 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring ChatGPT for Next-generation Information Retrieval: Opportunities and Challenges
Feb 17, 2024

The rapid advancement of artificial intelligence (AI) has highlighted ChatGPT as a pivotal technology in the field of information retrieval (IR). Distinguished from its predecessors, ChatGPT offers significant benefits that have attracted the attention of both the industry and academic communities. While some view ChatGPT as a groundbreaking innovation, others attribute its success to the effective integration of product development and market strategies. The emergence of ChatGPT, alongside GPT-4, marks a new phase in Generative AI, generating content that is distinct from training examples and exceeding the capabilities of the prior GPT-3 model by OpenAI. Unlike the traditional supervised learning approach in IR tasks, ChatGPT challenges existing paradigms, bringing forth new challenges and opportunities regarding text quality assurance, model bias, and efficiency. This paper seeks to examine the impact of ChatGPT on IR tasks and offer insights into its potential future developments.
* Survey Paper
DataCI: A Platform for Data-Centric AI on Streaming Data
Jul 03, 2023



We introduce DataCI, a comprehensive open-source platform designed specifically for data-centric AI in dynamic streaming data settings. DataCI provides 1) an infrastructure with rich APIs for seamless streaming dataset management, data-centric pipeline development and evaluation on streaming scenarios, 2) an carefully designed versioning control function to track the pipeline lineage, and 3) an intuitive graphical interface for a better interactive user experience. Preliminary studies and demonstrations attest to the easy-to-use and effectiveness of DataCI, highlighting its potential to revolutionize the practice of data-centric AI in streaming data contexts.
Towards Balanced Active Learning for Multimodal Classification
Jun 14, 2023



Training multimodal networks requires a vast amount of data due to their larger parameter space compared to unimodal networks. Active learning is a widely used technique for reducing data annotation costs by selecting only those samples that could contribute to improving model performance. However, current active learning strategies are mostly designed for unimodal tasks, and when applied to multimodal data, they often result in biased sample selection from the dominant modality. This unfairness hinders balanced multimodal learning, which is crucial for achieving optimal performance. To address this issue, we propose three guidelines for designing a more balanced multimodal active learning strategy. Following these guidelines, a novel approach is proposed to achieve more fair data selection by modulating the gradient embedding with the dominance degree among modalities. Our studies demonstrate that the proposed method achieves more balanced multimodal learning by avoiding greedy sample selection from the dominant modality. Our approach outperforms existing active learning strategies on a variety of multimodal classification tasks. Overall, our work highlights the importance of balancing sample selection in multimodal active learning and provides a practical solution for achieving more balanced active learning for multimodal classification.
MIGPerf: A Comprehensive Benchmark for Deep Learning Training and Inference Workloads on Multi-Instance GPUs
Jan 01, 2023New architecture GPUs like A100 are now equipped with multi-instance GPU (MIG) technology, which allows the GPU to be partitioned into multiple small, isolated instances. This technology provides more flexibility for users to support both deep learning training and inference workloads, but efficiently utilizing it can still be challenging. The vision of this paper is to provide a more comprehensive and practical benchmark study for MIG in order to eliminate the need for tedious manual benchmarking and tuning efforts. To achieve this vision, the paper presents MIGPerf, an open-source tool that streamlines the benchmark study for MIG. Using MIGPerf, the authors conduct a series of experiments, including deep learning training and inference characterization on MIG, GPU sharing characterization, and framework compatibility with MIG. The results of these experiments provide new insights and guidance for users to effectively employ MIG, and lay the foundation for further research on the orchestration of hybrid training and inference workloads on MIGs. The code and results are released on https://github.com/MLSysOps/MIGProfiler. This work is still in progress and more results will be published soon.
Active-Learning-as-a-Service: An Efficient MLOps System for Data-Centric AI
Jul 19, 2022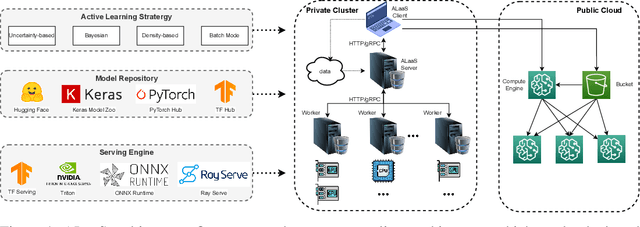
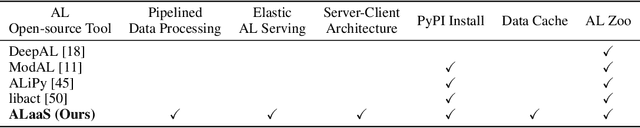
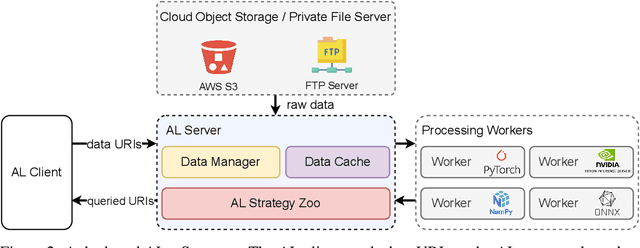

