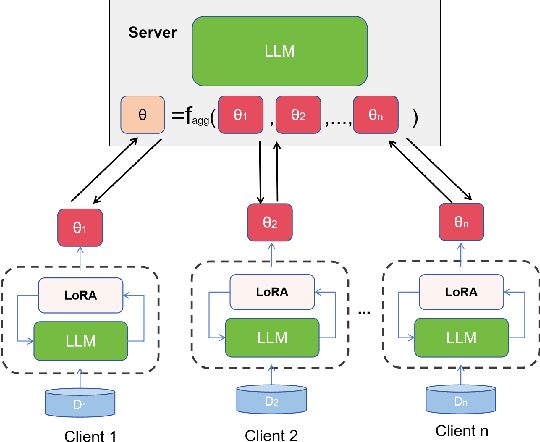
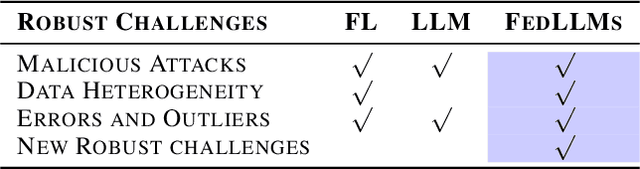
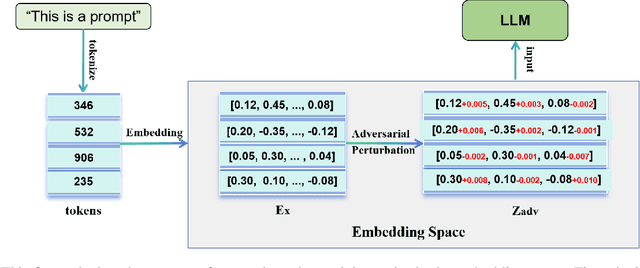
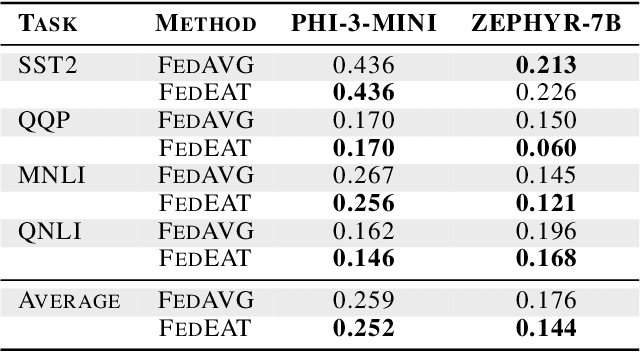
Significant advancements have been made by Large Language Models (LLMs) in the domains of natural language understanding and automated content creation. However, they still face persistent problems, including substantial computational costs and inadequate availability of training data. The combination of Federated Learning (FL) and LLMs (federated LLMs) offers a solution by leveraging distributed data while protecting privacy, which positions it as an ideal choice for sensitive domains. However, Federated LLMs still suffer from robustness challenges, including data heterogeneity, malicious clients, and adversarial attacks, which greatly hinder their applications. We first introduce the robustness problems in federated LLMs, to address these challenges, we propose FedEAT (Federated Embedding space Adversarial Training), a novel framework that applies adversarial training in the embedding space of client LLM and employs a robust aggregation approach, specifically geometric median aggregation, to enhance the robustness of Federated LLMs. Our experiments demonstrate that FedEAT effectively improves the robustness of Federated LLMs with minimal performance loss.
