 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Partial Multi-Label Learning with Graph Disambiguation
May 10, 2023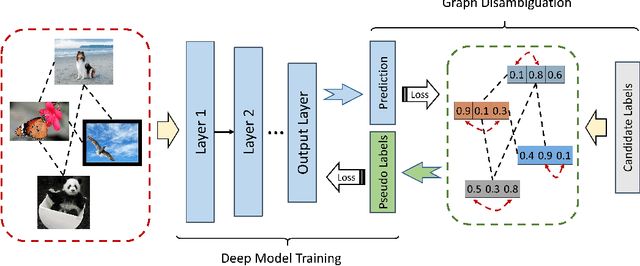
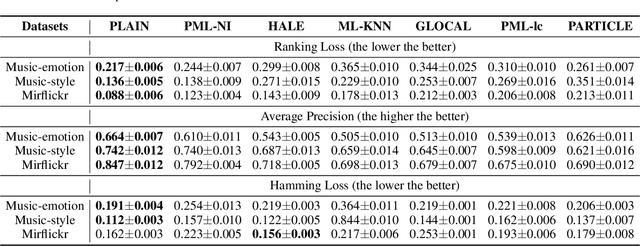

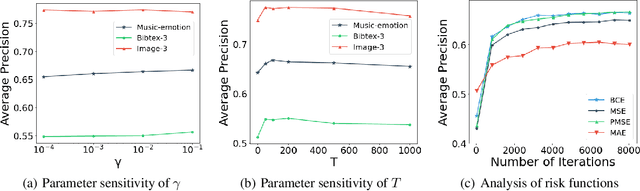
In partial multi-label learning (PML), each data example is equipped with a candidate label set, which consists of multiple ground-truth labels and other false-positive labels. Recently, graph-based methods, which demonstrate a good ability to estimate accurate confidence scores from candidate labels, have been prevalent to deal with PML problems. However, we observe that existing graph-based PML methods typically adopt linear multi-label classifiers and thus fail to achieve superior performance. In this work, we attempt to remove several obstacles for extending them to deep models and propose a novel deep Partial multi-Label model with grAph-disambIguatioN (PLAIN). Specifically, we introduce the instance-level and label-level similarities to recover label confidences as well as exploit label dependencies. At each training epoch, labels are propagated on the instance and label graphs to produce relatively accurate pseudo-labels; then, we train the deep model to fit the numerical labels. Moreover, we provide a careful analysis of the risk functions to guarantee the robustness of the proposed model. Extensive experiments on various synthetic datasets and three real-world PML datasets demonstrate that PLAIN achieves significantly superior results to state-of-the-art methods.
GM-MLIC: Graph Matching based Multi-Label Image Classification
May 07, 2021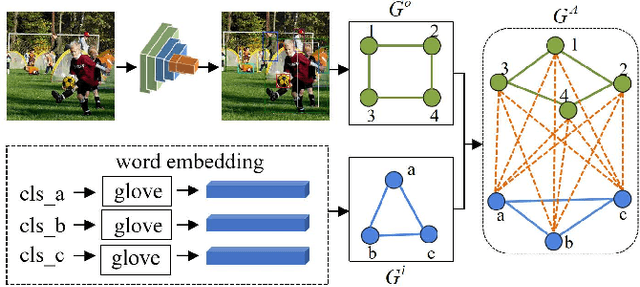
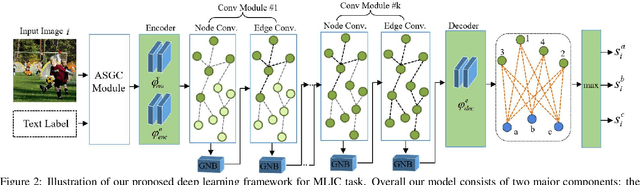
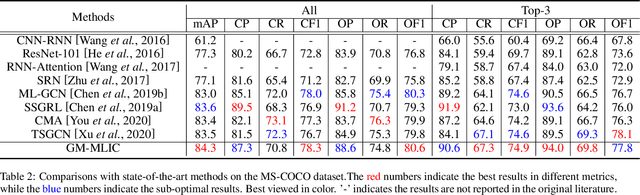
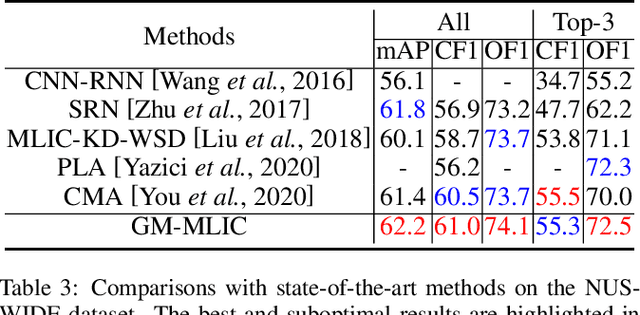
Multi-Label Image Classification (MLIC) aims to predict a set of labels that present in an image. The key to deal with such problem is to mine the associations between image contents and labels, and further obtain the correct assignments between images and their labels. In this paper, we treat each image as a bag of instances, and reformulate the task of MLIC as an instance-label matching selection problem. To model such problem, we propose a novel deep learning framework named Graph Matching based Multi-Label Image Classification (GM-MLIC), where Graph Matching (GM) scheme is introduced owing to its excellent capability of excavating the instance and label relationship. Specifically, we first construct an instance spatial graph and a label semantic graph respectively, and then incorporate them into a constructed assignment graph by connecting each instance to all labels. Subsequently, the graph network block is adopted to aggregate and update all nodes and edges state on the assignment graph to form structured representations for each instance and label. Our network finally derives a prediction score for each instance-label correspondence and optimizes such correspondence with a weighted cross-entropy loss. Extensive experiments conducted on various image datasets demonstrate the superiority of our proposed method.
