 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Only Consistency: Enhance Test-Time Adaptation with Spatio-temporal Inconsistency for Remote Physiological Measurement
Jul 10, 2025Remote photoplethysmography (rPPG) has emerged as a promising non-invasive method for monitoring physiological signals using the camera. Although various domain adaptation and generalization methods were proposed to promote the adaptability of deep-based rPPG models in unseen deployment environments, considerations in aspects like privacy concerns and real-time adaptation restrict their application in real-world deployment. Thus, we aim to propose a novel fully Test-Time Adaptation (TTA) strategy tailored for rPPG tasks in this work. Specifically, based on prior knowledge in physiology and our observations, we noticed not only there is spatio-temporal consistency in the frequency domain of rPPG signals, but also that inconsistency in the time domain was significant. Given this, by leveraging both consistency and inconsistency priors, we introduce an innovative expert knowledge-based self-supervised \textbf{C}onsistency-\textbf{i}n\textbf{C}onsistency-\textbf{i}ntegration (\textbf{CiCi}) framework to enhances model adaptation during inference. Besides, our approach further incorporates a gradient dynamic control mechanism to mitigate potential conflicts between priors, ensuring stable adaptation across instances. Through extensive experiments on five diverse datasets under the TTA protocol, our method consistently outperforms existing techniques, presenting state-of-the-art performance in real-time self-supervised adaptation without accessing source data. The code will be released later.
AGLP: A Graph Learning Perspective for Semi-supervised Domain Adaptation
Nov 20, 2024In semi-supervised domain adaptation (SSDA), the model aims to leverage partially labeled target domain data along with a large amount of labeled source domain data to enhance its generalization capability for the target domain. A key advantage of SSDA is its ability to significantly reduce reliance on labeled data, thereby lowering the costs and time associated with data preparation. Most existing SSDA methods utilize information from domain labels and class labels but overlook the structural information of the data. To address this issue, this paper proposes a graph learning perspective (AGLP) for semi-supervised domain adaptation. We apply the graph convolutional network to the instance graph which allows structural information to propagate along the weighted graph edges. The proposed AGLP model has several advantages. First, to the best of our knowledge, this is the first work to model structural information in SSDA. Second, the proposed model can effectively learn domain-invariant and semantic representations, reducing domain discrepancies in SSDA. Extensive experimental results on multiple standard benchmarks demonstrate that the proposed AGLP algorithm outperforms state-of-the-art semi-supervised domain adaptation methods.
GraphCL: Graph-based Clustering for Semi-Supervised Medical Image Segmentation
Nov 20, 2024



Semi-supervised learning (SSL) has made notable advancements in medical image segmentation (MIS), particularly in scenarios with limited labeled data and significantly enhancing data utilization efficiency. Previous methods primarily focus on complex training strategies to utilize unlabeled data but neglect the importance of graph structural information. Different from existing methods, we propose a graph-based clustering for semi-supervised medical image segmentation (GraphCL) by jointly modeling graph data structure in a unified deep model. The proposed GraphCL model enjoys several advantages. Firstly, to the best of our knowledge, this is the first work to model the data structure information for semi-supervised medical image segmentation (SSMIS). Secondly, to get the clustered features across different graphs, we integrate both pairwise affinities between local image features and raw features as inputs. Extensive experimental results on three standard benchmarks show that the proposed GraphCL algorithm outperforms state-of-the-art semi-supervised medical image segmentation methods.
DiM: $f$-Divergence Minimization Guided Sharpness-Aware Optimization for Semi-supervised Medical Image Segmentation
Nov 19, 2024
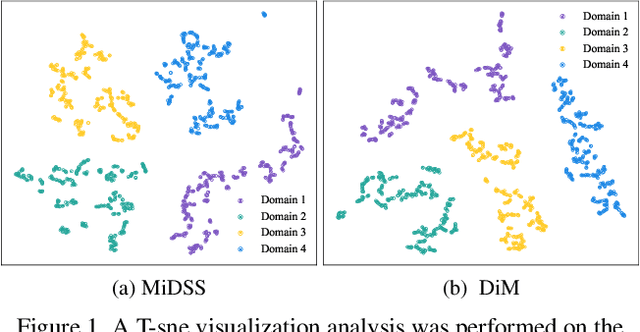


As a technique to alleviate the pressure of data annotation, semi-supervised learning (SSL) has attracted widespread attention. In the specific domain of medical image segmentation, semi-supervised methods (SSMIS) have become a research hotspot due to their ability to reduce the need for large amounts of precisely annotated data. SSMIS focuses on enhancing the model's generalization performance by leveraging a small number of labeled samples and a large number of unlabeled samples. The latest sharpness-aware optimization (SAM) technique, which optimizes the model by reducing the sharpness of the loss function, has shown significant success in SSMIS. However, SAM and its variants may not fully account for the distribution differences between different datasets. To address this issue, we propose a sharpness-aware optimization method based on $f$-divergence minimization (DiM) for semi-supervised medical image segmentation. This method enhances the model's stability by fine-tuning the sensitivity of model parameters and improves the model's adaptability to different datasets through the introduction of $f$-divergence. By reducing $f$-divergence, the DiM method not only improves the performance balance between the source and target datasets but also prevents performance degradation due to overfitting on the source dataset.
Open-World Test-Time Training: Self-Training with Contrast Learning
Sep 15, 2024