The success of today's AI applications requires not only model training (Model-centric) but also data engineering (Data-centric). In data-centric AI, active learning (AL) plays a vital role, but current AL tools can not perform AL tasks efficiently. To this end, this paper presents an efficient MLOps system for AL, named ALaaS (Active-Learning-as-a-Service). Specifically, ALaaS adopts a server-client architecture to support an AL pipeline and implements stage-level parallelism for high efficiency. Meanwhile, caching and batching techniques are employed to further accelerate the AL process. In addition to efficiency, ALaaS ensures accessibility with the help of the design philosophy of configuration-as-a-service. It also abstracts an AL process to several components and provides rich APIs for advanced users to extend the system to new scenarios. Extensive experiments show that ALaaS outperforms all other baselines in terms of latency and throughput. Further ablation studies demonstrate the effectiveness of our design as well as ALaaS's ease to use. Our code is available at \url{https://github.com/MLSysOps/alaas}.
Progressive Continual Learning for Spoken Keyword Spotting
Feb 07, 2022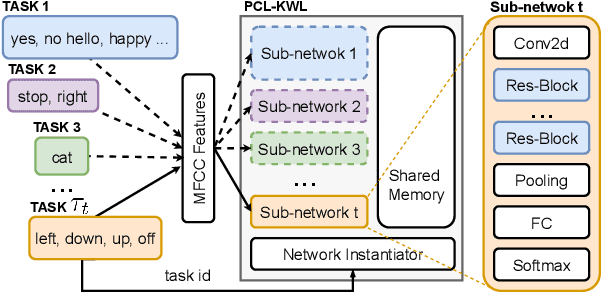
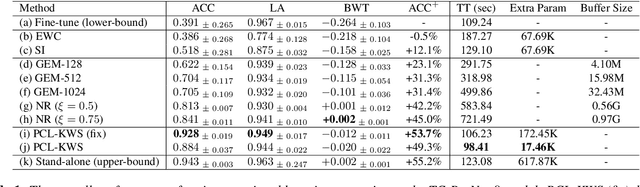
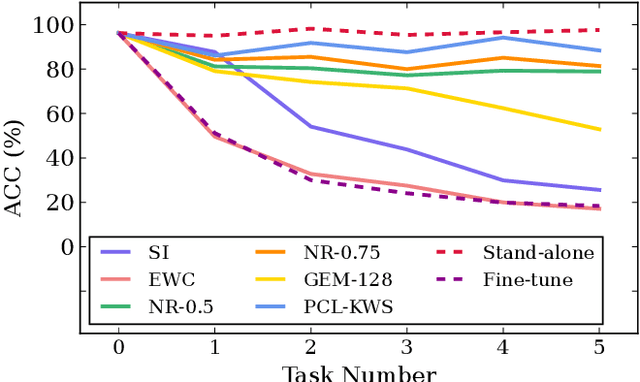

Catastrophic forgetting is a thorny challenge when updating keyword spotting (KWS) models after deployment. To tackle such challenges, we propose a progressive continual learning strategy for small-footprint spoken keyword spotting (PCL-KWS). Specifically, the proposed PCL-KWS framework introduces a network instantiator to generate the task-specific sub-networks for remembering previously learned keywords. As a result, the PCL-KWS approach incrementally learns new keywords without forgetting prior knowledge. Besides, the keyword-aware network scaling mechanism of PCL-KWS constrains the growth of model parameters while achieving high performance. Experimental results show that after learning five new tasks sequentially, our proposed PCL-KWS approach archives the new state-of-the-art performance of 92.8% average accuracy for all the tasks on Google Speech Command dataset compared with other baselines.
ModelCI-e: Enabling Continual Learning in Deep Learning Serving Systems
Jun 06, 2021
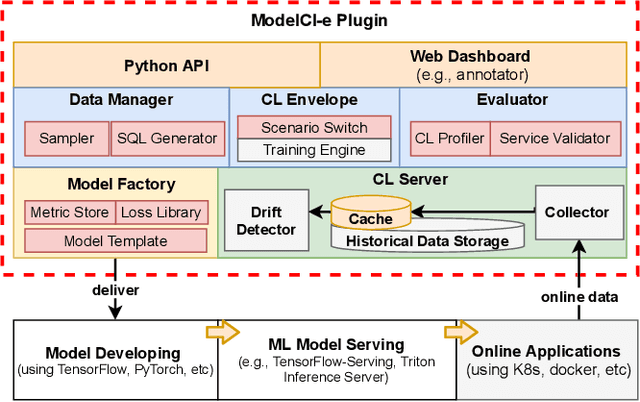
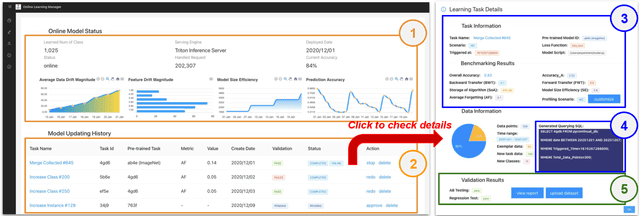

