 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
Chinese Morph Resolution in E-commerce Live Streaming Scenarios
Dec 29, 2025E-commerce live streaming in China, particularly on platforms like Douyin, has become a major sales channel, but hosts often use morphs to evade scrutiny and engage in false advertising. This study introduces the Live Auditory Morph Resolution (LiveAMR) task to detect such violations. Unlike previous morph research focused on text-based evasion in social media and underground industries, LiveAMR targets pronunciation-based evasion in health and medical live streams. We constructed the first LiveAMR dataset with 86,790 samples and developed a method to transform the task into a text-to-text generation problem. By leveraging large language models (LLMs) to generate additional training data, we improved performance and demonstrated that morph resolution significantly enhances live streaming regulation.
Efficient LiDAR Reflectance Compression via Scanning Serialization
May 14, 2025Reflectance attributes in LiDAR point clouds provide essential information for downstream tasks but remain underexplored in neural compression methods. To address this, we introduce SerLiC, a serialization-based neural compression framework to fully exploit the intrinsic characteristics of LiDAR reflectance. SerLiC first transforms 3D LiDAR point clouds into 1D sequences via scan-order serialization, offering a device-centric perspective for reflectance analysis. Each point is then tokenized into a contextual representation comprising its sensor scanning index, radial distance, and prior reflectance, for effective dependencies exploration. For efficient sequential modeling, Mamba is incorporated with a dual parallelization scheme, enabling simultaneous autoregressive dependency capture and fast processing. Extensive experiments demonstrate that SerLiC attains over 2x volume reduction against the original reflectance data, outperforming the state-of-the-art method by up to 22% reduction of compressed bits while using only 2% of its parameters. Moreover, a lightweight version of SerLiC achieves > 10 fps (frames per second) with just 111K parameters, which is attractive for real-world applications.
GuardSplat: Efficient and Robust Watermarking for 3D Gaussian Splatting
Dec 02, 2024



3D Gaussian Splatting (3DGS) has recently created impressive assets for various applications. However, the copyright of these assets is not well protected as existing watermarking methods are not suited for 3DGS considering security, capacity, and invisibility. Besides, these methods often require hours or even days for optimization, limiting the application scenarios. In this paper, we propose GuardSplat, an innovative and efficient framework that effectively protects the copyright of 3DGS assets. Specifically, 1) We first propose a CLIP-guided Message Decoupling Optimization module for training the message decoder, leveraging CLIP's aligning capability and rich representations to achieve a high extraction accuracy with minimal optimization costs, presenting exceptional capability and efficiency. 2) Then, we propose a Spherical-harmonic-aware (SH-aware) Message Embedding module tailored for 3DGS, which employs a set of SH offsets to seamlessly embed the message into the SH features of each 3D Gaussian while maintaining the original 3D structure. It enables the 3DGS assets to be watermarked with minimal fidelity trade-offs and prevents malicious users from removing the messages from the model files, meeting the demands for invisibility and security. 3) We further propose an Anti-distortion Message Extraction module to improve robustness against various visual distortions. Extensive experiments demonstrate that GuardSplat outperforms the state-of-the-art methods and achieves fast optimization speed.
Exploiting Large Language Models Capabilities for Question Answer-Driven Knowledge Graph Completion Across Static and Temporal Domains
Aug 20, 2024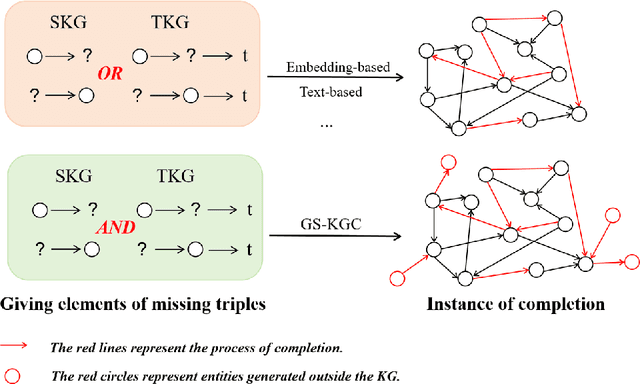
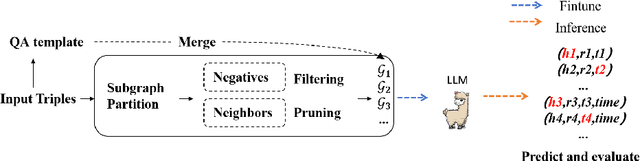
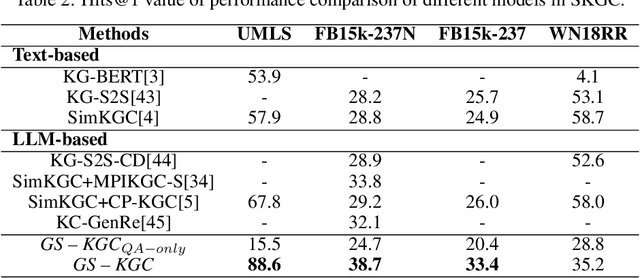
Knowledge graph completion (KGC) aims to identify missing triples in a knowledge graph (KG). This is typically achieved through tasks such as link prediction and instance completion. However, these methods often focus on either static knowledge graphs (SKGs) or temporal knowledge graphs (TKGs), addressing only within-scope triples. This paper introduces a new generative completion framework called Generative Subgraph-based KGC (GS-KGC). GS-KGC employs a question-answering format to directly generate target entities, addressing the challenge of questions having multiple possible answers. We propose a strategy that extracts subgraphs centered on entities and relationships within the KG, from which negative samples and neighborhood information are separately obtained to address the one-to-many problem. Our method generates negative samples using known facts to facilitate the discovery of new information. Furthermore, we collect and refine neighborhood path data of known entities, providing contextual information to enhance reasoning in large language models (LLMs). Our experiments evaluated the proposed method on four SKGs and two TKGs, achieving state-of-the-art Hits@1 metrics on five datasets. Analysis of the results shows that GS-KGC can discover new triples within existing KGs and generate new facts beyond the closed KG, effectively bridging the gap between closed-world and open-world KGC.
VividDreamer: Towards High-Fidelity and Efficient Text-to-3D Generation
Jun 21, 2024

