 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProS: Facial Omni-Representation Learning via Prototype-based Self-Distillation
Nov 07, 2023



This paper presents a novel approach, called Prototype-based Self-Distillation (ProS), for unsupervised face representation learning. The existing supervised methods heavily rely on a large amount of annotated training facial data, which poses challenges in terms of data collection and privacy concerns. To address these issues, we propose ProS, which leverages a vast collection of unlabeled face images to learn a comprehensive facial omni-representation. In particular, ProS consists of two vision-transformers (teacher and student models) that are trained with different augmented images (cropping, blurring, coloring, etc.). Besides, we build a face-aware retrieval system along with augmentations to obtain the curated images comprising predominantly facial areas. To enhance the discrimination of learned features, we introduce a prototype-based matching loss that aligns the similarity distributions between features (teacher or student) and a set of learnable prototypes. After pre-training, the teacher vision transformer serves as a backbone for downstream tasks, including attribute estimation, expression recognition, and landmark alignment, achieved through simple fine-tuning with additional layers. Extensive experiments demonstrate that our method achieves state-of-the-art performance on various tasks, both in full and few-shot settings. Furthermore, we investigate pre-training with synthetic face images, and ProS exhibits promising performance in this scenario as well.
Transform-Equivariant Consistency Learning for Temporal Sentence Grounding
May 06, 2023



This paper addresses the temporal sentence grounding (TSG). Although existing methods have made decent achievements in this task, they not only severely rely on abundant video-query paired data for training, but also easily fail into the dataset distribution bias. To alleviate these limitations, we introduce a novel Equivariant Consistency Regulation Learning (ECRL) framework to learn more discriminative query-related frame-wise representations for each video, in a self-supervised manner. Our motivation comes from that the temporal boundary of the query-guided activity should be consistently predicted under various video-level transformations. Concretely, we first design a series of spatio-temporal augmentations on both foreground and background video segments to generate a set of synthetic video samples. In particular, we devise a self-refine module to enhance the completeness and smoothness of the augmented video. Then, we present a novel self-supervised consistency loss (SSCL) applied on the original and augmented videos to capture their invariant query-related semantic by minimizing the KL-divergence between the sequence similarity of two videos and a prior Gaussian distribution of timestamp distance. At last, a shared grounding head is introduced to predict the transform-equivariant query-guided segment boundaries for both the original and augmented videos. Extensive experiments on three challenging datasets (ActivityNet, TACoS, and Charades-STA) demonstrate both effectiveness and efficiency of our proposed ECRL framework.
