 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Long-Context Vision-Language Models Effectively with Generalization Beyond 128K Context
May 13, 2026Long-context modeling is becoming a core capability of modern large vision-language models (LVLMs), enabling sustained context management across long-document understanding, video analysis, and multi-turn tool use in agentic workflows. Yet practical training recipes remain insufficiently explored, particularly for designing and balancing long-context data mixtures. In this work, we present a systematic study of long-context continued pre-training for LVLMs, extending a 7B model from 32K to 128K context with extensive ablations on long-document data. We first show that long-document VQA is substantially more effective than OCR transcription. Building on this observation, our ablations further yield three key findings: i) for sequence-length distribution, balanced data outperforms target-length-focused data (e.g., 128K), suggesting that long-context ability requires generalizable key-information retrieval across various lengths and positions; ii) retrieval remains the primary bottleneck, favoring retrieval-heavy mixtures with modest reasoning data for task diversity; and iii) pure long-document VQA largely preserves short-context capabilities, suggesting that instruction-formatted long data reduces the need for short-data mixing. Based on these findings, we introduce MMProLong, obtained by long-context continued pre-training from Qwen2.5-VL-7B with only a 5B-token budget. MMProLong improves long-document VQA scores by 7.1% and maintains strong performance at 256K and 512K contexts beyond its 128K training window, without additional training. It further generalizes to webpage-based multimodal needle retrieval, long-context vision-text compression, and long-video understanding without task-specific supervision. Overall, our study establishes a practical LongPT recipe and an empirical foundation for advancing long-context vision-language models.
WildDoc: How Far Are We from Achieving Comprehensive and Robust Document Understanding in the Wild?
May 16, 2025The rapid advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced capabilities in Document Understanding. However, prevailing benchmarks like DocVQA and ChartQA predominantly comprise \textit{scanned or digital} documents, inadequately reflecting the intricate challenges posed by diverse real-world scenarios, such as variable illumination and physical distortions. This paper introduces WildDoc, the inaugural benchmark designed specifically for assessing document understanding in natural environments. WildDoc incorporates a diverse set of manually captured document images reflecting real-world conditions and leverages document sources from established benchmarks to facilitate comprehensive comparisons with digital or scanned documents. Further, to rigorously evaluate model robustness, each document is captured four times under different conditions. Evaluations of state-of-the-art MLLMs on WildDoc expose substantial performance declines and underscore the models' inadequate robustness compared to traditional benchmarks, highlighting the unique challenges posed by real-world document understanding. Our project homepage is available at https://bytedance.github.io/WildDoc.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving
Mar 15, 2025End-to-end autonomous driving (E2E-AD) has rapidly emerged as a promising approach toward achieving full autonomy. However, existing E2E-AD systems typically adopt a traditional multi-task framework, addressing perception, prediction, and planning tasks through separate task-specific heads. Despite being trained in a fully differentiable manner, they still encounter issues with task coordination, and the system complexity remains high. In this work, we introduce DiffAD, a novel diffusion probabilistic model that redefines autonomous driving as a conditional image generation task. By rasterizing heterogeneous targets onto a unified bird's-eye view (BEV) and modeling their latent distribution, DiffAD unifies various driving objectives and jointly optimizes all driving tasks in a single framework, significantly reducing system complexity and harmonizing task coordination. The reverse process iteratively refines the generated BEV image, resulting in more robust and realistic driving behaviors. Closed-loop evaluations in Carla demonstrate the superiority of the proposed method, achieving a new state-of-the-art Success Rate and Driving Score. The code will be made publicly available.
Text-Guided Multi-Property Molecular Optimization with a Diffusion Language Model
Oct 17, 2024Molecular optimization (MO) is a crucial stage in drug discovery in which task-oriented generated molecules are optimized to meet practical industrial requirements. Existing mainstream MO approaches primarily utilize external property predictors to guide iterative property optimization. However, learning all molecular samples in the vast chemical space is unrealistic for predictors. As a result, errors and noise are inevitably introduced during property prediction due to the nature of approximation. This leads to discrepancy accumulation, generalization reduction and suboptimal molecular candidates. In this paper, we propose a text-guided multi-property molecular optimization method utilizing transformer-based diffusion language model (TransDLM). TransDLM leverages standardized chemical nomenclature as semantic representations of molecules and implicitly embeds property requirements into textual descriptions, thereby preventing error propagation during diffusion process. Guided by physically and chemically detailed textual descriptions, TransDLM samples and optimizes encoded source molecules, retaining core scaffolds of source molecules and ensuring structural similarities. Moreover, TransDLM enables simultaneous sampling of multiple molecules, making it ideal for scalable, efficient large-scale optimization through distributed computation on web platforms. Furthermore, our approach surpasses state-of-the-art methods in optimizing molecular structural similarity and enhancing chemical properties on the benchmark dataset. The code is available at: https://anonymous.4open.science/r/TransDLM-A901.
LASIL: Learner-Aware Supervised Imitation Learning For Long-term Microscopic Traffic Simulation
Apr 08, 2024



