 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ACUTE Protocol: Operationalizing Language Model Activations for Better Calibration, Utility, and Trust
Jun 05, 2026As language models improve and become increasingly deployed to solve a variety of tasks, trustworthiness becomes essential. Calibration is a good proxy for trust: well-calibrated confidence estimates help inform the risk versus reward tradeoff when trusting a specific model output. Unfortunately, even as models improve, they remain poorly calibrated, often biasing towards overconfidence. Additionally, calibration can be gamed: a policy that always predicts the base rate is perfectly calibrated, but completely uninformative. To resolve this, we develop a new metric, expected utility renormalized by the oracle (EURO), that balances calibration and informativeness. We also propose a general-purpose activation-based confidence, utility, and trust estimation protocol (ACUTE) to appropriately adjudicate uncertainty. The ACUTE protocol provides flexible, sample-efficient, and compute-efficient confidence estimators for 3 tasks including multiple choice question answering, tool-calling, and scientific document summarization across 6 models from 4 model families. ACUTE outperforms strong baselines on EURO, while maintaining low calibration error. Taken together, our work shows that equipping LLMs with the ACUTE protocol can improve calibration, utility, and trustworthiness in numerous settings.
PSEBench: A Controllable and Verifiable Benchmark for Evaluating LLMs in Patient Safety Event Triage
Jun 03, 2026Patient safety event triage, determining whether a clinical event is reportable under jurisdiction-specific policy, is a high-stakes task typically performed manually by patient safety experts. Although LLMs may support this workflow, reliable evaluation is limited by the lack of benchmarks to capture evidence-grounded policy reasoning, proactive information seeking for incomplete reports, and principled abstention in irreducibly ambiguous cases. We address this gap with a policy-grounded construction methodology centered on the clause card, a structured representation that factorizes regulatory text into auditable decision specifications. Combining clause cards with anchor-driven instantiation and closed-loop verification, our scalable pipeline produces narratives with by-construction ground truth and naturally supports generating missing information and uncertain variants. We instantiate this method on Minnesota's 29 Reportable Adverse Health Events, producing PSEBench, a 5,074-case benchmark with an agentic evaluation environment. Evaluation on 15 representative LLMs reveals consistent capability trends, demonstrates the benchmark's utility, and identifies actionable gaps toward reliable LLM-based patient safety event triage.
G-DRAGON: Geospatial Reasoning and Dynamic Planning for Retrieval-Augmented Outdoor Navigation
May 25, 2026Autonomous ground robots operating in large-scale outdoor environments require both robust long-range navigation and fine-grained ''last-mile'' exploration. Current advances in visual-language navigation (VLN) work well at short-range tasks, lacking geospatial grounding for long-distance missions. Some OpenStreetMap (OSM)-based methods relying on cloud-based Large Language Models (LLMs) are prone to factual hallucination and cannot conduct ''last-mile'' exploration based on human instruction. To address these challenges, we present G-DRAGON, a retrieval-augmented framework for outdoor, open-world navigation. This framework maps natural-language commands to versioned, local OSM entities via generative retrieval based on lightweight LLM, yielding accurate coordinates for global route planning. A high-level planning module bridges global topological routes with the SLAM system, projecting geospatial waypoints into the robot's navigable frame. For the ''last mile," the framework transitions to frontier-based exploration and open-set semantic voxel mapping to localize open-vocabulary targets. Experimental results in simulation demonstrate our framework outperforms state-of-the-art baselines. Furthermore, we validate the system in unseen real-world urban environments on an Unmanned Ground Vehicle (UGV), successfully completing person-search missions with trajectories of up to 500m.
Coverage, Not Averages: Semantic Stratification for Trustworthy Retrieval Evaluation
Apr 22, 2026Retrieval quality is the primary bottleneck for accuracy and robustness in retrieval-augmented generation (RAG). Current evaluation relies on heuristically constructed query sets, which introduce a hidden intrinsic bias. We formalize retrieval evaluation as a statistical estimation problem, showing that metric reliability is fundamentally limited by the evaluation-set construction. We further introduce \emph{semantic stratification}, which grounds evaluation in corpus structure by organizing documents into an interpretable global space of entity-based clusters and systematically generating queries for missing strata. This yields (1) formal semantic coverage guarantees across retrieval regimes and (2) interpretable visibility into retrieval failure modes. Experiments across multiple benchmarks and retrieval methods validate our framework. The results expose systematic coverage gaps, identify structural signals that explain variance in retrieval performance, and show that stratified evaluation yields more stable and transparent assessments while supporting more trustworthy decision-making than aggregate metrics.
