 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
Long-term Microscopic Traffic Simulation with History-Masked Multi-agent Imitation Learning
Jun 10, 2023



A realistic long-term microscopic traffic simulator is necessary for understanding how microscopic changes affect traffic patterns at a larger scale. Traditional simulators that model human driving behavior with heuristic rules often fail to achieve accurate simulations due to real-world traffic complexity. To overcome this challenge, researchers have turned to neural networks, which are trained through imitation learning from human driver demonstrations. However, existing learning-based microscopic simulators often fail to generate stable long-term simulations due to the \textit{covariate shift} issue. To address this, we propose a history-masked multi-agent imitation learning method that removes all vehicles' historical trajectory information and applies perturbation to their current positions during learning. We apply our approach specifically to the urban traffic simulation problem and evaluate it on the real-world large-scale pNEUMA dataset, achieving better short-term microscopic and long-term macroscopic similarity to real-world data than state-of-the-art baselines.
An Intelligent Self-driving Truck System For Highway Transportation
Dec 31, 2021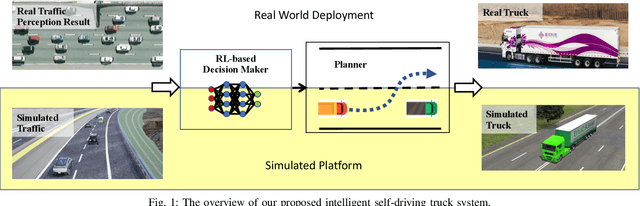
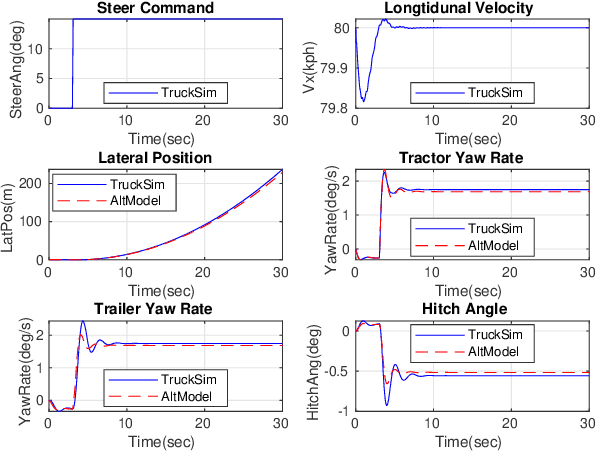
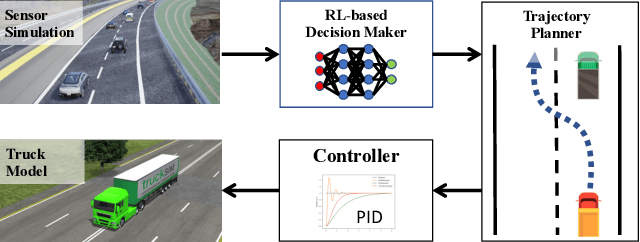
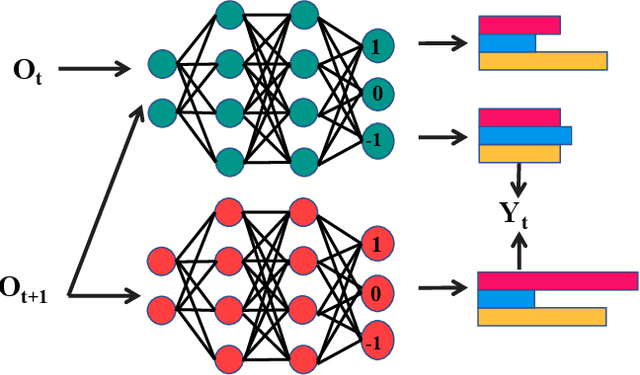
Recently, there have been many advances in autonomous driving society, attracting a lot of attention from academia and industry. However, existing works mainly focus on cars, extra development is still required for self-driving truck algorithms and models. In this paper, we introduce an intelligent self-driving truck system. Our presented system consists of three main components, 1) a realistic traffic simulation module for generating realistic traffic flow in testing scenarios, 2) a high-fidelity truck model which is designed and evaluated for mimicking real truck response in real-world deployment, 3) an intelligent planning module with learning-based