How to Select Pre-Trained Code Models for Reuse? A Learning Perspective
Jan 07, 2025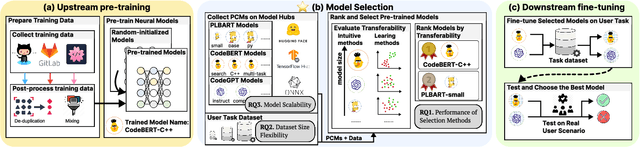


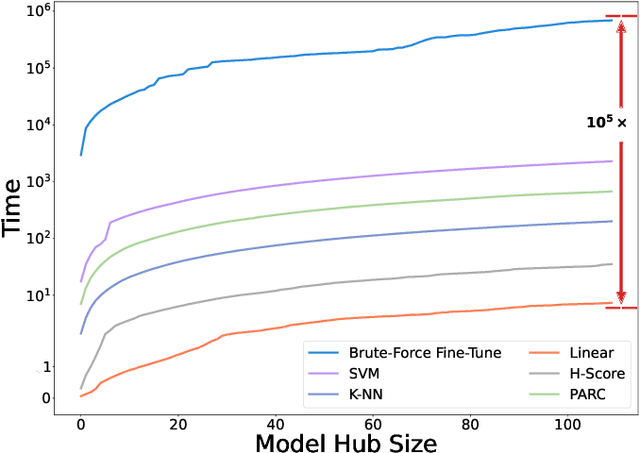
Pre-training a language model and then fine-tuning it has shown to be an efficient and effective technique for a wide range of code intelligence tasks, such as code generation, code summarization, and vulnerability detection. However, pretraining language models on a large-scale code corpus is computationally expensive. Fortunately, many off-the-shelf Pre-trained Code Models (PCMs), such as CodeBERT, CodeT5, CodeGen, and Code Llama, have been released publicly. These models acquire general code understanding and generation capability during pretraining, which enhances their performance on downstream code intelligence tasks. With an increasing number of these public pre-trained models, selecting the most suitable one to reuse for a specific task is essential. In this paper, we systematically investigate the reusability of PCMs. We first explore three intuitive model selection methods that select by size, training data, or brute-force fine-tuning. Experimental results show that these straightforward techniques either perform poorly or suffer high costs. Motivated by these findings, we explore learning-based model selection strategies that utilize pre-trained models without altering their parameters. Specifically, we train proxy models to gauge the performance of pre-trained models, and measure the distribution deviation between a model's latent features and the task's labels, using their closeness as an indicator of model transferability. We conduct experiments on 100 widely-used opensource PCMs for code intelligence tasks, with sizes ranging from 42.5 million to 3 billion parameters. The results demonstrate that learning-based selection methods reduce selection time to 100 seconds, compared to 2,700 hours with brute-force fine-tuning, with less than 6% performance degradation across related tasks.
NumbOD: A Spatial-Frequency Fusion Attack Against Object Detectors
Dec 22, 2024With the advancement of deep learning, object detectors (ODs) with various architectures have achieved significant success in complex scenarios like autonomous driving. Previous adversarial attacks against ODs have been focused on designing customized attacks targeting their specific structures (e.g., NMS and RPN), yielding some results but simultaneously constraining their scalability. Moreover, most efforts against ODs stem from image-level attacks originally designed for classification tasks, resulting in redundant computations and disturbances in object-irrelevant areas (e.g., background). Consequently, how to design a model-agnostic efficient attack to comprehensively evaluate the vulnerabilities of ODs remains challenging and unresolved. In this paper, we propose NumbOD, a brand-new spatial-frequency fusion attack against various ODs, aimed at disrupting object detection within images. We directly leverage the features output by the OD without relying on its internal structures to craft adversarial examples. Specifically, we first design a dual-track attack target selection strategy to select high-quality bounding boxes from OD outputs for targeting. Subsequently, we employ directional perturbations to shift and compress predicted boxes and change classification results to deceive ODs. Additionally, we focus on manipulating the high-frequency components of images to confuse ODs' attention on critical objects, thereby enhancing the attack efficiency. Our extensive experiments on nine ODs and two datasets show that NumbOD achieves powerful attack performance and high stealthiness.