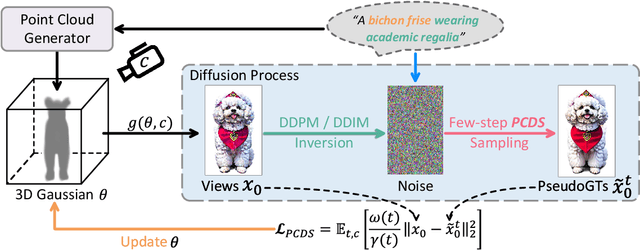
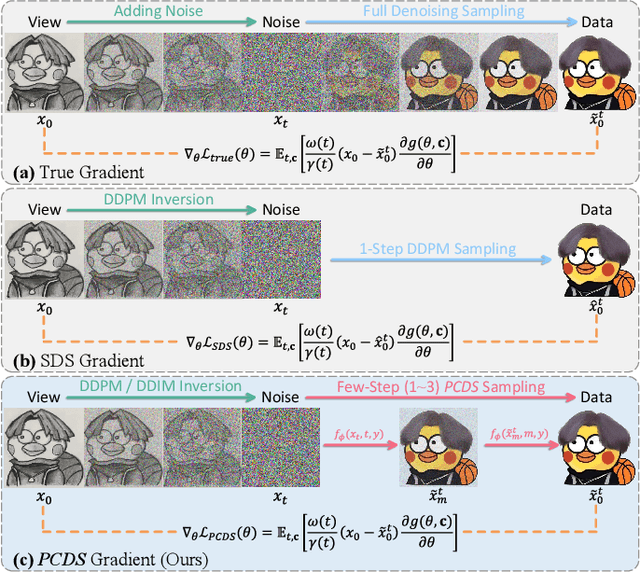
Text-to-3D generation aims to create 3D assets from text-to-image diffusion models. However, existing methods face an inherent bottleneck in generation quality because the widely-used objectives such as Score Distillation Sampling (SDS) inappropriately omit U-Net jacobians for swift generation, leading to significant bias compared to the "true" gradient obtained by full denoising sampling. This bias brings inconsistent updating direction, resulting in implausible 3D generation e.g., color deviation, Janus problem, and semantically inconsistent details). In this work, we propose Pose-dependent Consistency Distillation Sampling (PCDS), a novel yet efficient objective for diffusion-based 3D generation tasks. Specifically, PCDS builds the pose-dependent consistency function within diffusion trajectories, allowing to approximate true gradients through minimal sampling steps (1-3). Compared to SDS, PCDS can acquire a more accurate updating direction with the same sampling time (1 sampling step), while enabling few-step (2-3) sampling to trade compute for higher generation quality. For efficient generation, we propose a coarse-to-fine optimization strategy, which first utilizes 1-step PCDS to create the basic structure of 3D objects, and then gradually increases PCDS steps to generate fine-grained details. Extensive experiments demonstrate that our approach outperforms the state-of-the-art in generation quality and training efficiency, conspicuously alleviating the implausible 3D generation issues caused by the deviated updating direction. Moreover, it can be simply applied to many 3D generative applications to yield impressive 3D assets, please see our project page: https://narcissusex.github.io/VividDreamer.
Generalization-Enhanced Code Vulnerability Detection via Multi-Task Instruction Fine-Tuning
Jun 06, 2024