MedCausalX: Adaptive Causal Reasoning with Self-Reflection for Trustworthy Medical Vision-Language Models
Mar 24, 2026Vision-Language Models (VLMs) have enabled interpretable medical diagnosis by integrating visual perception with linguistic reasoning. Yet, existing medical chain-of-thought (CoT) models lack explicit mechanisms to represent and enforce causal reasoning, leaving them vulnerable to spurious correlations and limiting their clinical reliability. We pinpoint three core challenges in medical CoT reasoning: how to adaptively trigger causal correction, construct high-quality causal-spurious contrastive samples, and maintain causal consistency across reasoning trajectories. To address these challenges, we propose MedCausalX, an end-to-end framework explicitly models causal reasoning chains in medical VLMs. We first introduce the CRMed dataset providing fine-grained anatomical annotations, structured causal reasoning chains, and counterfactual variants that guide the learning of causal relationships beyond superficial correlations. Building upon CRMed, MedCausalX employs a two-stage adaptive reflection architecture equipped with $\langle$causal$\rangle$ and $\langle$verify$\rangle$ tokens, enabling the model to autonomously determine when and how to perform causal analysis and verification. Finally, a trajectory-level causal correction objective optimized through error-attributed reinforcement learning refines the reasoning chain, allowing the model to distinguish genuine causal dependencies from shortcut associations. Extensive experiments on multiple benchmarks show that MedCausalX consistently outperforms state-of-the-art methods, improving diagnostic consistency by +5.4 points, reducing hallucination by over 10 points, and attaining top spatial grounding IoU, thereby setting a new standard for causally grounded medical reasoning.
LHAW: Controllable Underspecification for Long-Horizon Tasks
Feb 11, 2026Long-horizon workflow agents that operate effectively over extended periods are essential for truly autonomous systems. Their reliable execution critically depends on the ability to reason through ambiguous situations in which clarification seeking is necessary to ensure correct task execution. However, progress is limited by the lack of scalable, task-agnostic frameworks for systematically curating and measuring the impact of ambiguity across custom workflows. We address this gap by introducing LHAW (Long-Horizon Augmented Workflows), a modular, dataset-agnostic synthetic pipeline that transforms any well-specified task into controllable underspecified variants by systematically removing information across four dimensions - Goals, Constraints, Inputs, and Context - at configurable severity levels. Unlike approaches that rely on LLM predictions of ambiguity, LHAW validates variants through empirical agent trials, classifying them as outcome-critical, divergent, or benign based on observed terminal state divergence. We release 285 task variants from TheAgentCompany, SWE-Bench Pro and MCP-Atlas according to our taxonomy alongside formal analysis measuring how current agents detect, reason about, and resolve underspecification across ambiguous settings. LHAW provides the first systematic framework for cost-sensitive evaluation of agent clarification behavior in long-horizon settings, enabling development of reliable autonomous systems.
Atlas is Your Perfect Context: One-Shot Customization for Generalizable Foundational Medical Image Segmentation
Dec 20, 2025