MLOps is about taking experimental ML models to production, i.e., serving the models to actual users. Unfortunately, existing ML serving systems do not adequately handle the dynamic environments in which online data diverges from offline training data, resulting in tedious model updating and deployment works. This paper implements a lightweight MLOps plugin, termed ModelCI-e (continuous integration and evolution), to address the issue. Specifically, it embraces continual learning (CL) and ML deployment techniques, providing end-to-end supports for model updating and validation without serving engine customization. ModelCI-e includes 1) a model factory that allows CL researchers to prototype and benchmark CL models with ease, 2) a CL backend to automate and orchestrate the model updating efficiently, and 3) a web interface for an ML team to manage CL service collaboratively. Our preliminary results demonstrate the usability of ModelCI-e, and indicate that eliminating the interference between model updating and inference workloads is crucial for higher system efficiency.
A Serverless Cloud-Fog Platform for DNN-Based Video Analytics with Incremental Learning
Feb 05, 2021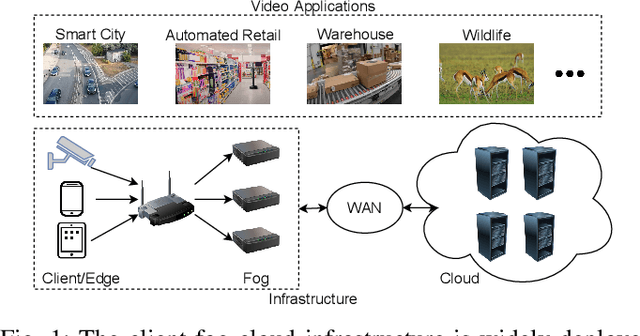
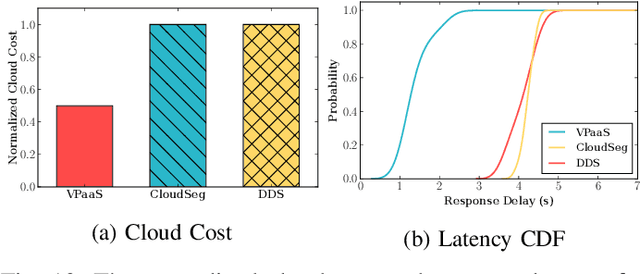
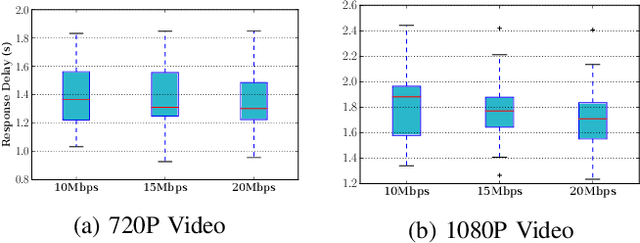
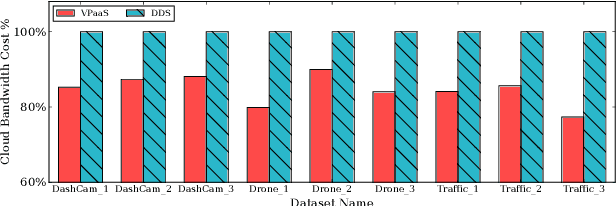
DNN-based video analytics have empowered many new applications (e.g., automated retail). Meanwhile, the proliferation of fog devices provides developers with more design options to improve performance and save cost. To the best of our knowledge, this paper presents the first serverless system that takes full advantage of the client-fog-cloud synergy to better serve the DNN-based video analytics. Specifically, the system aims to achieve two goals: 1) Provide the optimal analytics results under the constraints of lower bandwidth usage and shorter round-trip time (RTT) by judiciously managing the computational and bandwidth resources deployed in the client, fog, and cloud environment. 2) Free developers from tedious administration and operation tasks, including DNN deployment, cloud and fog's resource management. To this end, we implement a holistic cloud-fog system referred to as VPaaS (Video-Platform-as-a-Service). VPaaS adopts serverless computing to enable developers to build a video analytics pipeline by simply programming a set of functions (e.g., model inference), which are then orchestrated to process videos through carefully designed modules. To save bandwidth and reduce RTT, VPaaS provides a new video streaming protocol that only sends low-quality video to the cloud. The state-of-the-art (SOTA) DNNs deployed at the cloud can identify regions of video frames that need further processing at the fog ends. At the fog ends, misidentified labels in these regions can be corrected using a light-weight DNN model. To address the data drift issues, we incorporate limited human feedback into the system to verify the results and adopt incremental learning to improve our system continuously. The evaluation demonstrates that VPaaS is superior to several SOTA systems: it maintains high accuracy while reducing bandwidth usage by up to 21%, RTT by up to 62.5%, and cloud monetary cost by up to 50%.
No more 996: Understanding Deep Learning Inference Serving with an Automatic Benchmarking System
Nov 12, 2020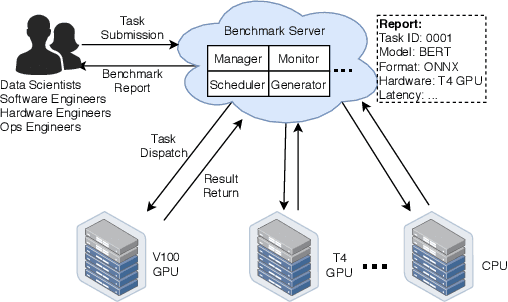