Code Pre-trained Models (CodePTMs) based vulnerability detection have achieved promising results over recent years. However, these models struggle to generalize as they typically learn superficial mapping from source code to labels instead of understanding the root causes of code vulnerabilities, resulting in poor performance in real-world scenarios beyond the training instances. To tackle this challenge, we introduce VulLLM, a novel framework that integrates multi-task learning with Large Language Models (LLMs) to effectively mine deep-seated vulnerability features. Specifically, we construct two auxiliary tasks beyond the vulnerability detection task. First, we utilize the vulnerability patches to construct a vulnerability localization task. Second, based on the vulnerability features extracted from patches, we leverage GPT-4 to construct a vulnerability interpretation task. VulLLM innovatively augments vulnerability classification by leveraging generative LLMs to understand complex vulnerability patterns, thus compelling the model to capture the root causes of vulnerabilities rather than overfitting to spurious features of a single task. The experiments conducted on six large datasets demonstrate that VulLLM surpasses seven state-of-the-art models in terms of effectiveness, generalization, and robustness.
DP-MDM: Detail-Preserving MR Reconstruction via Multiple Diffusion Models
May 09, 2024



Detail features of magnetic resonance images play a cru-cial role in accurate medical diagnosis and treatment, as they capture subtle changes that pose challenges for doc-tors when performing precise judgments. However, the widely utilized naive diffusion model has limitations, as it fails to accurately capture more intricate details. To en-hance the quality of MRI reconstruction, we propose a comprehensive detail-preserving reconstruction method using multiple diffusion models to extract structure and detail features in k-space domain instead of image do-main. Moreover, virtual binary modal masks are utilized to refine the range of values in k-space data through highly adaptive center windows, which allows the model to focus its attention more efficiently. Last but not least, an inverted pyramid structure is employed, where the top-down image information gradually decreases, ena-bling a cascade representation. The framework effective-ly represents multi-scale sampled data, taking into ac-count the sparsity of the inverted pyramid architecture, and utilizes cascade training data distribution to repre-sent multi-scale data. Through a step-by-step refinement approach, the method refines the approximation of de-tails. Finally, the proposed method was evaluated by con-ducting experiments on clinical and public datasets. The results demonstrate that the proposed method outper-forms other methods.
EFLNet: Enhancing Feature Learning for Infrared Small Target Detection
Jul 27, 2023Single-frame infrared small target detection is considered to be a challenging task, due to the extreme imbalance between target and background, bounding box regression is extremely sensitive to infrared small targets, and small target information is easy to lose in the high-level semantic layer. In this paper, we propose an enhancing feature learning network (EFLNet) based on YOLOv7 framework to solve these problems. First, we notice that there is an extremely imbalance between the target and the background in the infrared image, which makes the model pay more attention to the background features, resulting in missed detection. To address this problem, we propose a new adaptive threshold focal loss function that adjusts the loss weight automatically, compelling the model to allocate greater attention to target features. Second, we introduce the normalized Gaussian Wasserstein distance to alleviate the difficulty of model convergence caused by the extreme sensitivity of the bounding box regression to infrared small targets. Finally, we incorporate a dynamic head mechanism into the network to enable adaptive learning of the relative importance of each semantic layer. Experimental results demonstrate our method can achieve better performance in the detection performance of infrared small targets compared to state-of-the-art deep-learning based methods.
Tracking Objects and Activities with Attention for Temporal Sentence Grounding
Feb 21, 2023



Temporal sentence grounding (TSG) aims to localize the temporal segment which is semantically aligned with a natural language query in an untrimmed video.Most existing methods extract frame-grained features or object-grained features by 3D ConvNet or detection network under a conventional TSG framework, failing to capture the subtle differences between frames or to model the spatio-temporal behavior of core persons/objects. In this paper, we introduce a new perspective to address the TSG task by tracking pivotal objects and activities to learn more fine-grained spatio-temporal behaviors. Specifically, we propose a novel Temporal Sentence Tracking Network (TSTNet), which contains (A) a Cross-modal Targets Generator to generate multi-modal templates and search space, filtering objects and activities, and (B) a Temporal Sentence Tracker to track multi-modal targets for modeling the targets' behavior and to predict query-related segment. Extensive experiments and comparisons with state-of-the-arts are conducted on challenging benchmarks: Charades-STA and TACoS. And our TSTNet achieves the leading performance with a considerable real-time speed.