 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransform-Equivariant Consistency Learning for Temporal Sentence Grounding
May 06, 2023



This paper addresses the temporal sentence grounding (TSG). Although existing methods have made decent achievements in this task, they not only severely rely on abundant video-query paired data for training, but also easily fail into the dataset distribution bias. To alleviate these limitations, we introduce a novel Equivariant Consistency Regulation Learning (ECRL) framework to learn more discriminative query-related frame-wise representations for each video, in a self-supervised manner. Our motivation comes from that the temporal boundary of the query-guided activity should be consistently predicted under various video-level transformations. Concretely, we first design a series of spatio-temporal augmentations on both foreground and background video segments to generate a set of synthetic video samples. In particular, we devise a self-refine module to enhance the completeness and smoothness of the augmented video. Then, we present a novel self-supervised consistency loss (SSCL) applied on the original and augmented videos to capture their invariant query-related semantic by minimizing the KL-divergence between the sequence similarity of two videos and a prior Gaussian distribution of timestamp distance. At last, a shared grounding head is introduced to predict the transform-equivariant query-guided segment boundaries for both the original and augmented videos. Extensive experiments on three challenging datasets (ActivityNet, TACoS, and Charades-STA) demonstrate both effectiveness and efficiency of our proposed ECRL framework.
Rethinking the Video Sampling and Reasoning Strategies for Temporal Sentence Grounding
Jan 02, 2023Temporal sentence grounding (TSG) aims to identify the temporal boundary of a specific segment from an untrimmed video by a sentence query. All existing works first utilize a sparse sampling strategy to extract a fixed number of video frames and then conduct multi-modal interactions with query sentence for reasoning. However, we argue that these methods have overlooked two indispensable issues: 1) Boundary-bias: The annotated target segment generally refers to two specific frames as corresponding start and end timestamps. The video downsampling process may lose these two frames and take the adjacent irrelevant frames as new boundaries. 