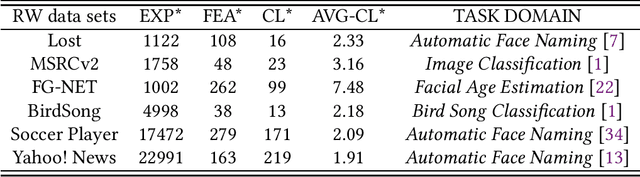
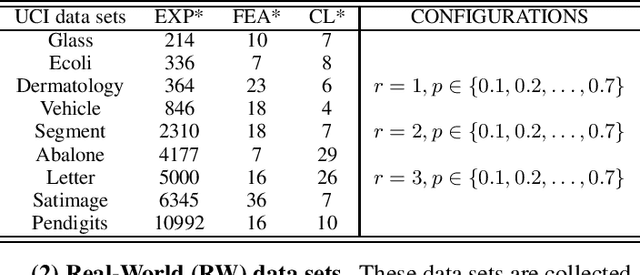
HERA: Partial Label Learning by Combining Heterogeneous Loss with Sparse and Low-Rank Regularization
Jun 03, 2019
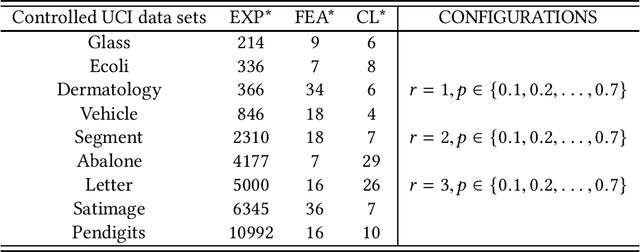
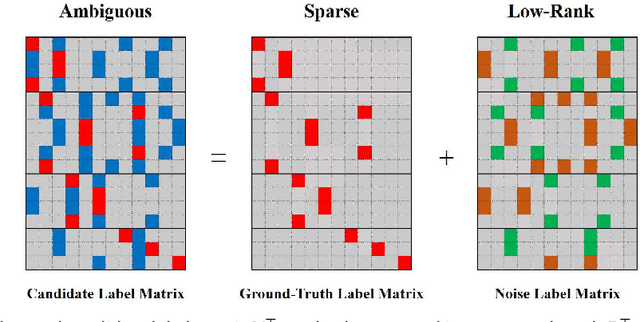
Partial Label Learning (PLL) aims to learn from the data where each training instance is associated with a set of candidate labels, among which only one is correct. Most existing methods deal with such problem by either treating each candidate label equally or identifying the ground-truth label iteratively. In this paper, we propose a novel PLL approach called HERA, which simultaneously incorporates the HeterogEneous Loss and the SpaRse and Low-rAnk procedure to estimate the labeling confidence for each instance while training the model. Specifically, the heterogeneous loss integrates the strengths of both the pairwise ranking loss and the pointwise reconstruction loss to provide informative label ranking and reconstruction information for label identification, while the embedded sparse and low-rank scheme constrains the sparsity of ground-truth label matrix and the low rank of noise label matrix to explore the global label relevance among the whole training data for improving the learning model. Extensive experiments on both artificial and real-world data sets demonstrate that our method can achieve superior or comparable performance against the state-of-the-art methods.
