 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning
Jun 06, 2024



Code Pre-trained Models (CodePTMs) based vulnerability detection have achieved promising results over recent years. However, these models struggle to generalize as they typically learn superficial mapping from source code to labels instead of understanding the root causes of code vulnerabilities, resulting in poor performance in real-world scenarios beyond the training instances. To tackle this challenge, we introduce VulLLM, a novel framework that integrates multi-task learning with Large Language Models (LLMs) to effectively mine deep-seated vulnerability features. Specifically, we construct two auxiliary tasks beyond the vulnerability detection task. First, we utilize the vulnerability patches to construct a vulnerability localization task. Second, based on the vulnerability features extracted from patches, we leverage GPT-4 to construct a vulnerability interpretation task. VulLLM innovatively augments vulnerability classification by leveraging generative LLMs to understand complex vulnerability patterns, thus compelling the model to capture the root causes of vulnerabilities rather than overfitting to spurious features of a single task. The experiments conducted on six large datasets demonstrate that VulLLM surpasses seven state-of-the-art models in terms of effectiveness, generalization, and robustness.
An Extensive Study on Adversarial Attack against Pre-trained Models of Code
Nov 23, 2023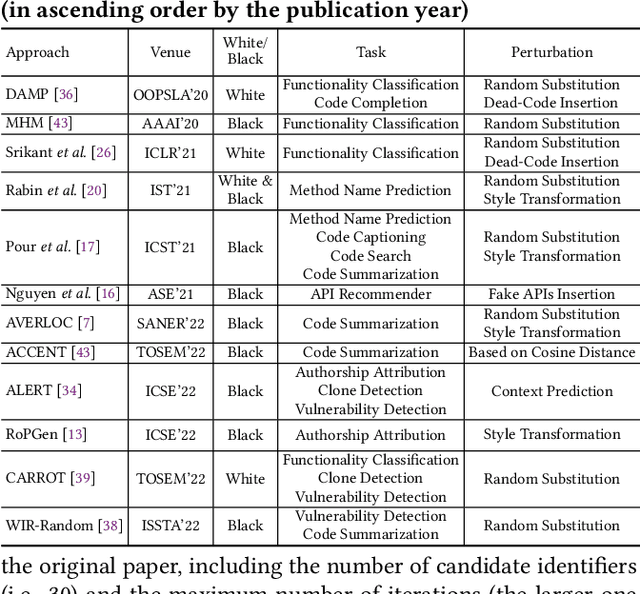
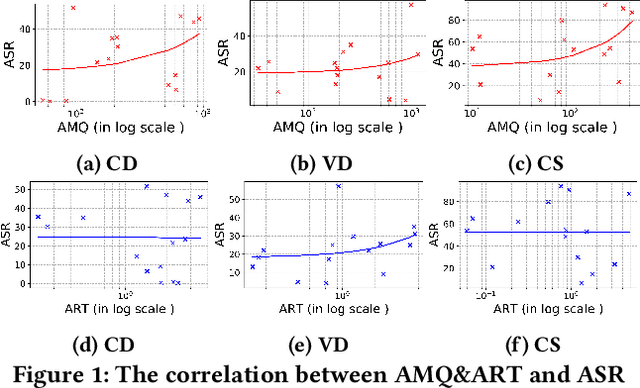
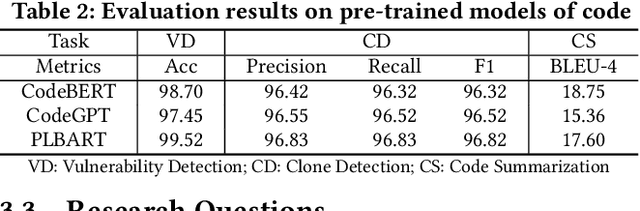
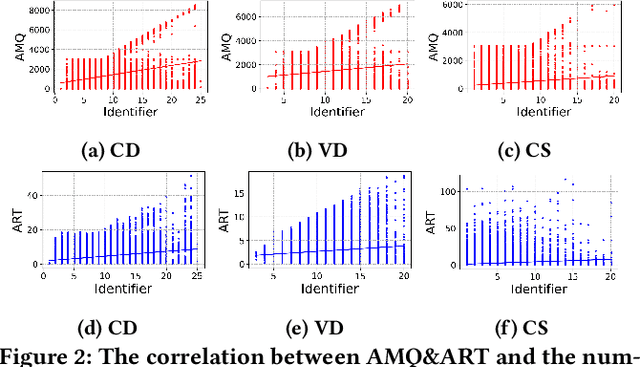
Transformer-based pre-trained models of code (PTMC) have been widely utilized and have achieved state-of-the-art performance in many mission-critical applications. However, they can be vulnerable to adversarial attacks through identifier substitution or coding style transformation, which can significantly degrade accuracy and may further incur security concerns. Although several approaches have been proposed to generate adversarial examples for PTMC, the effectiveness and efficiency of such approaches, especially on different code intelligence tasks, has not been well understood. To bridge this gap, this study systematically analyzes five state-of-the-art adversarial attack approaches from three perspectives: effectiveness, efficiency, and the quality of generated examples. The results show that none of the five approaches balances all these perspectives. Particularly, approaches with a high attack success rate tend to be time-consuming; the adversarial code they generate often lack naturalness, and vice versa. To address this limitation, we explore the impact of perturbing identifiers under different contexts and find that identifier substitution within for and if statements is the most effective. Based on these findings, we propose a new approach that prioritizes different types of statements for various tasks and further utilizes beam search to generate adversarial examples. Evaluation results show that it outperforms the state-of-the-art ALERT in terms of both effectiveness and efficiency while preserving the naturalness of the generated adversarial examples.