Hyperbolic Hypergraph Neural Networks for Multi-Relational Knowledge Hypergraph Representation
Dec 11, 2024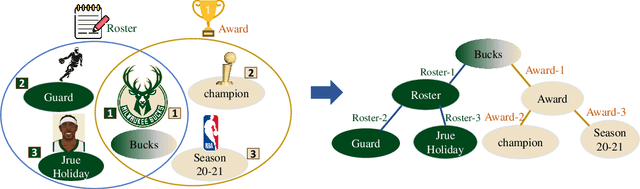
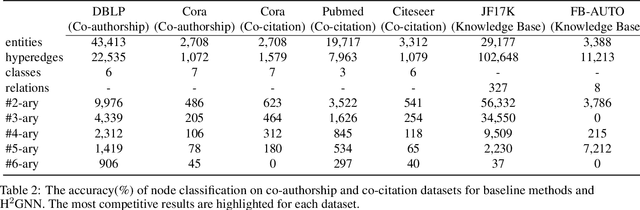
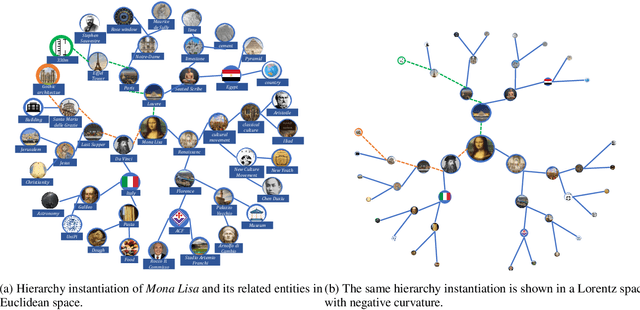
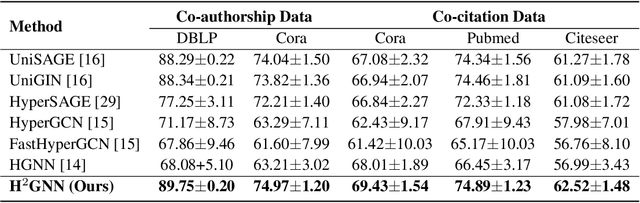
Knowledge hypergraphs generalize knowledge graphs using hyperedges to connect multiple entities and depict complicated relations. Existing methods either transform hyperedges into an easier-to-handle set of binary relations or view hyperedges as isolated and ignore their adjacencies. Both approaches have information loss and may potentially lead to the creation of sub-optimal models. To fix these issues, we propose the Hyperbolic Hypergraph Neural Network (H2GNN), whose essential component is the hyper-star message passing, a novel scheme motivated by a lossless expansion of hyperedges into hierarchies. It implements a direct embedding that consciously incorporates adjacent entities, hyper-relations, and entity position-aware information. As the name suggests, H2GNN operates in the hyperbolic space, which is more adept at capturing the tree-like hierarchy. We compare H2GNN with 15 baselines on knowledge hypergraphs, and it outperforms state-of-the-art approaches in both node classification and link prediction tasks.
Unlearnable 3D Point Clouds: Class-wise Transformation Is All You Need
Oct 04, 2024Traditional unlearnable strategies have been proposed to prevent unauthorized users from training on the 2D image data. With more 3D point cloud data containing sensitivity information, unauthorized usage of this new type data has also become a serious concern. To address this, we propose the first integral unlearnable framework for 3D point clouds including two processes: (i) we propose an unlearnable data protection scheme, involving a class-wise setting established by a category-adaptive allocation strategy and multi-transformations assigned to samples; (ii) we propose a data restoration scheme that utilizes class-wise inverse matrix transformation, thus enabling authorized-only training for unlearnable data. This restoration process is a practical issue overlooked in most existing unlearnable literature, \ie, even authorized users struggle to gain knowledge from 3D unlearnable data. Both theoretical and empirical results (including 6 datasets, 16 models, and 2 tasks) demonstrate the effectiveness of our proposed unlearnable framework. Our code is available at \url{https://github.com/CGCL-codes/UnlearnablePC}
DarkSAM: Fooling Segment Anything Model to Segment Nothing
Sep 26, 2024

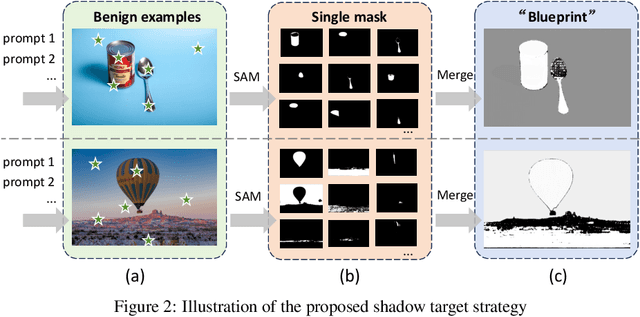
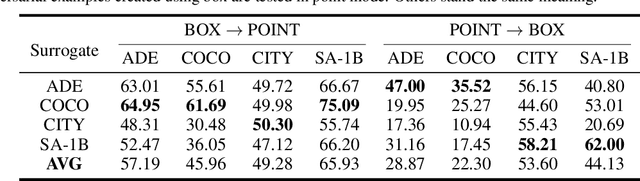
Segment Anything Model (SAM) has recently gained much attention for its outstanding generalization to unseen data and tasks. Despite its promising prospect, the vulnerabilities of SAM, especially to universal adversarial perturbation (UAP) have not been thoroughly investigated yet. In this paper, we propose DarkSAM, the first prompt-free universal attack framework against SAM, including a semantic decoupling-based spatial attack and a texture distortion-based frequency attack. We first divide the output of SAM into foreground and background. Then, we design a shadow target strategy to obtain the semantic blueprint of the image as the attack target. DarkSAM is dedicated to fooling SAM by extracting and destroying crucial object features from images in both spatial and frequency domains. In the spatial domain, we disrupt the semantics of both the foreground and background in the image to confuse SAM. In the frequency domain, we further enhance the attack effectiveness by distorting the high-frequency components (i.e., texture information) of the image. Consequently, with a single UAP, DarkSAM renders SAM incapable of segmenting objects across diverse images with varying prompts. Experimental results on four datasets for SAM and its two variant models demonstrate the powerful attack capability and transferability of DarkSAM.
