 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Cross-domain Videos with Video Prediction Model
Jun 03, 2026Reinforcement learning from expert videos across visually distinct domains is challenging due to the absence of reward signals and the presence of domain gaps. We introduce XIPER (Cross-domain Video Prediction Reward), a reward model for learning from expert videos collected in a visually different domain, where the agent's appearance differs due to factors such as color, morphology, or the sim-to-real gap. More specifically, XIPER trains a cross-domain video prediction model that maps agent observations into the expert domain and uses the prediction likelihood as a reward signal. Experiments on the DMC Color Suite (8 tasks) and DMC Body Suite (3 tasks) show that XIPER consistently outperforms baselines despite domain gaps such as differences in agent color and morphology. We further analyze XIPER on a sim-to-real transfer dataset, demonstrating that it produces meaningful reward signals for real-robot observations given only simulated expert videos. Code, pretrained models, datasets and video demonstrations can be found on our project webpage: https://sites.google.com/view/xiper
SeClaw: Spec-Driven Security Task Synthesis for Evaluating Autonomous Agents
Jun 01, 2026Autonomous LLM agents increasingly operate in stateful environments where they access tools, files, memory, and external services. While such capabilities enable complex real-world workflows, they also introduce security risks that are difficult to capture with existing evaluations. Current agent security benchmarks often rely on manually curated tasks, provide limited coverage of emerging threats, and focus primarily on final outcomes rather than the execution processes that lead to unsafe behavior. We introduce SeClaw, a framework that combines specification-driven security task synthesis with execution-based security evaluation for Autonomous agents. Spec-driven security task synthesis enables scalable and controllable construction of security tasks from structured risk specifications, while SeClaw docker provides a standardized testbed for evaluating agent behavior under diverse safety-risk scenarios. The benchmark covers risks arising from resources, user tasks, environments, and intrinsic agent behaviors, and supports trajectory-aware assessment of unsafe actions beyond final responses. By bridging systematic task synthesis and reproducible security evaluation, SeClaw provides a practical foundation for measuring, diagnosing, and comparing security failures in autonomous LLM agents. The code is available at https://github.com/seclaw-eval/seclaw-eval.
HetCCL: Enabling Collective Communication For Mixed-Vendor Heterogeneous Clusters
May 29, 2026Training Large Language Models (LLMs) on heterogeneous clusters presents significant challenges for collective communication, as hardware from multiple vendors introduces diverse network and computational characteristics. Existing collective communication frameworks (e.g., NCCL, RCCL) designed for homogeneous environments fail to address mixed-hardware setups, while communication libraries with heterogeneous support (e.g., Gloo, OpenMPI) incur heavy overhead in the data path. This paper presents HetCCL, a framework that enables heterogeneous collective communication by efficient P2P transport across heterogeneous devices (e.g., GPUs), eliminating the host-device memory copy overhead while offloading the control to the CPUs. For combining collectives (e.g., AllReduce, ReduceScatter), HetCCL introduces a border-communicator mechanism that achieves vendor independence by using the intrinsic reduction in the combining collectives in vendor collective communication libraries. With efficient heterogeneous P2P transport and portable reduction mechanism, HetCCL proposes a hierarchical topology abstraction for heterogeneous clusters, dissecting collective communication into cluster-level primitives that guarantee optimal cross-cluster data transfer volume and optimal bandwidth utilization. We implement HetCCL with 4 different vendor support and evaluate it in 4 heterogeneous settings with benchmarks and end-to-end LLM tasks. Our evaluation shows that HetCCL achieves 17-19x higher bandwidth than Gloo in heterogeneous communications, and speeds up end-to-end training by up to 16.9% in the per-step-time.
Fast Online Learning with Gaussian Prior-Driven Hierarchical Unimodal Thompson Sampling
Feb 17, 2026We study a type of Multi-Armed Bandit (MAB) problems in which arms with a Gaussian reward feedback are clustered. Such an arm setting finds applications in many real-world problems, for example, mmWave communications and portfolio management with risky assets, as a result of the universality of the Gaussian distribution. Based on the Thompson Sampling algorithm with Gaussian prior (TSG) algorithm for the selection of the optimal arm, we propose our Thompson Sampling with Clustered arms under Gaussian prior (TSCG) specific to the 2-level hierarchical structure. We prove that by utilizing the 2-level structure, we can achieve a lower regret bound than we do with ordinary TSG. In addition, when the reward is Unimodal, we can reach an even lower bound on the regret by our Unimodal Thompson Sampling algorithm with Clustered Arms under Gaussian prior (UTSCG). Each of our proposed algorithms are accompanied by theoretical evaluation of the upper regret bound, and our numerical experiments confirm the advantage of our proposed algorithms.
GLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
Learning to Wait: Synchronizing Agents with the Physical World
Dec 18, 2025Real-world agentic tasks, unlike synchronous Markov Decision Processes (MDPs), often involve non-blocking actions with variable latencies, creating a fundamental \textit{Temporal Gap} between action initiation and completion. Existing environment-side solutions, such as blocking wrappers or frequent polling, either limit scalability or dilute the agent's context window with redundant observations. In this work, we propose an \textbf{Agent-side Approach} that empowers Large Language Models (LLMs) to actively align their \textit{Cognitive Timeline} with the physical world. By extending the Code-as-Action paradigm to the temporal domain, agents utilize semantic priors and In-Context Learning (ICL) to predict precise waiting durations (\texttt{time.sleep(t)}), effectively synchronizing with asynchronous environment without exhaustive checking. Experiments in a simulated Kubernetes cluster demonstrate that agents can precisely calibrate their internal clocks to minimize both query overhead and execution latency, validating that temporal awareness is a learnable capability essential for autonomous evolution in open-ended environments.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Precise Facial Landmark Detection by Dynamic Semantic Aggregation Transformer
Dec 01, 2024



