 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Based Instance Neighbor Discovery: Advanced Stable Test-Time Adaptation in Dynamic World
Jun 07, 2025Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. We observe that feature distributions across different domains inherently cluster into distinct groups with varying means and variances. This divergence reveals a critical limitation of previous global normalization strategies in TTA, which inevitably distort the original data characteristics. Based on this insight, we propose Feature-based Instance Neighbor Discovery (FIND), which comprises three key components: Layer-wise Feature Disentanglement (LFD), Feature Aware Batch Normalization (FABN) and Selective FABN (S-FABN). LFD stably captures features with similar distributions at each layer by constructing graph structures. While FABN optimally combines source statistics with test-time distribution specific statistics for robust feature representation. Finally, S-FABN determines which layers require feature partitioning and which can remain unified, thereby enhancing inference efficiency. Extensive experiments demonstrate that FIND significantly outperforms existing methods, achieving a 30\% accuracy improvement in dynamic scenarios while maintaining computational efficiency.
KORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
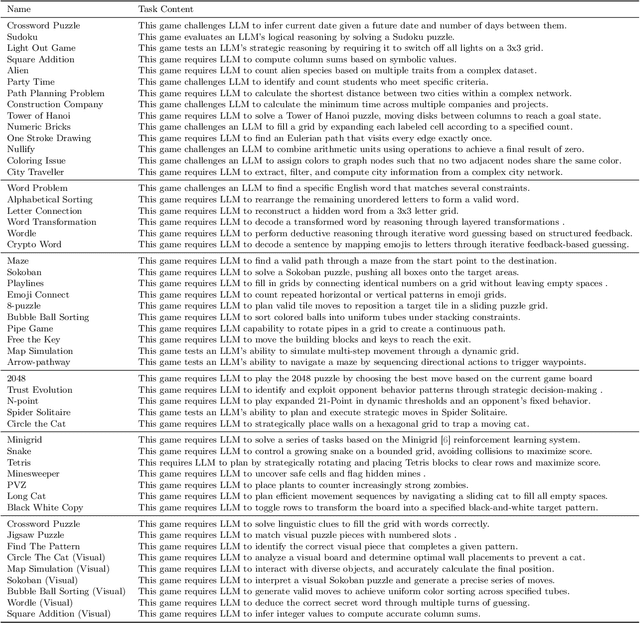
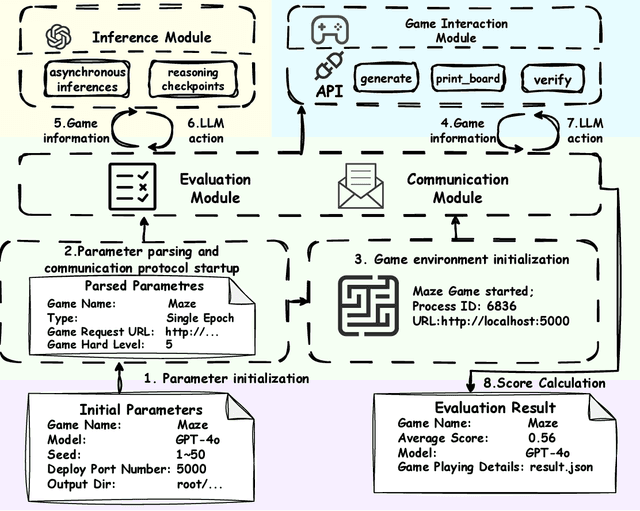

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
DiM: $f$-Divergence Minimization Guided Sharpness-Aware Optimization for Semi-supervised Medical Image Segmentation
Nov 19, 2024
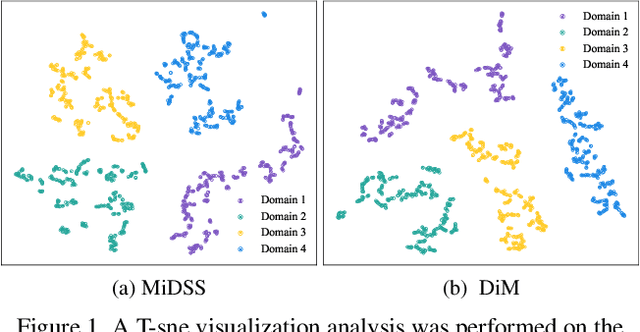