2) Reasoning-bias: Such incorrect new boundary frames also lead to the reasoning bias during frame-query interaction, reducing the generalization ability of model. To alleviate above limitations, in this paper, we propose a novel Siamese Sampling and Reasoning Network (SSRN) for TSG, which introduces a siamese sampling mechanism to generate additional contextual frames to enrich and refine the new boundaries. Specifically, a reasoning strategy is developed to learn the inter-relationship among these frames and generate soft labels on boundaries for more accurate frame-query reasoning. Such mechanism is also able to supplement the absent consecutive visual semantics to the sampled sparse frames for fine-grained activity understanding. Extensive experiments demonstrate the effectiveness of SSRN on three challenging datasets.
Hierarchical Local-Global Transformer for Temporal Sentence Grounding
Aug 31, 2022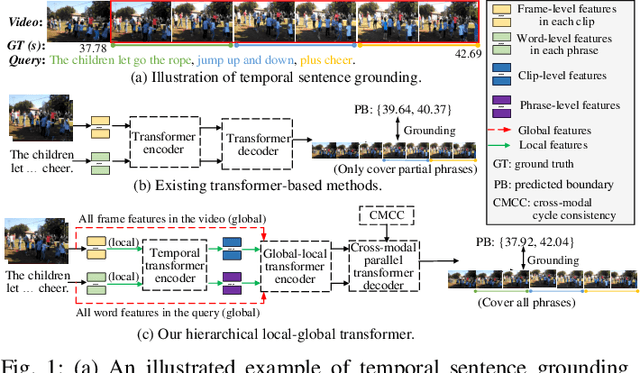
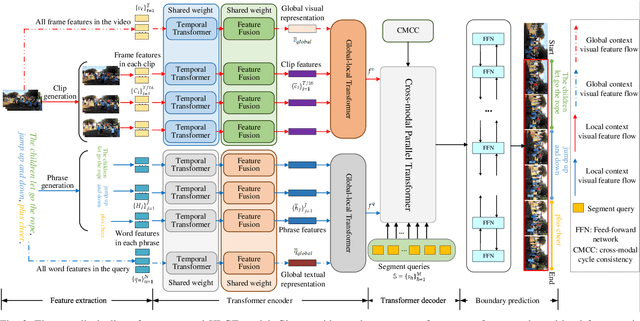
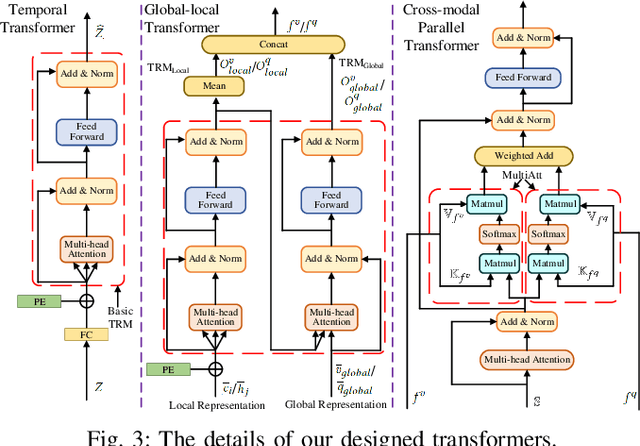
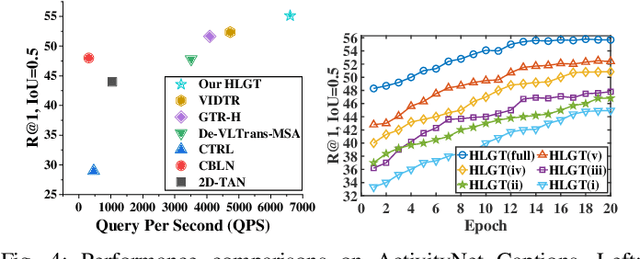
This paper studies the multimedia problem of temporal sentence grounding (TSG), which aims to accurately determine the specific video segment in an untrimmed video according to a given sentence query. Traditional TSG methods mainly follow the top-down or bottom-up framework and are not end-to-end. They severely rely on time-consuming post-processing to refine the grounding results. Recently, some transformer-based approaches are proposed to efficiently and effectively model the fine-grained semantic alignment between video and query. Although these methods achieve significant performance to some extent, they equally take frames of the video and words of the query as transformer input for correlating, failing to capture their different levels of granularity with distinct semantics. To address this issue, in this paper, we propose a novel Hierarchical Local-Global Transformer (HLGT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities for learning more fine-grained multi-modal representations. Specifically, we first split the video and query into individual clips and phrases to learn their local context (adjacent dependency) and global correlation (long-range dependency) via a temporal transformer. Then, a global-local transformer is introduced to learn the interactions between the local-level and global-level semantics for better multi-modal reasoning. Besides, we develop a new cross-modal cycle-consistency loss to enforce interaction between two modalities and encourage the semantic alignment between them. Finally, we design a brand-new cross-modal parallel transformer decoder to integrate the encoded visual and textual features for final grounding. Extensive experiments on three challenging datasets show that our proposed HLGT achieves a new state-of-the-art performance.
Backdoor Attacks on Crowd Counting
Jul 12, 2022
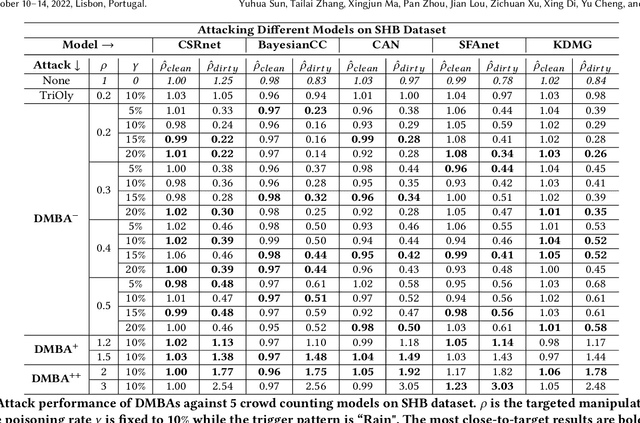
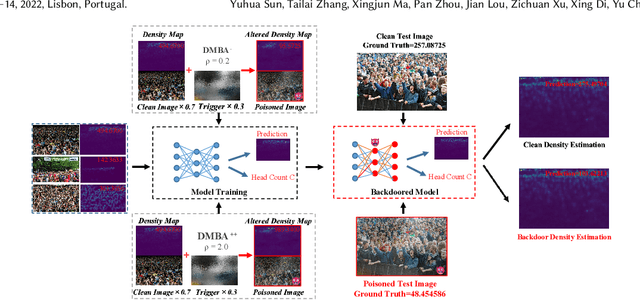
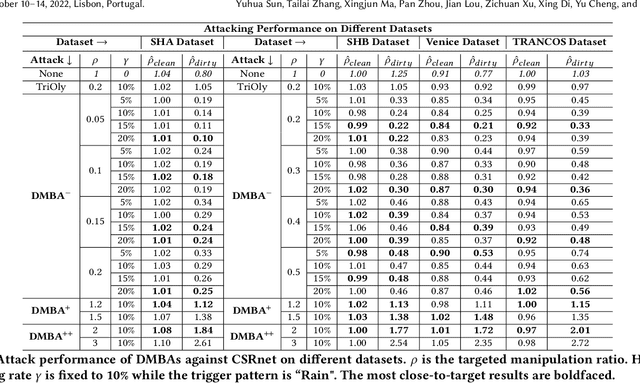