Accurate medical image segmentation is essential for clinical diagnosis and treatment planning. While recent interactive foundation models (e.g., nnInteractive) enhance generalization through large-scale multimodal pretraining, they still depend on precise prompts and often perform below expectations in contexts that are underrepresented in their training data. We present AtlasSegFM, an atlas-guided framework that customizes available foundation models to clinical contexts with a single annotated example. The core innovations are: 1) a pipeline that provides context-aware prompts for foundation models via registration between a context atlas and query images, and 2) a test-time adapter to fuse predictions from both atlas registration and the foundation model. Extensive experiments across public and in-house datasets spanning multiple modalities and organs demonstrate that AtlasSegFM consistently improves segmentation, particularly for small, delicate structures. AtlasSegFM provides a lightweight, deployable solution one-shot customization of foundation models in real-world clinical workflows. The code will be made publicly available.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025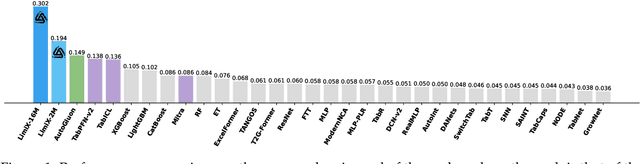
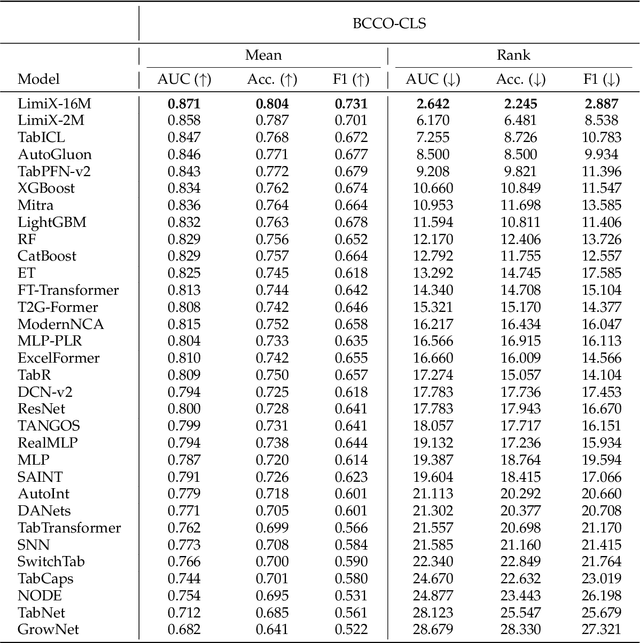
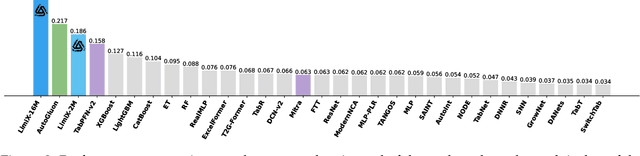
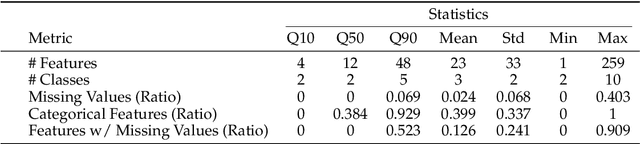
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
Feature-Based Instance Neighbor Discovery: Advanced Stable Test-Time Adaptation in Dynamic World
Jun 07, 2025



Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. We observe that feature distributions across different domains inherently cluster into distinct groups with varying means and variances. This divergence reveals a critical limitation of previous global normalization strategies in TTA, which inevitably distort the original data characteristics. Based on this insight, we propose Feature-based Instance Neighbor Discovery (FIND), which comprises three key components: Layer-wise Feature Disentanglement (LFD), Feature Aware Batch Normalization (FABN) and Selective FABN (S-FABN). LFD stably captures features with similar distributions at each layer by constructing graph structures. While FABN optimally combines source statistics with test-time distribution specific statistics for robust feature representation. Finally, S-FABN determines which layers require feature partitioning and which can remain unified, thereby enhancing inference efficiency. Extensive experiments demonstrate that FIND significantly outperforms existing methods, achieving a 30\% accuracy improvement in dynamic scenarios while maintaining computational efficiency.
Computer-Aided Layout Generation for Building Design: A Review
Apr 13, 2025
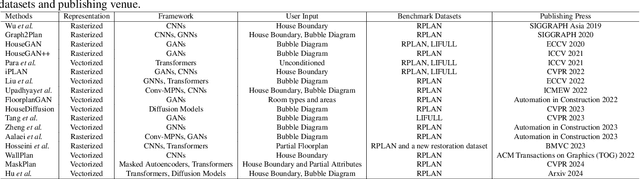
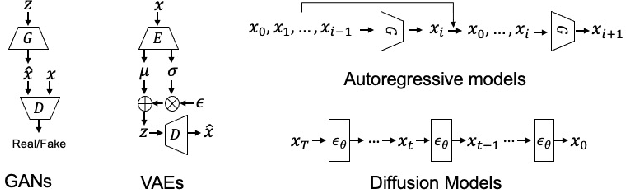

Generating realistic building layouts for automatic building design has been studied in both the computer vision and architecture domains. Traditional approaches from the architecture domain, which are based on optimization techniques or heuristic design guidelines, can synthesize desirable layouts, but usually require post-processing and involve human interaction in the design pipeline, making them costly and timeconsuming. The advent of deep generative models has significantly improved the fidelity and diversity of the generated architecture layouts, reducing the workload by designers and making the process much more efficient. In this paper, we conduct a comprehensive review of three major research topics of architecture layout design and generation: floorplan layout generation, scene layout synthesis, and generation of some other formats of building layouts. For each topic, we present an overview of the leading paradigms, categorized either by research domains (architecture or machine learning) or by user input conditions or constraints. We then introduce the commonly-adopted benchmark datasets that are used to verify the effectiveness of the methods, as well as the corresponding evaluation metrics. Finally, we identify the well-solved problems and limitations of existing approaches, then propose new perspectives as promising directions for future research in this important research area. A project associated with this survey to maintain the resources is available at awesome-building-layout-generation.