At present, deep neural network methods have played a dominant role in face alignment field. However, they generally use predefined network structures to predict landmarks, which tends to learn general features and leads to mediocre performance, e.g., they perform well on neutral samples but struggle with faces exhibiting large poses or occlusions. Moreover, they cannot effectively deal with semantic gaps and ambiguities among features at different scales, which may hinder them from learning efficient features. To address the above issues, in this paper, we propose a Dynamic Semantic-Aggregation Transformer (DSAT) for more discriminative and representative feature (i.e., specialized feature) learning. Specifically, a Dynamic Semantic-Aware (DSA) model is first proposed to partition samples into subsets and activate the specific pathways for them by estimating the semantic correlations of feature channels, making it possible to learn specialized features from each subset. Then, a novel Dynamic Semantic Specialization (DSS) model is designed to mine the homogeneous information from features at different scales for eliminating the semantic gap and ambiguities and enhancing the representation ability. Finally, by integrating the DSA model and DSS model into our proposed DSAT in both dynamic architecture and dynamic parameter manners, more specialized features can be learned for achieving more precise face alignment. It is interesting to show that harder samples can be handled by activating more feature channels. Extensive experiments on popular face alignment datasets demonstrate that our proposed DSAT outperforms state-of-the-art models in the literature.Our code is available at https://github.com/GERMINO-LiuHe/DSAT.
Small Scale Data-Free Knowledge Distillation
Jun 12, 2024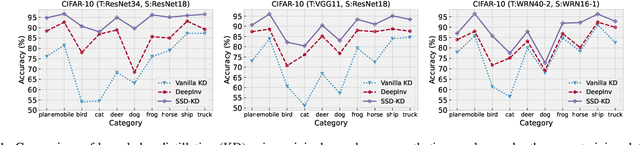

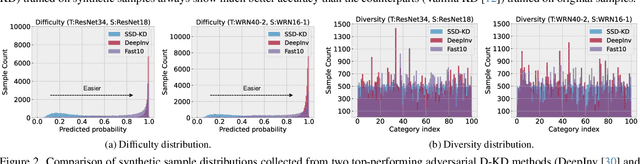

Data-free knowledge distillation is able to utilize the knowledge learned by a large teacher network to augment the training of a smaller student network without accessing the original training data, avoiding privacy, security, and proprietary risks in real applications. In this line of research, existing methods typically follow an inversion-and-distillation paradigm in which a generative adversarial network on-the-fly trained with the guidance of the pre-trained teacher network is used to synthesize a large-scale sample set for knowledge distillation. In this paper, we reexamine this common data-free knowledge distillation paradigm, showing that there is considerable room to improve the overall training efficiency through a lens of ``small-scale inverted data for knowledge distillation". In light of three empirical observations indicating the importance of how to balance class distributions in terms of synthetic sample diversity and difficulty during both data inversion and distillation processes, we propose Small Scale Data-free Knowledge Distillation SSD-KD. In formulation, SSD-KD introduces a modulating function to balance synthetic samples and a priority sampling function to select proper samples, facilitated by a dynamic replay buffer and a reinforcement learning strategy. As a result, SSD-KD can perform distillation training conditioned on an extremely small scale of synthetic samples (e.g., 10X less than the original training data scale), making the overall training efficiency one or two orders of magnitude faster than many mainstream methods while retaining superior or competitive model performance, as demonstrated on popular image classification and semantic segmentation benchmarks. The code is available at https://github.com/OSVAI/SSD-KD.
Transparent Object Depth Completion
May 24, 2024



The perception of transparent objects for grasp and manipulation remains a major challenge, because existing robotic grasp methods which heavily rely on depth maps are not suitable for transparent objects due to their unique visual properties. These properties lead to gaps and inaccuracies in the depth maps of the transparent objects captured by depth sensors. To address this issue, we propose an end-to-end network for transparent object depth completion that combines the strengths of single-view RGB-D based depth completion and multi-view depth estimation. Moreover, we introduce a depth refinement module based on confidence estimation to fuse predicted depth maps from single-view and multi-view modules, which further refines the restored depth map. The extensive experiments on the ClearPose and TransCG datasets demonstrate that our method achieves superior accuracy and robustness in complex scenarios with significant occlusion compared to the state-of-the-art methods.