Microscopic traffic simulation plays a crucial role in transportation engineering by providing insights into individual vehicle behavior and overall traffic flow. However, creating a realistic simulator that accurately replicates human driving behaviors in various traffic conditions presents significant challenges. Traditional simulators relying on heuristic models often fail to deliver accurate simulations due to the complexity of real-world traffic environments. Due to the covariate shift issue, existing imitation learning-based simulators often fail to generate stable long-term simulations. In this paper, we propose a novel approach called learner-aware supervised imitation learning to address the covariate shift problem in multi-agent imitation learning. By leveraging a variational autoencoder simultaneously modeling the expert and learner state distribution, our approach augments expert states such that the augmented state is aware of learner state distribution. Our method, applied to urban traffic simulation, demonstrates significant improvements over existing state-of-the-art baselines in both short-term microscopic and long-term macroscopic realism when evaluated on the real-world dataset pNEUMA.
Coverage-Guaranteed Prediction Sets for Out-of-Distribution Data
Mar 29, 2024


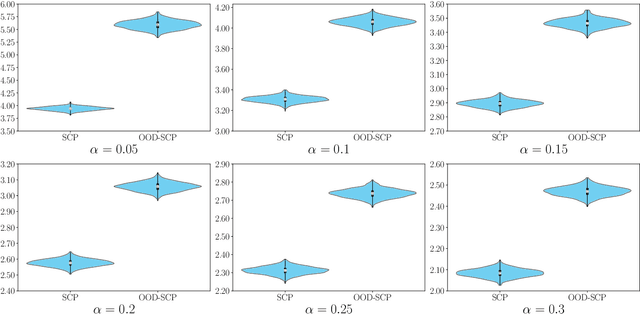
Out-of-distribution (OOD) generalization has attracted increasing research attention in recent years, due to its promising experimental results in real-world applications. In this paper,we study the confidence set prediction problem in the OOD generalization setting. Split conformal prediction (SCP) is an efficient framework for handling the confidence set prediction problem. However, the validity of SCP requires the examples to be exchangeable, which is violated in the OOD setting. Empirically, we show that trivially applying SCP results in a failure to maintain the marginal coverage when the unseen target domain is different from the source domain. To address this issue, we develop a method for forming confident prediction sets in the OOD setting and theoretically prove the validity of our method. Finally, we conduct experiments on simulated data to empirically verify the correctness of our theory and the validity of our proposed method.
Long-term Microscopic Traffic Simulation with History-Masked Multi-agent Imitation Learning
Jun 10, 2023