Crowd counting is a regression task that estimates the number of people in a scene image, which plays a vital role in a range of safety-critical applications, such as video surveillance, traffic monitoring and flow control. In this paper, we investigate the vulnerability of deep learning based crowd counting models to backdoor attacks, a major security threat to deep learning. A backdoor attack implants a backdoor trigger into a target model via data poisoning so as to control the model's predictions at test time. Different from image classification models on which most of existing backdoor attacks have been developed and tested, crowd counting models are regression models that output multi-dimensional density maps, thus requiring different techniques to manipulate. In this paper, we propose two novel Density Manipulation Backdoor Attacks (DMBA$^{-}$ and DMBA$^{+}$) to attack the model to produce arbitrarily large or small density estimations. Experimental results demonstrate the effectiveness of our DMBA attacks on five classic crowd counting models and four types of datasets. We also provide an in-depth analysis of the unique challenges of backdooring crowd counting models and reveal two key elements of effective attacks: 1) full and dense triggers and 2) manipulation of the ground truth counts or density maps. Our work could help evaluate the vulnerability of crowd counting models to potential backdoor attacks.
Unsupervised Temporal Video Grounding with Deep Semantic Clustering
Jan 14, 2022
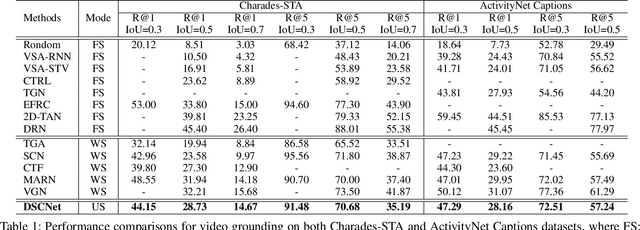
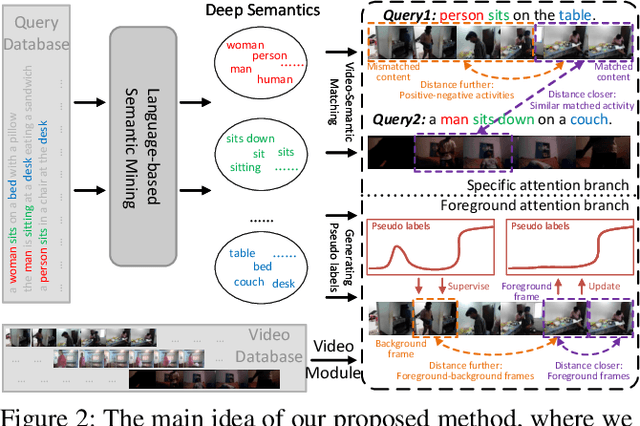

Temporal video grounding (TVG) aims to localize a target segment in a video according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on abundant video-query paired data, which is expensive and time-consuming to collect in real-world scenarios. In this paper, we explore whether a video grounding model can be learned without any paired annotations. To the best of our knowledge, this paper is the first work trying to address TVG in an unsupervised setting. Considering there is no paired supervision, we propose a novel Deep Semantic Clustering Network (DSCNet) to leverage all semantic information from the whole query set to compose the possible activity in each video for grounding. Specifically, we first develop a language semantic mining module, which extracts implicit semantic features from the whole query set. Then, these language semantic features serve as the guidance to compose the activity in video via a video-based semantic aggregation module. Finally, we utilize a foreground attention branch to filter out the redundant background activities and refine the grounding results. To validate the effectiveness of our DSCNet, we conduct experiments on both ActivityNet Captions and Charades-STA datasets. The results demonstrate that DSCNet achieves competitive performance, and even outperforms most weakly-supervised approaches.