Hypotheses Tree Building for One-Shot Temporal Sentence Localization
Jan 15, 2023
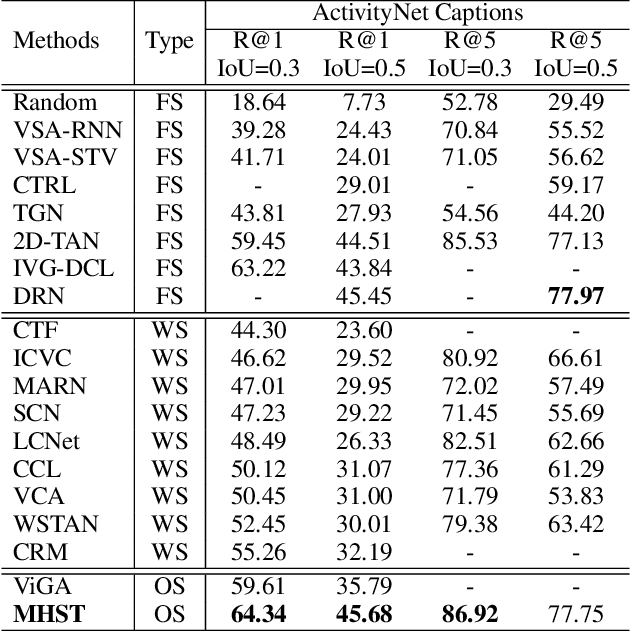
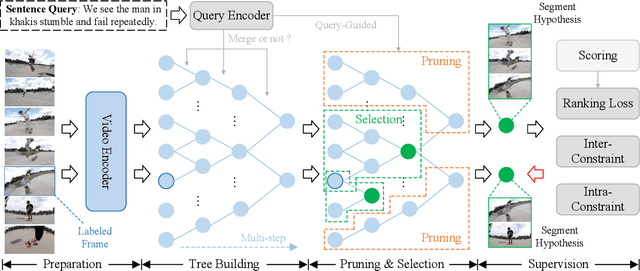
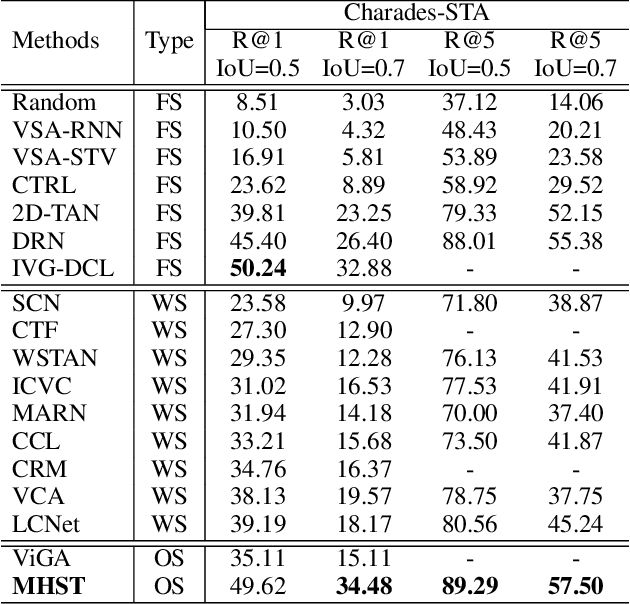
Given an untrimmed video, temporal sentence localization (TSL) aims to localize a specific segment according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on dense video frame annotations, which require a tremendous amount of human effort to collect. In this paper, we target another more practical and challenging setting: one-shot temporal sentence localization (one-shot TSL), which learns to retrieve the query information among the entire video with only one annotated frame. Particularly, we propose an effective and novel tree-structure baseline for one-shot TSL, called Multiple Hypotheses Segment Tree (MHST), to capture the query-aware discriminative frame-wise information under the insufficient annotations. Each video frame is taken as the leaf-node, and the adjacent frames sharing the same visual-linguistic semantics will be merged into the upper non-leaf node for tree building. At last, each root node is an individual segment hypothesis containing the consecutive frames of its leaf-nodes. During the tree construction, we also introduce a pruning strategy to eliminate the interference of query-irrelevant nodes. With our designed self-supervised loss functions, our MHST is able to generate high-quality segment hypotheses for ranking and selection with the query. Experiments on two challenging datasets demonstrate that MHST achieves competitive performance compared to existing methods.
Rethinking the Video Sampling and Reasoning Strategies for Temporal Sentence Grounding
Jan 02, 2023Temporal sentence grounding (TSG) aims to identify the temporal boundary of a specific segment from an untrimmed video by a sentence query. All existing works first utilize a sparse sampling strategy to extract a fixed number of video frames and then conduct multi-modal interactions with query sentence for reasoning. However, we argue that these methods have overlooked two indispensable issues: 1) Boundary-bias: The annotated target segment generally refers to two specific frames as corresponding start and end timestamps. The video downsampling process may lose these two frames and take the adjacent irrelevant frames as new boundaries. 2) Reasoning-bias: Such incorrect new boundary frames also lead to the reasoning bias during frame-query interaction, reducing the generalization ability of model. To alleviate above limitations, in this paper, we propose a novel Siamese Sampling and Reasoning Network (SSRN) for TSG, which introduces a siamese sampling mechanism to generate additional contextual frames to enrich and refine the new boundaries. Specifically, a reasoning strategy is developed to learn the inter-relationship among these frames and generate soft labels on boundaries for more accurate frame-query reasoning. Such mechanism is also able to supplement the absent consecutive visual semantics to the sampled sparse frames for fine-grained activity understanding. Extensive experiments demonstrate the effectiveness of SSRN on three challenging datasets.
