 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024

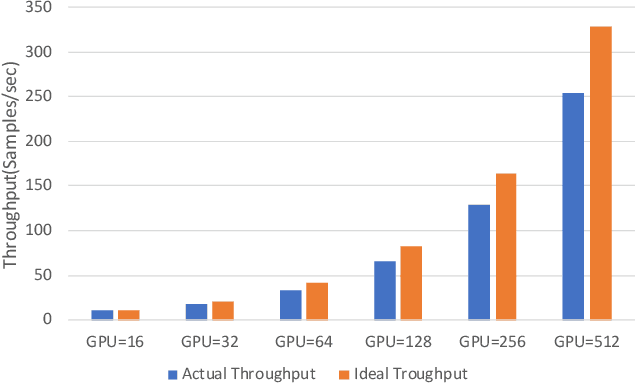

The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
Llumnix: Dynamic Scheduling for Large Language Model Serving
Jun 05, 2024


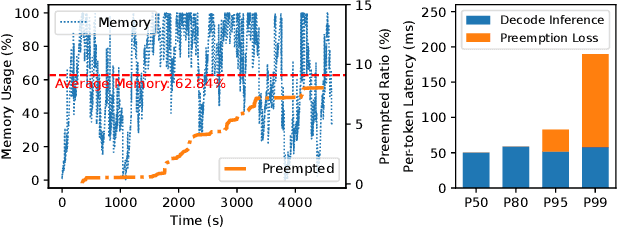
Inference serving for large language models (LLMs) is the key to unleashing their potential in people's daily lives. However, efficient LLM serving remains challenging today because the requests are inherently heterogeneous and unpredictable in terms of resource and latency requirements, as a result of the diverse applications and the dynamic execution nature of LLMs. Existing systems are fundamentally limited in handling these characteristics and cause problems such as severe queuing delays, poor tail latencies, and SLO violations. We introduce Llumnix, an LLM serving system that reacts to such heterogeneous and unpredictable requests by runtime rescheduling across multiple model instances. Similar to context switching across CPU cores in modern operating systems, Llumnix reschedules requests to improve load balancing and isolation, mitigate resource fragmentation, and differentiate request priorities and SLOs. Llumnix implements the rescheduling with an efficient and scalable live migration mechanism for requests and their in-memory states, and exploits it in a dynamic scheduling policy that unifies the multiple rescheduling scenarios elegantly. Our evaluations show that Llumnix improves tail latencies by an order of magnitude, accelerates high-priority requests by up to 1.5x, and delivers up to 36% cost savings while achieving similar tail latencies, compared against state-of-the-art LLM serving systems. Llumnix is publicly available at https://github.com/AlibabaPAI/llumnix.
FusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
MIGPerf: A Comprehensive Benchmark for Deep Learning Training and Inference Workloads on Multi-Instance GPUs
Jan 01, 2023New architecture GPUs like A100 are now equipped with multi-instance GPU (MIG) technology, which allows the GPU to be partitioned into multiple small, isolated instances. This technology provides more flexibility for users to support both deep learning training and inference workloads, but efficiently utilizing it can still be challenging. The vision of this paper is to provide a more comprehensive and practical benchmark study for MIG in order to eliminate the need for tedious manual benchmarking and tuning efforts. To achieve this vision, the paper presents MIGPerf, an open-source tool that streamlines the benchmark study for MIG. Using MIGPerf, the authors conduct a series of experiments, including deep learning training and inference characterization on MIG, GPU sharing characterization, and framework compatibility with MIG. The results of these experiments provide new insights and guidance for users to effectively employ MIG, and lay the foundation for further research on the orchestration of hybrid training and inference workloads on MIGs. The code and results are released on https://github.com/MLSysOps/MIGProfiler. This work is still in progress and more results will be published soon.
Focusing More on Conflicts with Mis-Predictions Helps Language Pre-Training
Dec 16, 2020

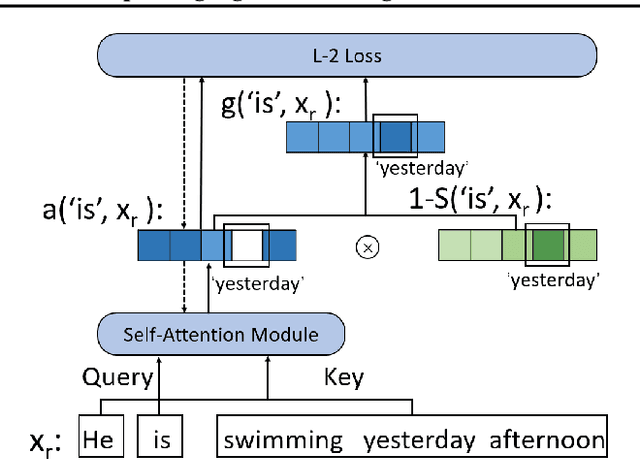

In this work, we propose to improve the effectiveness of language pre-training methods with the help of mis-predictions during pre-training. Neglecting words in the input sentence that have conflicting semantics with mis-predictions is likely to be the reason of generating mis-predictions at pre-training. Therefore, we hypothesis that mis-predictions during pre-training can act as detectors of the ill focuses of the model. If we train the model to focus more on the conflicts with the mis-predictions while focus less on the rest words in the input sentence, the mis-predictions can be more easily corrected and the entire model could be better trained. Towards this end, we introduce Focusing Less on Context of Mis-predictions(McMisP). In McMisP, we record the co-occurrence information between words to detect the conflicting words with mis-predictions in an unsupervised way. Then McMisP uses such information to guide the attention modules when a mis-prediction occurs. Specifically, several attention modules in the Transformer are optimized to focus more on words in the input sentence that have co-occurred rarely with the mis-predictions and vice versa. Results show that McMisP significantly expedites BERT and ELECTRA and improves their performances on downstream tasks.
Balanced Sparsity for Efficient DNN Inference on GPU
Nov 02, 2018



In trained deep neural networks, unstructured pruning can reduce redundant weights to lower storage cost. However, it requires the customization of hardwares to speed up practical inference. Another trend accelerates sparse model inference on general-purpose hardwares by adopting coarse-grained sparsity to prune or regularize consecutive weights for efficient computation. But this method often sacrifices model accuracy. In this paper, we propose a novel fine-grained sparsity approach, balanced sparsity, to achieve high model accuracy with commercial hardwares efficiently. Our approach adapts to high parallelism property of GPU, showing incredible potential for sparsity in the widely deployment of deep learning services. Experiment results show that balanced sparsity achieves up to 3.1x practical speedup for model inference on GPU, while retains the same high model accuracy as fine-grained sparsity.