Memory-Guided Semantic Learning Network for Temporal Sentence Grounding
Jan 03, 2022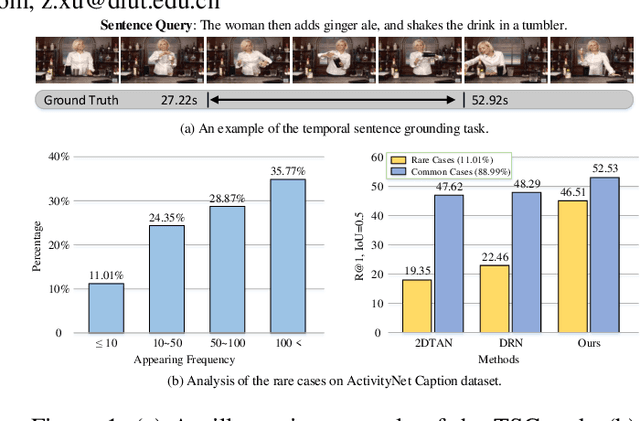
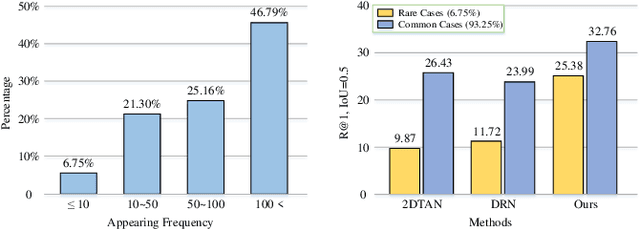
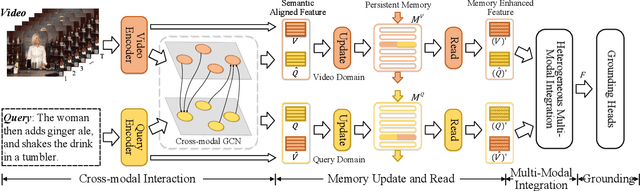
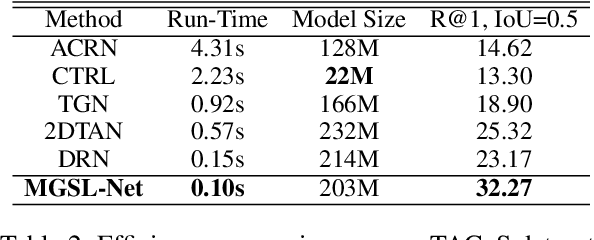
Temporal sentence grounding (TSG) is crucial and fundamental for video understanding. Although the existing methods train well-designed deep networks with a large amount of data, we find that they can easily forget the rarely appeared cases in the training stage due to the off-balance data distribution, which influences the model generalization and leads to undesirable performance. To tackle this issue, we propose a memory-augmented network, called Memory-Guided Semantic Learning Network (MGSL-Net), that learns and memorizes the rarely appeared content in TSG tasks. Specifically, MGSL-Net consists of three main parts: a cross-modal inter-action module, a memory augmentation module, and a heterogeneous attention module. We first align the given video-query pair by a cross-modal graph convolutional network, and then utilize a memory module to record the cross-modal shared semantic features in the domain-specific persistent memory. During training, the memory slots are dynamically associated with both common and rare cases, alleviating the forgetting issue. In testing, the rare cases can thus be enhanced by retrieving the stored memories, resulting in better generalization. At last, the heterogeneous attention module is utilized to integrate the enhanced multi-modal features in both video and query domains. Experimental results on three benchmarks show the superiority of our method on both effectiveness and efficiency, which substantially improves the accuracy not only on the entire dataset but also on rare cases.