MIGPerf: A Comprehensive Benchmark for Deep Learning Training and Inference Workloads on Multi-Instance GPUs
Jan 01, 2023New architecture GPUs like A100 are now equipped with multi-instance GPU (MIG) technology, which allows the GPU to be partitioned into multiple small, isolated instances. This technology provides more flexibility for users to support both deep learning training and inference workloads, but efficiently utilizing it can still be challenging. The vision of this paper is to provide a more comprehensive and practical benchmark study for MIG in order to eliminate the need for tedious manual benchmarking and tuning efforts. To achieve this vision, the paper presents MIGPerf, an open-source tool that streamlines the benchmark study for MIG. Using MIGPerf, the authors conduct a series of experiments, including deep learning training and inference characterization on MIG, GPU sharing characterization, and framework compatibility with MIG. The results of these experiments provide new insights and guidance for users to effectively employ MIG, and lay the foundation for further research on the orchestration of hybrid training and inference workloads on MIGs. The code and results are released on https://github.com/MLSysOps/MIGProfiler. This work is still in progress and more results will be published soon.
Backdoor Attacks on Crowd Counting
Jul 12, 2022
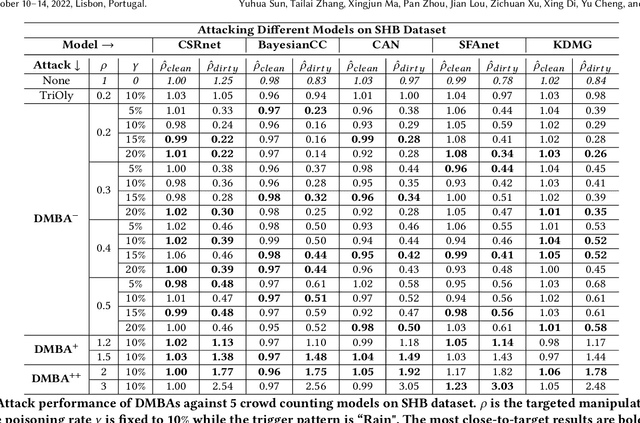
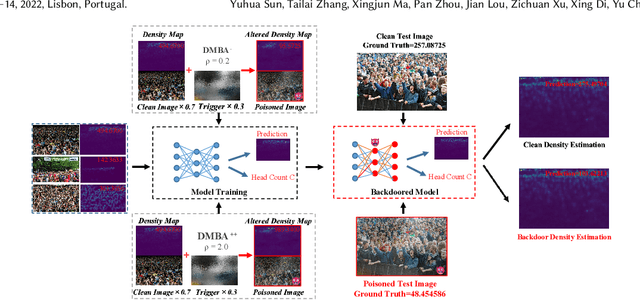
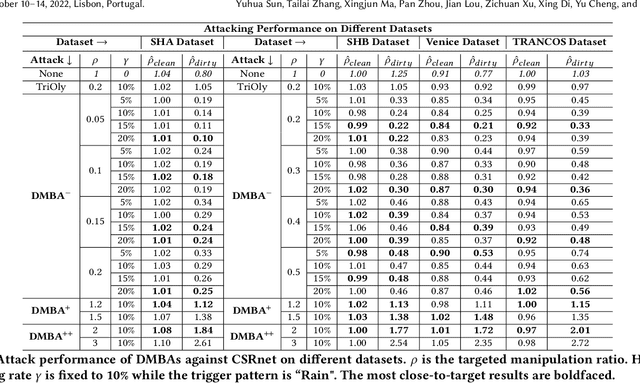
Crowd counting is a regression task that estimates the number of people in a scene image, which plays a vital role in a range of safety-critical applications, such as video surveillance, traffic monitoring and flow control. In this paper, we investigate the vulnerability of deep learning based crowd counting models to backdoor attacks, a major security threat to deep learning. A backdoor attack implants a backdoor trigger into a target model via data poisoning so as to control the model's predictions at test time. Different from image classification models on which most of existing backdoor attacks have been developed and tested, crowd counting models are regression models that output multi-dimensional density maps, thus requiring different techniques to manipulate. In this paper, we propose two novel Density Manipulation Backdoor Attacks (DMBA$^{-}$ and DMBA$^{+}$) to attack the model to produce arbitrarily large or small density estimations. Experimental results demonstrate the effectiveness of our DMBA attacks on five classic crowd counting models and four types of datasets. We also provide an in-depth analysis of the unique challenges of backdooring crowd counting models and reveal two key elements of effective attacks: 1) full and dense triggers and 2) manipulation of the ground truth counts or density maps. Our work could help evaluate the vulnerability of crowd counting models to potential backdoor attacks.