ECLIPSE: Expunging Clean-label Indiscriminate Poisons via Sparse Diffusion Purification
Jun 25, 2024
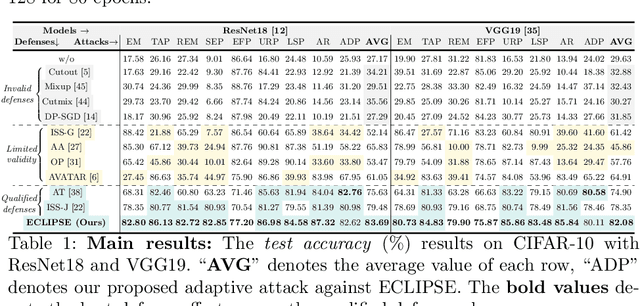
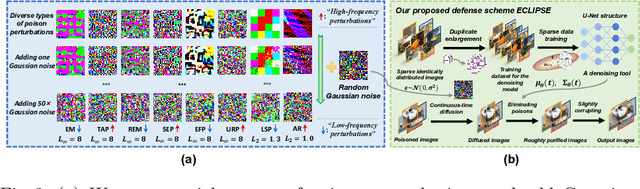
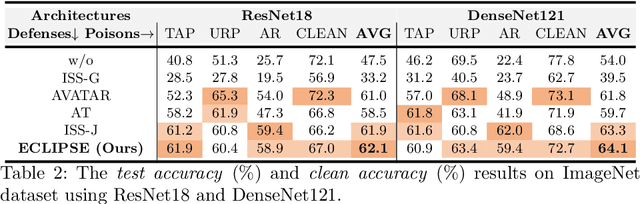
Clean-label indiscriminate poisoning attacks add invisible perturbations to correctly labeled training images, thus dramatically reducing the generalization capability of the victim models. Recently, some defense mechanisms have been proposed such as adversarial training, image transformation techniques, and image purification. However, these schemes are either susceptible to adaptive attacks, built on unrealistic assumptions, or only effective against specific poison types, limiting their universal applicability. In this research, we propose a more universally effective, practical, and robust defense scheme called ECLIPSE. We first investigate the impact of Gaussian noise on the poisons and theoretically prove that any kind of poison will be largely assimilated when imposing sufficient random noise. In light of this, we assume the victim has access to an extremely limited number of clean images (a more practical scene) and subsequently enlarge this sparse set for training a denoising probabilistic model (a universal denoising tool). We then begin by introducing Gaussian noise to absorb the poisons and then apply the model for denoising, resulting in a roughly purified dataset. Finally, to address the trade-off of the inconsistency in the assimilation sensitivity of different poisons by Gaussian noise, we propose a lightweight corruption compensation module to effectively eliminate residual poisons, providing a more universal defense approach. Extensive experiments demonstrate that our defense approach outperforms 10 state-of-the-art defenses. We also propose an adaptive attack against ECLIPSE and verify the robustness of our defense scheme. Our code is available at https://github.com/CGCL-codes/ECLIPSE.