Unsupervised Domain Adaptive Person Re-Identification via Human Learning Imitation
Dec 05, 2021
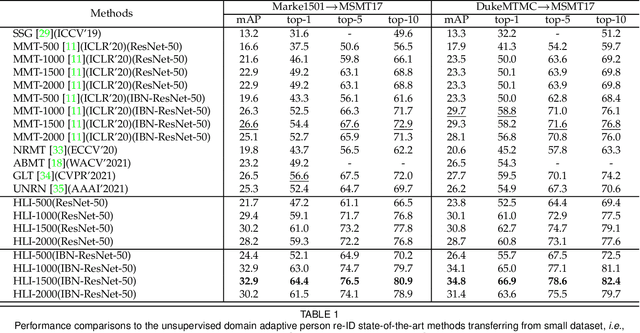
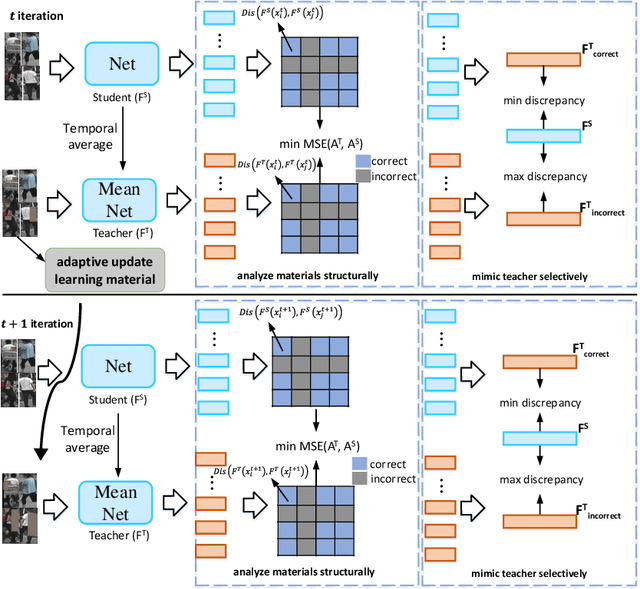
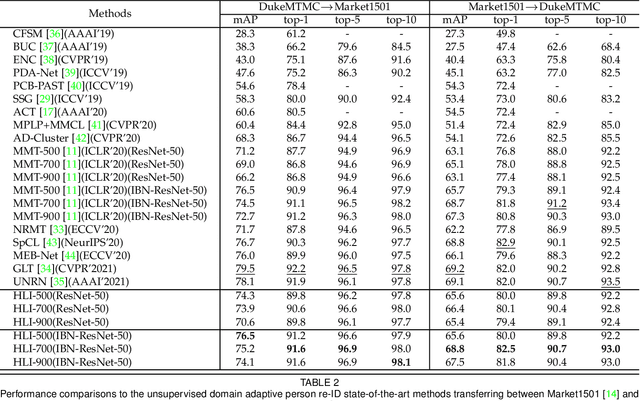
Unsupervised domain adaptive person re-identification has received significant attention due to its high practical value. In past years, by following the clustering and finetuning paradigm, researchers propose to utilize the teacher-student framework in their methods to decrease the domain gap between different person re-identification datasets. Inspired by recent teacher-student framework based methods, which try to mimic the human learning process either by making the student directly copy behavior from the teacher or selecting reliable learning materials, we propose to conduct further exploration to imitate the human learning process from different aspects, \textit{i.e.}, adaptively updating learning materials, selectively imitating teacher behaviors, and analyzing learning materials structures. The explored three components, collaborate together to constitute a new method for unsupervised domain adaptive person re-identification, which is called Human Learning Imitation framework. The experimental results on three benchmark datasets demonstrate the efficacy of our proposed method.
Context-aware Biaffine Localizing Network for Temporal Sentence Grounding
Mar 22, 2021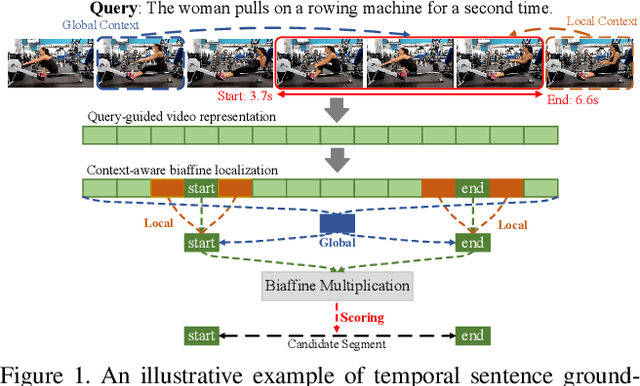
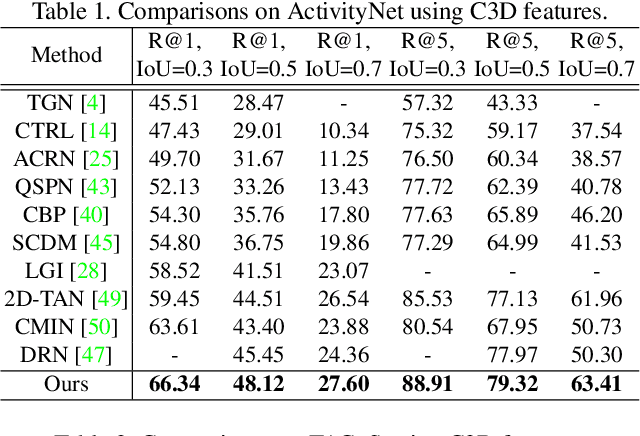
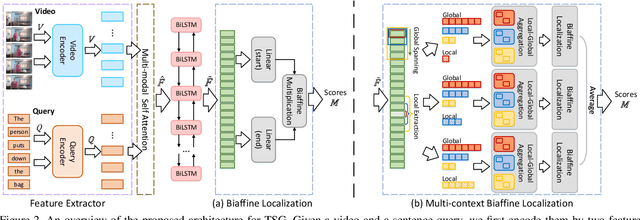
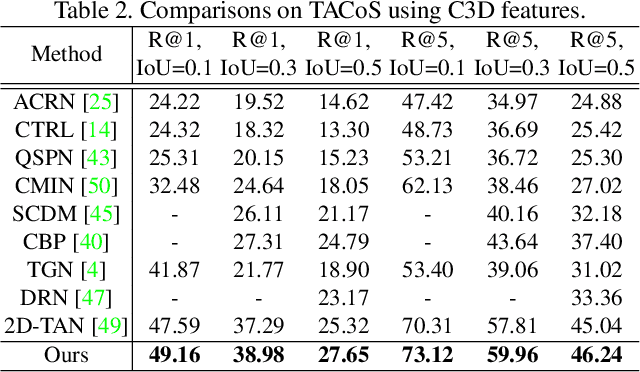
