 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Guided Semantic Learning Network for Temporal Sentence Grounding
Paper and Code
Jan 03, 2022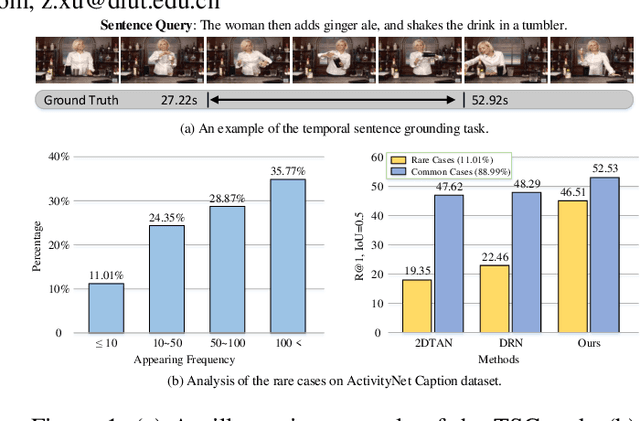
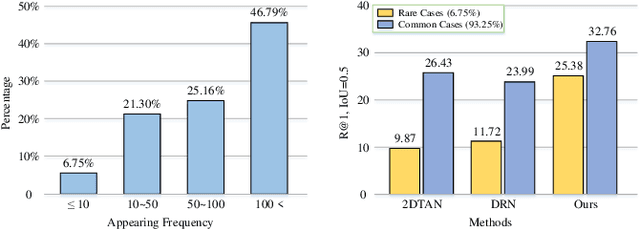
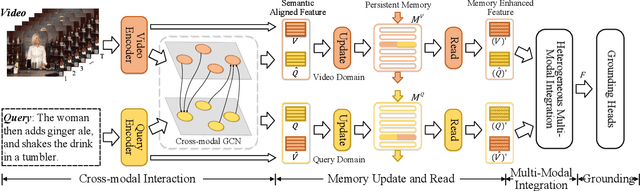
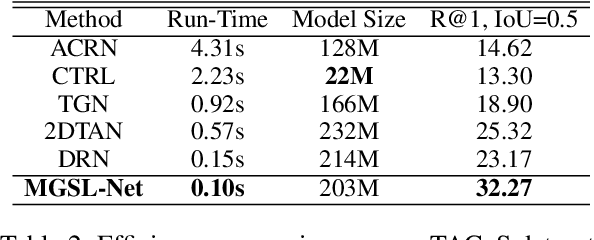
Temporal sentence grounding (TSG) is crucial and fundamental for video understanding. Although the existing methods train well-designed deep networks with a large amount of data, we find that they can easily forget the rarely appeared cases in the training stage due to the off-balance data distribution, which influences the model generalization and leads to undesirable performance. To tackle this issue, we propose a memory-augmented network, called Memory-Guided Semantic Learning Network (MGSL-Net), that learns and memorizes the rarely appeared content in TSG tasks. Specifically, MGSL-Net consists of three main parts: a cross-modal inter-action module, a memory augmentation module, and a heterogeneous attention module. We first align the given video-query pair by a cross-modal graph convolutional network, and then utilize a memory module to record the cross-modal shared semantic features in the domain-specific persistent memory. During training, the memory slots are dynamically associated with both common and rare cases, alleviating the forgetting issue. In testing, the rare cases can thus be enhanced by retrieving the stored memories, resulting in better generalization. At last, the heterogeneous attention module is utilized to integrate the enhanced multi-modal features in both video and query domains. Experimental results on three benchmarks show the superiority of our method on both effectiveness and efficiency, which substantially improves the accuracy not only on the entire dataset but also on rare cases.