decision making algorithm and multi-mode trajectory planner, taking into account the truck's constraints, road slope changes, and the surrounding traffic flow. We provide quantitative evaluations for each component individually to demonstrate the fidelity and performance of each part. We also deploy our proposed system on a real truck and conduct real world experiments which shows our system's capacity of mitigating sim-to-real gap. Our code is available at https://github.com/InceptioResearch/IITS
A Vision-based Irregular Obstacle Avoidance Framework via Deep Reinforcement Learning
Aug 23, 2021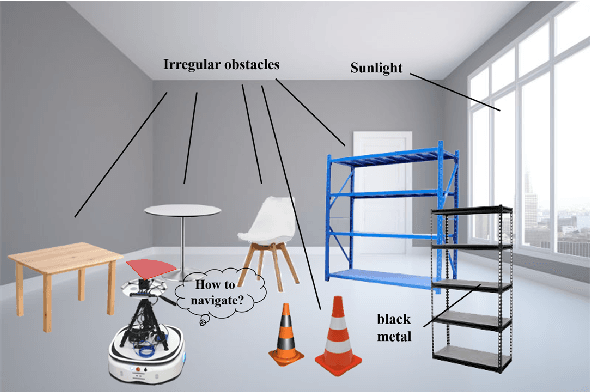
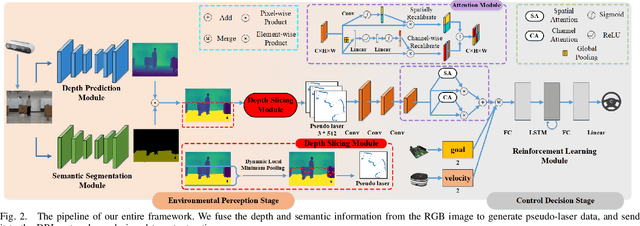

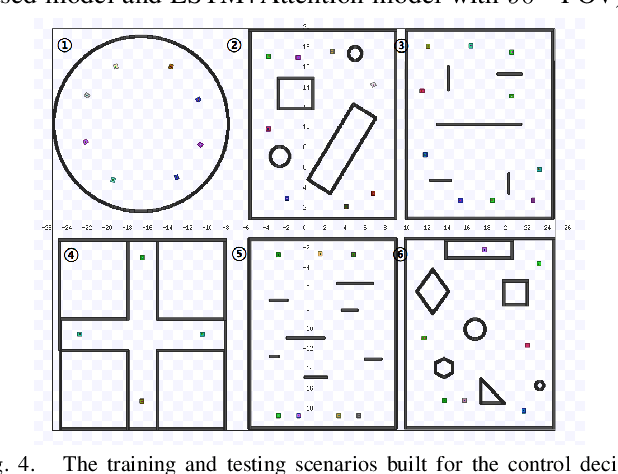
Deep reinforcement learning has achieved great success in laser-based collision avoidance work because the laser can sense accurate depth information without too much redundant data, which can maintain the robustness of the algorithm when it is migrated from the simulation environment to the real world. However, high-cost laser devices are not only difficult to apply on a large scale but also have poor robustness to irregular objects, e.g., tables, chairs, shelves, etc. In this paper, we propose a vision-based collision avoidance framework to solve the challenging problem. Our method attempts to estimate the depth and incorporate the semantic information from RGB data to obtain a new form of data, pseudo-laser data, which combines the advantages of visual information and laser information. Compared to traditional laser data that only contains the one-dimensional distance information captured at a certain height, our proposed pseudo-laser data encodes the depth information and semantic information within the image, which makes our method more effective for irregular obstacles. Besides, we adaptively add noise to the laser data during the training stage to increase the robustness of our model in the real world, due to the estimated depth information is not accurate. Experimental results show that our framework achieves state-of-the-art performance in several unseen virtual and real-world scenarios.