This paper addresses the problem of temporal sentence grounding (TSG), which aims to identify the temporal boundary of a specific segment from an untrimmed video by a sentence query. Previous works either compare pre-defined candidate segments with the query and select the best one by ranking, or directly regress the boundary timestamps of the target segment. In this paper, we propose a novel localization framework that scores all pairs of start and end indices within the video simultaneously with a biaffine mechanism. In particular, we present a Context-aware Biaffine Localizing Network (CBLN) which incorporates both local and global contexts into features of each start/end position for biaffine-based localization. The local contexts from the adjacent frames help distinguish the visually similar appearance, and the global contexts from the entire video contribute to reasoning the temporal relation. Besides, we also develop a multi-modal self-attention module to provide fine-grained query-guided video representation for this biaffine strategy. Extensive experiments show that our CBLN significantly outperforms state-of-the-arts on three public datasets (ActivityNet Captions, TACoS, and Charades-STA), demonstrating the effectiveness of the proposed localization framework.
Spatiotemporal Graph Neural Network based Mask Reconstruction for Video Object Segmentation
Dec 10, 2020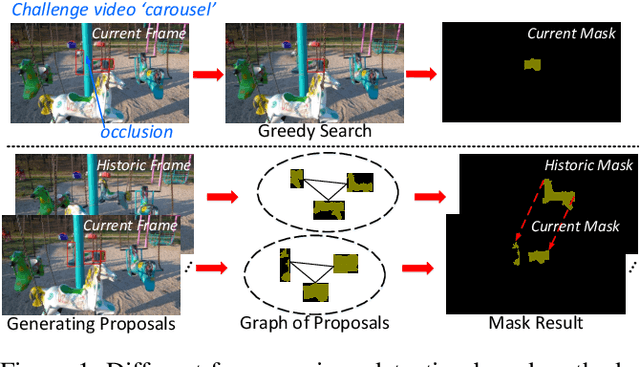
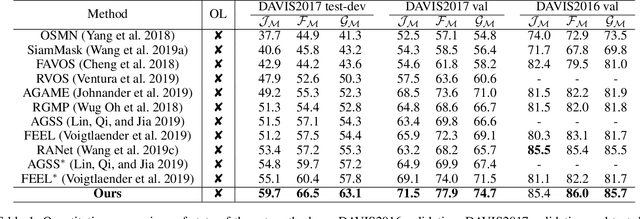
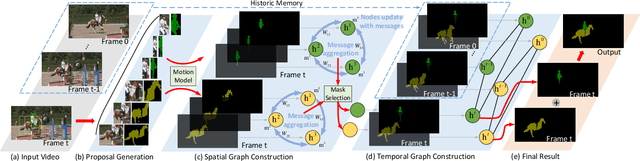
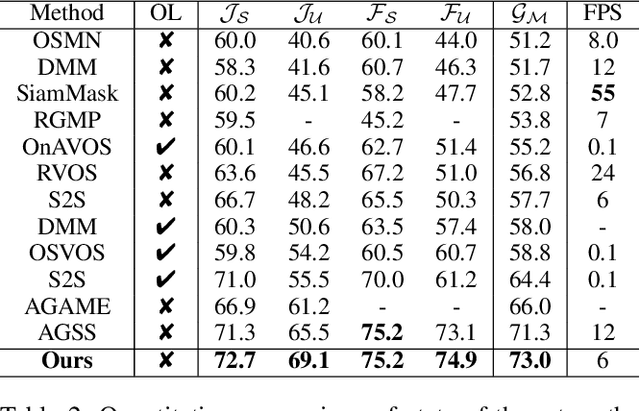
This paper addresses the task of segmenting class-agnostic objects in semi-supervised setting. Although previous detection based methods achieve relatively good performance, these approaches extract the best proposal by a greedy strategy, which may lose the local patch details outside the chosen candidate. In this paper, we propose a novel spatiotemporal graph neural network (STG-Net) to reconstruct more accurate masks for video object segmentation, which captures the local contexts by utilizing all proposals. In the spatial graph, we