Unsupervised Temporal Video Grounding with Deep Semantic Clustering
Jan 14, 2022
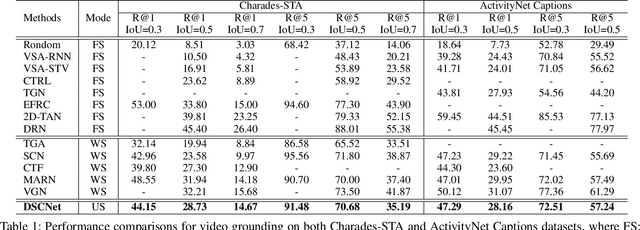
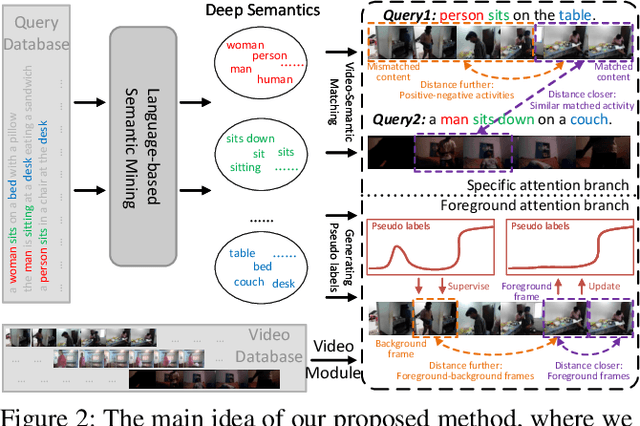

Temporal video grounding (TVG) aims to localize a target segment in a video according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on abundant video-query paired data, which is expensive and time-consuming to collect in real-world scenarios. In this paper, we explore whether a video grounding model can be learned without any paired annotations. To the best of our knowledge, this paper is the first work trying to address TVG in an unsupervised setting. Considering there is no paired supervision, we propose a novel Deep Semantic Clustering Network (DSCNet) to leverage all semantic information from the whole query set to compose the possible activity in each video for grounding. Specifically, we first develop a language semantic mining module, which extracts implicit semantic features from the whole query set. Then, these language semantic features serve as the guidance to compose the activity in video via a video-based semantic aggregation module. Finally, we utilize a foreground attention branch to filter out the redundant background activities and refine the grounding results. To validate the effectiveness of our DSCNet, we conduct experiments on both ActivityNet Captions and Charades-STA datasets. The results demonstrate that DSCNet achieves competitive performance, and even outperforms most weakly-supervised approaches.