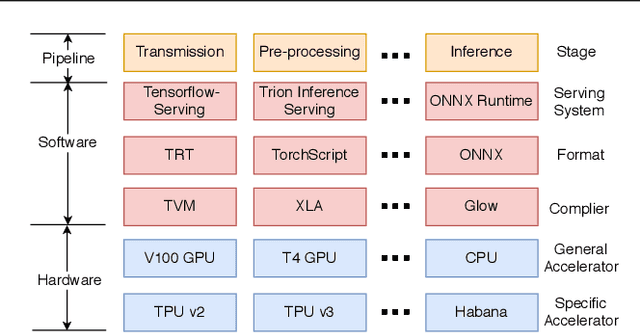
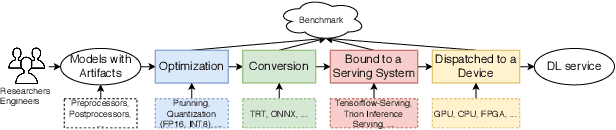
Deep learning (DL) models have become core modules for many applications. However, deploying these models without careful performance benchmarking that considers both hardware and software's impact often leads to poor service and costly operational expenditure. To facilitate DL models' deployment, we implement an automatic and comprehensive benchmark system for DL developers. To accomplish benchmark-related tasks, the developers only need to prepare a configuration file consisting of a few lines of code. Our system, deployed to a leader server in DL clusters, will dispatch users' benchmark jobs to follower workers. Next, the corresponding requests, workload, and even models can be generated automatically by the system to conduct DL serving benchmarks. Finally, developers can leverage many analysis tools and models in our system to gain insights into the trade-offs of different system configurations. In addition, a two-tier scheduler is incorporated to avoid unnecessary interference and improve average job compilation time by up to 1.43x (equivalent of 30\% reduction). Our system design follows the best practice in DL clusters operations to expedite day-to-day DL service evaluation efforts by the developers. We conduct many benchmark experiments to provide in-depth and comprehensive evaluations. We believe these results are of great values as guidelines for DL service configuration and resource allocation.
MLModelCI: An Automatic Cloud Platform for Efficient MLaaS
Jun 09, 2020



MLModelCI provides multimedia researchers and developers with a one-stop platform for efficient machine learning (ML) services. The system leverages DevOps techniques to optimize, test, and manage models. It also containerizes and deploys these optimized and validated models as cloud services (MLaaS). In its essence, MLModelCI serves as a housekeeper to help users publish models. The models are first automatically converted to optimized formats for production purpose and then profiled under different settings (e.g., batch size and hardware). The profiling information can be used as guidelines for balancing the trade-off between performance and cost of MLaaS. Finally, the system dockerizes the models for ease of deployment to cloud environments. A key feature of MLModelCI is the implementation of a controller, which allows elastic evaluation which only utilizes idle workers while maintaining online service quality. Our system bridges the gap between current ML training and serving systems and thus free developers from manual and tedious work often associated with service deployment. We release the platform as an open-source project on GitHub under Apache 2.0 license, with the aim that it will facilitate and streamline more large-scale ML applications and research projects.