treat object proposals of a frame as nodes and represent their correlations with an edge weight strategy for mask context aggregation. To capture temporal information from previous frames, we use a memory network to refine the mask of current frame by retrieving historic masks in a temporal graph. The joint use of both local patch details and temporal relationships allow us to better address the challenges such as object occlusion and missing. Without online learning and fine-tuning, our STG-Net achieves state-of-the-art performance on four large benchmarks (DAVIS, YouTube-VOS, SegTrack-v2, and YouTube-Objects), demonstrating the effectiveness of the proposed approach.
Reinforcement Learning-based Black-Box Evasion Attacks to Link Prediction in Dynamic Graphs
Sep 12, 2020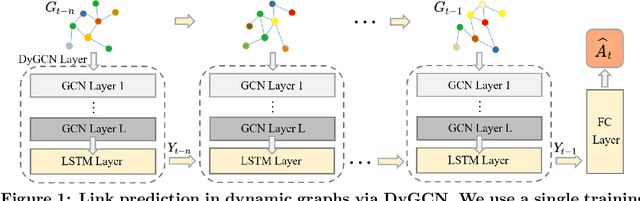
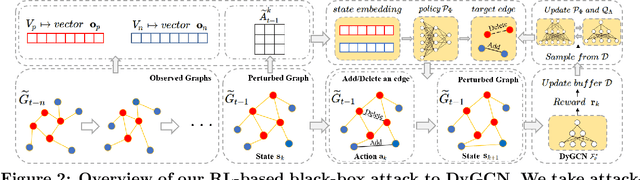
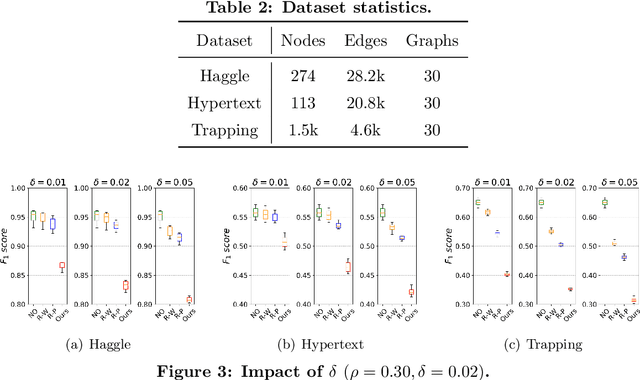
Link prediction in dynamic graphs (LPDG) is an important research problem that has diverse applications such as online recommendations, studies on disease contagion, organizational studies, etc. Various LPDG methods based on graph embedding and graph neural networks have been recently proposed and achieved state-of-the-art performance. In this paper, we study the vulnerability of LPDG methods and propose the first practical black-box evasion attack. Specifically, given a trained LPDG model, our attack aims to perturb the graph structure, without knowing to model parameters, model architecture, etc., such that the LPDG model makes as many wrong predicted links as possible. We design our attack based on a stochastic policy-based RL algorithm. Moreover, we evaluate our attack on three real-world graph datasets from different application domains. Experimental results show that our attack is both effective and efficient.