Memory-Guided Semantic Learning Network for Temporal Sentence Grounding
Jan 03, 2022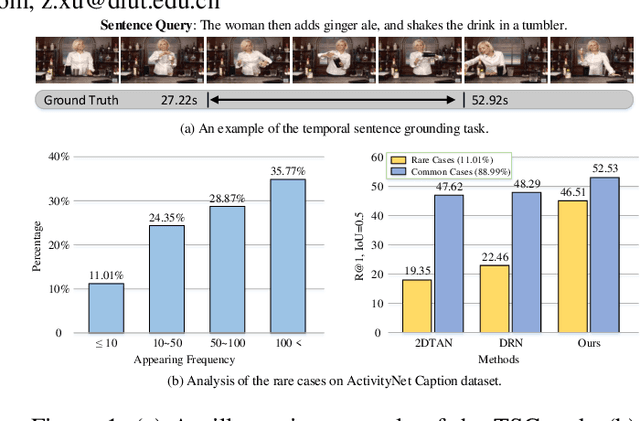
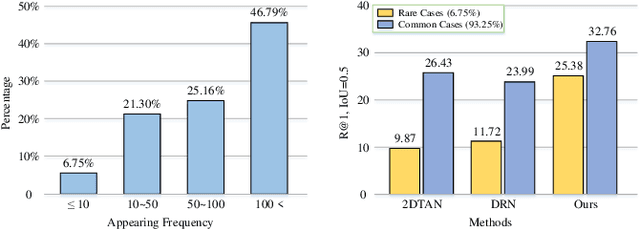
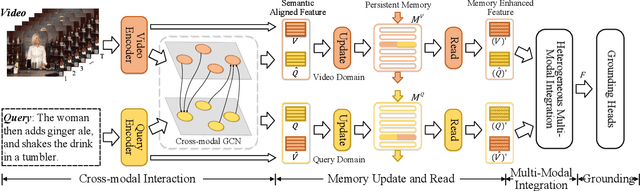
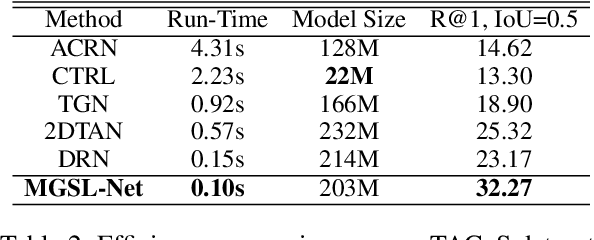
Temporal sentence grounding (TSG) is crucial and fundamental for video understanding. Although the existing methods train well-designed deep networks with a large amount of data, we find that they can easily forget the rarely appeared cases in the training stage due to the off-balance data distribution, which influences the model generalization and leads to undesirable performance. To tackle this issue, we propose a memory-augmented network, called Memory-Guided Semantic Learning Network (MGSL-Net), that learns and memorizes the rarely appeared content in TSG tasks. Specifically, MGSL-Net consists of three main parts: a cross-modal inter-action module, a memory augmentation module, and a heterogeneous attention module. We first align the given video-query pair by a cross-modal graph convolutional network, and then utilize a memory module to record the cross-modal shared semantic features in the domain-specific persistent memory. During training, the memory slots are dynamically associated with both common and rare cases, alleviating the forgetting issue. In testing, the rare cases can thus be enhanced by retrieving the stored memories, resulting in better generalization. At last, the heterogeneous attention module is utilized to integrate the enhanced multi-modal features in both video and query domains. Experimental results on three benchmarks show the superiority of our method on both effectiveness and efficiency, which substantially improves the accuracy not only on the entire dataset but also on rare cases.