A realistic long-term microscopic traffic simulator is necessary for understanding how microscopic changes affect traffic patterns at a larger scale. Traditional simulators that model human driving behavior with heuristic rules often fail to achieve accurate simulations due to real-world traffic complexity. To overcome this challenge, researchers have turned to neural networks, which are trained through imitation learning from human driver demonstrations. However, existing learning-based microscopic simulators often fail to generate stable long-term simulations due to the \textit{covariate shift} issue. To address this, we propose a history-masked multi-agent imitation learning method that removes all vehicles' historical trajectory information and applies perturbation to their current positions during learning. We apply our approach specifically to the urban traffic simulation problem and evaluate it on the real-world large-scale pNEUMA dataset, achieving better short-term microscopic and long-term macroscopic similarity to real-world data than state-of-the-art baselines.
Deep Partial Multi-Label Learning with Graph Disambiguation
May 10, 2023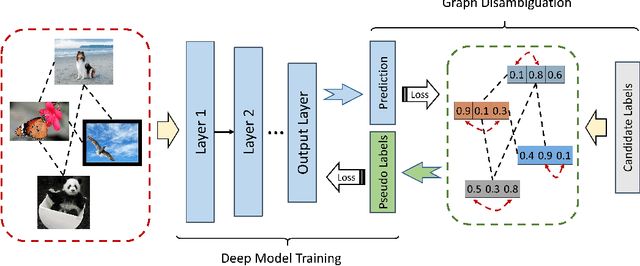
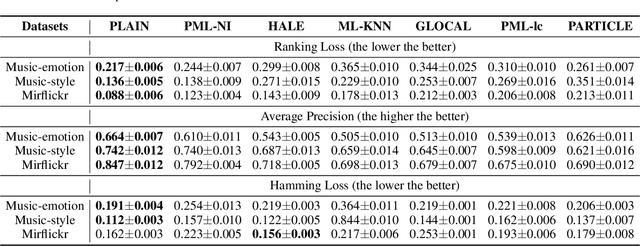

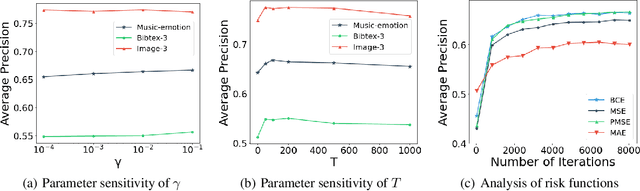
In partial multi-label learning (PML), each data example is equipped with a candidate label set, which consists of multiple ground-truth labels and other false-positive labels. Recently, graph-based methods, which demonstrate a good ability to estimate accurate confidence scores from candidate labels, have been prevalent to deal with PML problems. However, we observe that existing graph-based PML methods typically adopt linear multi-label classifiers and thus fail to achieve superior performance. In this work, we attempt to remove several obstacles for extending them to deep models and propose a novel deep Partial multi-Label model with grAph-disambIguatioN (PLAIN). Specifically, we introduce the instance-level and label-level similarities to recover label confidences as well as exploit label dependencies. At each training epoch, labels are propagated on the instance and label graphs to produce relatively accurate pseudo-labels; then, we train the deep model to fit the numerical labels. Moreover, we provide a careful analysis of the risk functions to guarantee the robustness of the proposed model. Extensive experiments on various synthetic datasets and three real-world PML datasets demonstrate that PLAIN achieves significantly superior results to state-of-the-art methods.
Generalization Bounds for Adversarial Contrastive Learning
Feb 21, 2023

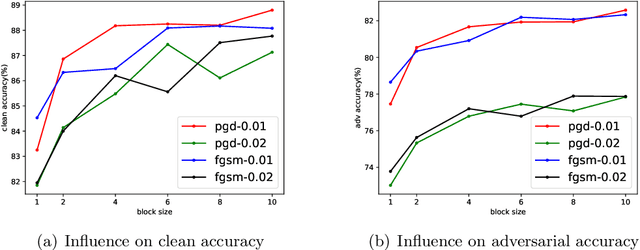

Deep networks are well-known to be fragile to adversarial attacks, and adversarial training is one of the most popular methods used to train a robust model. To take advantage of unlabeled data, recent works have applied adversarial training to contrastive learning (Adversarial Contrastive Learning; ACL for short) and obtain promising robust performance. However, the theory of ACL is not well understood. To fill this gap, we leverage the Rademacher complexity to analyze the generalization performance of ACL, with a particular focus on linear models and multi-layer neural networks under $\ell_p$ attack ($p \ge 1$). Our theory shows that the average adversarial risk of the downstream tasks can be upper bounded by the adversarial unsupervised risk of the upstream task. The experimental results validate our theory.