GM-PLL: Graph Matching based Partial Label Learning
Jan 10, 2019
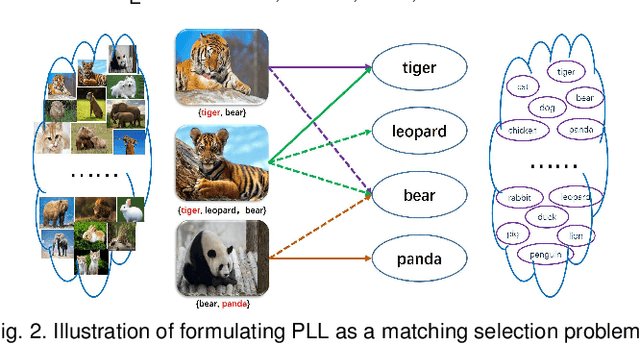
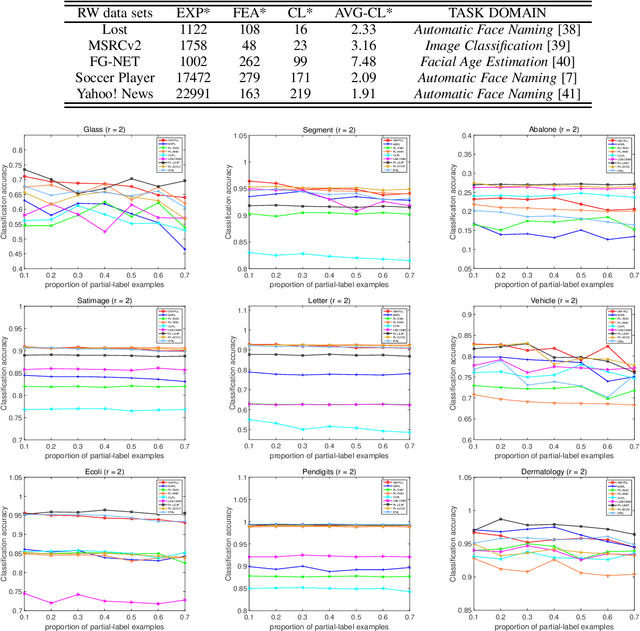
Partial Label Learning (PLL) aims to learn from the data where each training example is associated with a set of candidate labels, among which only one is correct. The key to deal with such problem is to disambiguate the candidate label sets and obtain the correct assignments between instances and their candidate labels. In this paper, we interpret such assignments as instance-to-label matchings, and reformulate the task of PLL as a matching selection problem. To model such problem, we propose a novel Graph Matching based Partial Label Learning (GM-PLL) framework, where Graph Matching (GM) scheme is incorporated owing to its excellent capability of exploiting the instance and label relationship. Meanwhile, since conventional one-to-one GM algorithm does not satisfy the constraint of PLL problem that multiple instances may correspond to the same label, we extend a traditional one-to-one probabilistic matching algorithm to the many-to-one constraint, and make the proposed framework accommodate to the PLL problem. Moreover, we also propose a relaxed matching prediction model, which can improve the prediction accuracy via GM strategy. Extensive experiments on both artificial and real-world data sets demonstrate that the proposed method can achieve superior or comparable performance against the state-of-the-art methods.
A Self-paced Regularization Framework for Partial-Label Learning
May 08, 2018

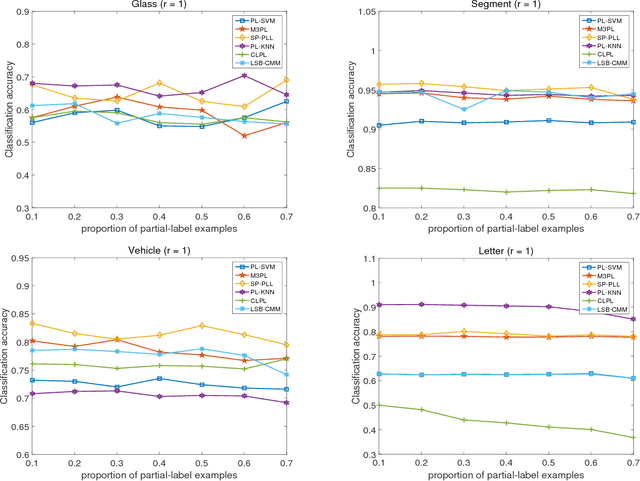
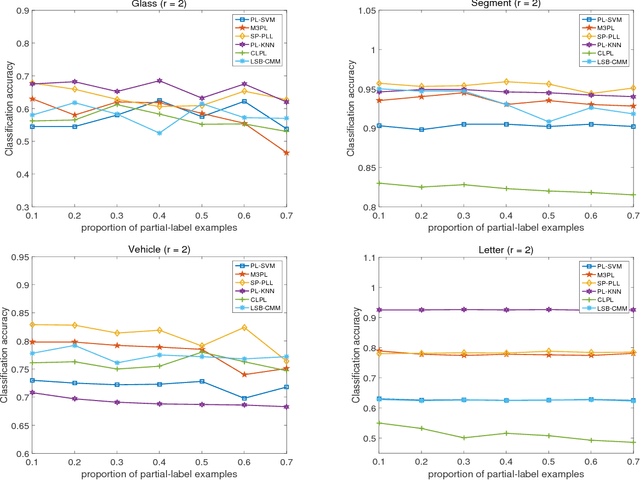
Partial label learning (PLL) aims to solve the problem where each training instance is associated with a set of candidate labels, one of which is the correct label. Most PLL algorithms try to disambiguate the candidate label set, by either simply treating each candidate label equally or iteratively identifying the true label. Nonetheless, existing algorithms usually treat all labels and instances equally, and the complexities of both labels and instances are not taken into consideration during the learning stage. Inspired by the successful application of self-paced learning strategy in machine learning field, we integrate the self-paced regime into the partial label learning framework and propose a novel Self-Paced Partial-Label Learning (SP-PLL) algorithm, which could control the learning process to alleviate the problem by ranking the priorities of the training examples together with their candidate labels during each learning iteration. Extensive experiments and comparisons with other baseline methods demonstrate the effectiveness and robustness of the proposed method.