Traditional test-time training (TTT) methods, while addressing domain shifts, often assume a consistent class set, limiting their applicability in real-world scenarios characterized by infinite variety. Open-World Test-Time Training (OWTTT) addresses the challenge of generalizing deep learning models to unknown target domain distributions, especially in the presence of strong Out-of-Distribution (OOD) data. Existing TTT methods often struggle to maintain performance when confronted with strong OOD data. In OWTTT, the focus has predominantly been on distinguishing between overall strong and weak OOD data. However, during the early stages of TTT, initial feature extraction is hampered by interference from strong OOD and corruptions, resulting in diminished contrast and premature classification of certain classes as strong OOD. To address this, we introduce Open World Dynamic Contrastive Learning (OWDCL), an innovative approach that utilizes contrastive learning to augment positive sample pairs. This strategy not only bolsters contrast in the early stages but also significantly enhances model robustness in subsequent stages. In comparison datasets, our OWDCL model has produced the most advanced performance.
Boosting Few-Shot Semantic Segmentation Via Segment Anything Model
Jan 20, 2024In semantic segmentation, accurate prediction masks are crucial for downstream tasks such as medical image analysis and image editing. Due to the lack of annotated data, few-shot semantic segmentation (FSS) performs poorly in predicting masks with precise contours. Recently, we have noticed that the large foundation model segment anything model (SAM) performs well in processing detailed features. Inspired by SAM, we propose FSS-SAM to boost FSS methods by addressing the issue of inaccurate contour. The FSS-SAM is training-free. It works as a post-processing tool for any FSS methods and can improve the accuracy of predicted masks. Specifically, we use predicted masks from FSS methods to generate prompts and then use SAM to predict new masks. To avoid predicting wrong masks with SAM, we propose a prediction result selection (PRS) algorithm. The algorithm can remarkably decrease wrong predictions. Experiment results on public datasets show that our method is superior to base FSS methods in both quantitative and qualitative aspects.
Singular Value Penalization and Semantic Data Augmentation for Fully Test-Time Adaptation
Dec 10, 2023



Fully test-time adaptation (FTTA) adapts a model that is trained on a source domain to a target domain during the testing phase, where the two domains follow different distributions and source data is unavailable during the training phase. Existing methods usually adopt entropy minimization to reduce the uncertainty of target prediction results, and improve the FTTA performance accordingly. However, they fail to ensure the diversity in target prediction results. Recent domain adaptation study has shown that maximizing the sum of singular values of prediction results can simultaneously enhance their confidence (discriminability) and diversity. However, during the training phase, larger singular values usually take up a dominant position in loss maximization. This results in the model being more inclined to enhance discriminability for easily distinguishable classes, and the improvement in diversity is insufficiently effective. Furthermore, the adaptation and prediction in FTTA only use data from the current batch, which may lead to the risk of overfitting. To address the aforementioned issues, we propose maximizing the sum of singular values while minimizing their variance. This enables the model's focus toward the smaller singular values, enhancing discriminability between more challenging classes and effectively increasing the diversity of prediction results. Moreover, we incorporate data from the previous batch to realize semantic data augmentation for the current batch, reducing the risk of overfitting. Extensive experiments on benchmark datasets show our proposed approach outperforms some compared state-of-the-art FTTA methods.
Graph based Label Enhancement for Multi-instance Multi-label learning
Apr 21, 2023



Multi-instance multi-label (MIML) learning is widely applicated in numerous domains, such as the image classification where one image contains multiple instances correlated with multiple logic labels simultaneously. The related labels in existing MIML are all assumed as logical labels with equal significance. However, in practical applications in MIML, significance of each label for multiple instances per bag (such as an image) is significant different. Ignoring labeling significance will greatly lose the semantic information of the object, so that MIML is not applicable in complex scenes with a poor learning performance. To this end, this paper proposed a novel MIML framework based on graph label enhancement, namely GLEMIML, to improve the classification performance of MIML by leveraging label significance. GLEMIML first recognizes the correlations among instances by establishing the graph and then migrates the implicit information mined from the feature space to the label space via nonlinear mapping, thus recovering the label significance. Finally, GLEMIML is trained on the enhanced data through matching and interaction mechanisms. GLEMIML (AvgRank: 1.44) can effectively improve the performance of MIML by mining the label distribution mechanism and show better results than the SOTA method (AvgRank: 2.92) on multiple benchmark datasets.