DeepStationing: Thoracic Lymph Node Station Parsing in CT Scans using Anatomical Context Encoding and Key Organ Auto-Search
Sep 20, 2021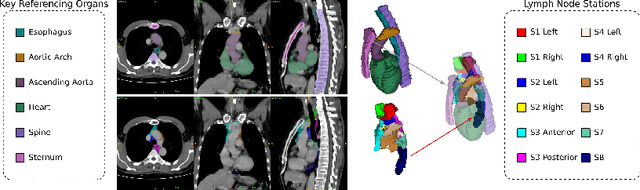
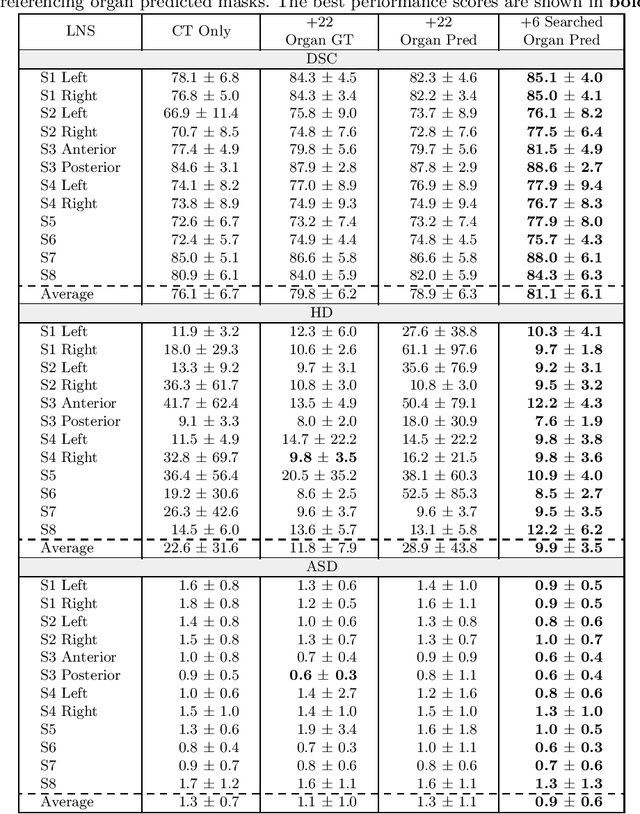
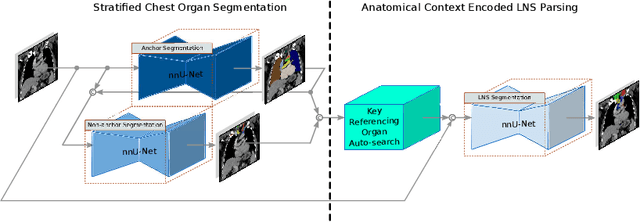

Lymph node station (LNS) delineation from computed tomography (CT) scans is an indispensable step in radiation oncology workflow. High inter-user variabilities across oncologists and prohibitive laboring costs motivated the automated approach. Previous works exploit anatomical priors to infer LNS based on predefined ad-hoc margins. However, without voxel-level supervision, the performance is severely limited. LNS is highly context-dependent - LNS boundaries are constrained by anatomical organs - we formulate it as a deep spatial and contextual parsing problem via encoded anatomical organs. This permits the deep network to better learn from both CT appearance and organ context. We develop a stratified referencing organ segmentation protocol that divides the organs into anchor and non-anchor categories and uses the former's predictions to guide the later segmentation. We further develop an auto-search module to identify the key organs that opt for the optimal LNS parsing performance. Extensive four-fold cross-validation experiments on a dataset of 98 esophageal cancer patients (with the most comprehensive set of 12 LNSs + 22 organs in thoracic region to date) are conducted. Our LNS parsing model produces significant performance improvements, with an average Dice score of 81.1% +/- 6.1%, which is 5.0% and 19.2% higher over the pure CT-based deep model and the previous representative approach, respectively.