As a technique to alleviate the pressure of data annotation, semi-supervised learning (SSL) has attracted widespread attention. In the specific domain of medical image segmentation, semi-supervised methods (SSMIS) have become a research hotspot due to their ability to reduce the need for large amounts of precisely annotated data. SSMIS focuses on enhancing the model's generalization performance by leveraging a small number of labeled samples and a large number of unlabeled samples. The latest sharpness-aware optimization (SAM) technique, which optimizes the model by reducing the sharpness of the loss function, has shown significant success in SSMIS. However, SAM and its variants may not fully account for the distribution differences between different datasets. To address this issue, we propose a sharpness-aware optimization method based on $f$-divergence minimization (DiM) for semi-supervised medical image segmentation. This method enhances the model's stability by fine-tuning the sensitivity of model parameters and improves the model's adaptability to different datasets through the introduction of $f$-divergence. By reducing $f$-divergence, the DiM method not only improves the performance balance between the source and target datasets but also prevents performance degradation due to overfitting on the source dataset.
Can MLLMs Understand the Deep Implication Behind Chinese Images?
Oct 17, 2024
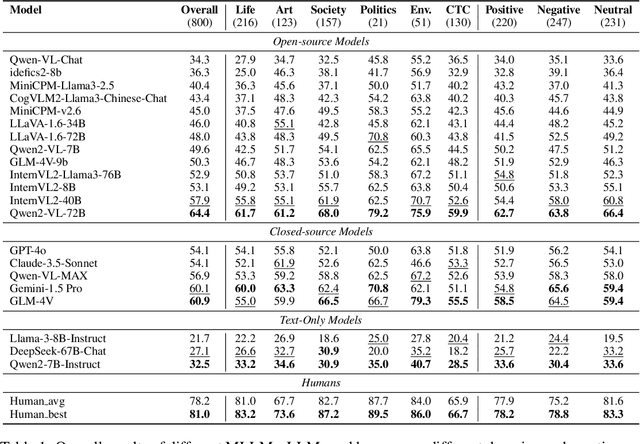
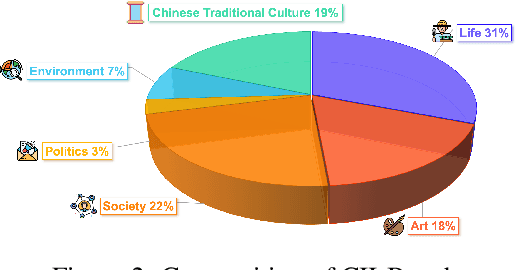
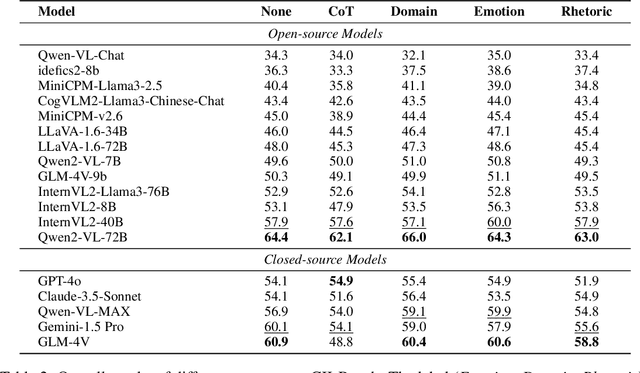
As the capabilities of Multimodal Large Language Models (MLLMs) continue to improve, the need for higher-order capability evaluation of MLLMs is increasing. However, there is a lack of work evaluating MLLM for higher-order perception and understanding of Chinese visual content. To fill the gap, we introduce the **C**hinese **I**mage **I**mplication understanding **Bench**mark, **CII-Bench**, which aims to assess the higher-order perception and understanding capabilities of MLLMs for Chinese images. CII-Bench stands out in several ways compared to existing benchmarks. Firstly, to ensure the authenticity of the Chinese context, images in CII-Bench are sourced from the Chinese Internet and manually reviewed, with corresponding answers also manually crafted. Additionally, CII-Bench incorporates images that represent Chinese traditional culture, such as famous Chinese traditional paintings, which can deeply reflect the model's understanding of Chinese traditional culture. Through extensive experiments on CII-Bench across multiple MLLMs, we have made significant findings. Initially, a substantial gap is observed between the performance of MLLMs and humans on CII-Bench. The highest accuracy of MLLMs attains 64.4%, where as human accuracy averages 78.2%, peaking at an impressive 81.0%. Subsequently, MLLMs perform worse on Chinese traditional culture images, suggesting limitations in their ability to understand high-level semantics and lack a deep knowledge base of Chinese traditional culture. Finally, it is observed that most models exhibit enhanced accuracy when image emotion hints are incorporated into the prompts. We believe that CII-Bench will enable MLLMs to gain a better understanding of Chinese semantics and Chinese-specific images, advancing the journey towards expert artificial general intelligence (AGI). Our project is publicly available at https://cii-bench.github.io/.
Open-World Test-Time Training: Self-Training with Contrast Learning
Sep 15, 2024



Traditional test-time training (TTT) methods, while addressing domain shifts, often assume a consistent class set, limiting their applicability in real-world scenarios characterized by infinite variety. Open-World Test-Time Training (OWTTT) addresses the challenge of generalizing deep learning models to unknown target domain distributions, especially in the presence of strong Out-of-Distribution (OOD) data. Existing TTT methods often struggle to maintain performance when confronted with strong OOD data. In OWTTT, the focus has predominantly been on distinguishing between overall strong and weak OOD data. However, during the early stages of TTT, initial feature extraction is hampered by interference from strong OOD and corruptions, resulting in diminished contrast and premature classification of certain classes as strong OOD. To address this, we introduce Open World Dynamic Contrastive Learning (OWDCL), an innovative approach that utilizes contrastive learning to augment positive sample pairs. This strategy not only bolsters contrast in the early stages but also significantly enhances model robustness in subsequent stages. In comparison datasets, our OWDCL model has produced the most advanced performance.