 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Local-Global Transformer for Temporal Sentence Grounding
Paper and Code
Aug 31, 2022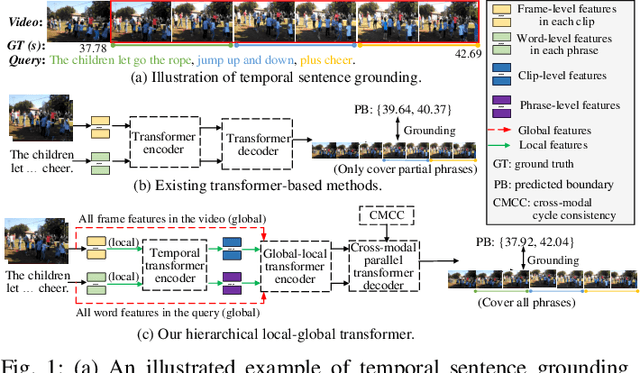
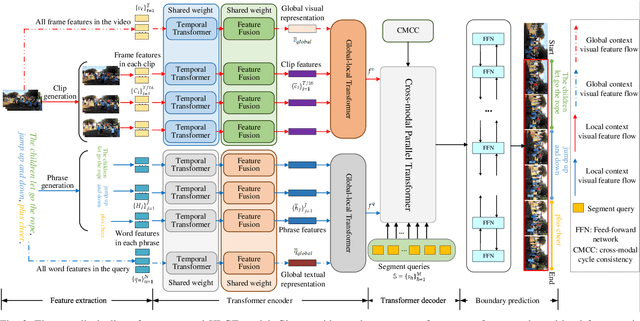
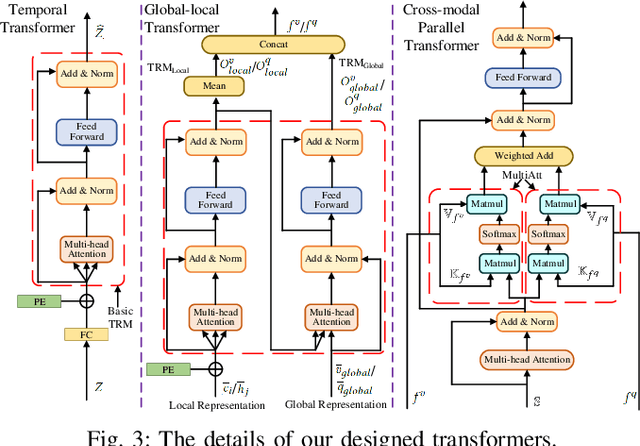
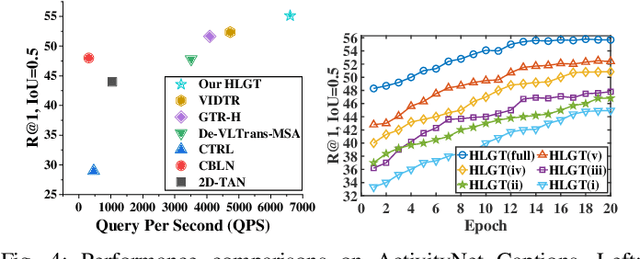
This paper studies the multimedia problem of temporal sentence grounding (TSG), which aims to accurately determine the specific video segment in an untrimmed video according to a given sentence query. Traditional TSG methods mainly follow the top-down or bottom-up framework and are not end-to-end. They severely rely on time-consuming post-processing to refine the grounding results. Recently, some transformer-based approaches are proposed to efficiently and effectively model the fine-grained semantic alignment between video and query. Although these methods achieve significant performance to some extent, they equally take frames of the video and words of the query as transformer input for correlating, failing to capture their different levels of granularity with distinct semantics. To address this issue, in this paper, we propose a novel Hierarchical Local-Global Transformer (HLGT) to leverage this hierarchy information and model the interactions between different levels of granularity and different modalities for learning more fine-grained multi-modal representations. Specifically, we first split the video and query into individual clips and phrases to learn their local context (adjacent dependency) and global correlation (long-range dependency) via a temporal transformer. Then, a global-local transformer is introduced to learn the interactions between the local-level and global-level semantics for better multi-modal reasoning. Besides, we develop a new cross-modal cycle-consistency loss to enforce interaction between two modalities and encourage the semantic alignment between them. Finally, we design a brand-new cross-modal parallel transformer decoder to integrate the encoded visual and textual features for final grounding. Extensive experiments on three challenging datasets show that our proposed HLGT achieves a new state-of-the-art performance.