Heterogeneous Face Frontalization via Domain Agnostic Learning
Jul 17, 2021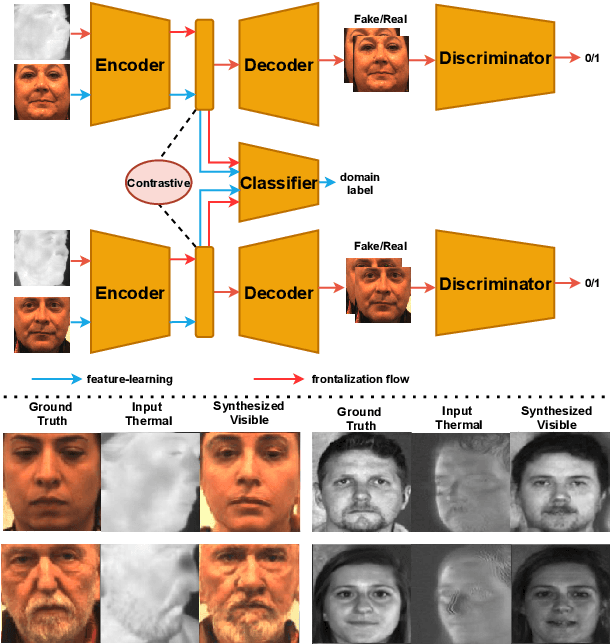
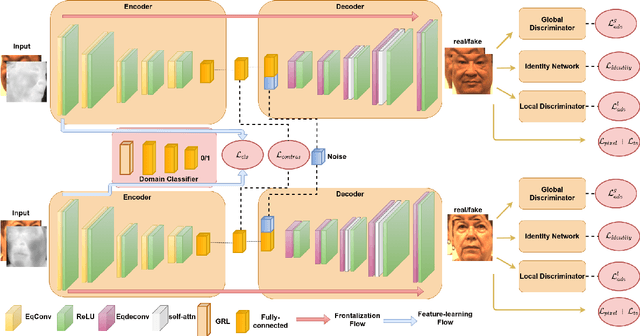
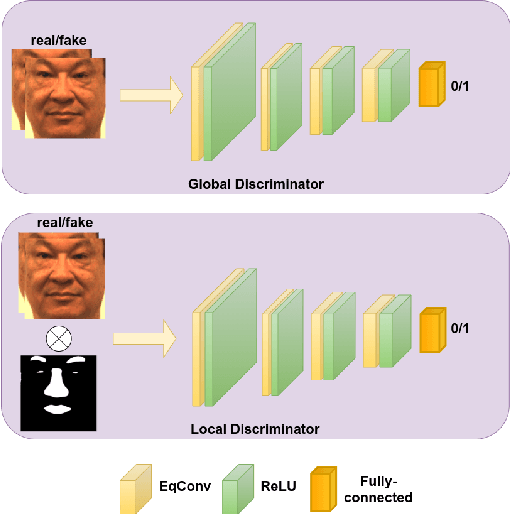
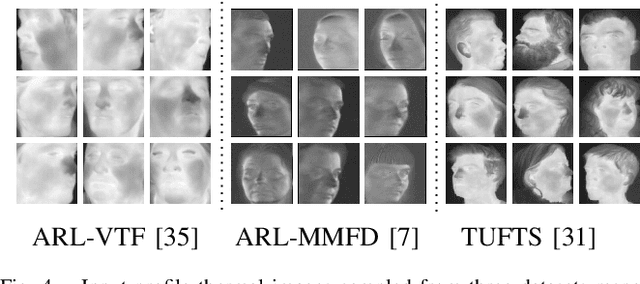
Recent advances in deep convolutional neural networks (DCNNs) have shown impressive performance improvements on thermal to visible face synthesis and matching problems. However, current DCNN-based synthesis models do not perform well on thermal faces with large pose variations. In order to deal with this problem, heterogeneous face frontalization methods are needed in which a model takes a thermal profile face image and generates a frontal visible face. This is an extremely difficult problem due to the large domain as well as large pose discrepancies between the two modalities. Despite its applications in biometrics and surveillance, this problem is relatively unexplored in the literature. We propose a domain agnostic learning-based generative adversarial network (DAL-GAN) which can synthesize frontal views in the visible domain from thermal faces with pose variations. DAL-GAN consists of a generator with an auxiliary classifier and two discriminators which capture both local and global texture discriminations for better synthesis. A contrastive constraint is enforced in the latent space of the generator with the help of a dual-path training strategy, which improves the feature vector discrimination. Finally, a multi-purpose loss function is utilized to guide the network in synthesizing identity preserving cross-domain frontalization. Extensive experimental results demonstrate that DAL-GAN can generate better quality frontal views compared to the other baseline methods.