 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHear the Heartbeat in Phases: Physiologically Grounded Phase-Aware ECG Biometrics
Jan 01, 2026Electrocardiography (ECG) is adopted for identity authentication in wearable devices due to its individual-specific characteristics and inherent liveness. However, existing methods often treat heartbeats as homogeneous signals, overlooking the phase-specific characteristics within the cardiac cycle. To address this, we propose a Hierarchical Phase-Aware Fusion~(HPAF) framework that explicitly avoids cross-feature entanglement through a three-stage design. In the first stage, Intra-Phase Representation (IPR) independently extracts representations for each cardiac phase, ensuring that phase-specific morphological and variation cues are preserved without interference from other phases. In the second stage, Phase-Grouped Hierarchical Fusion (PGHF) aggregates physiologically related phases in a structured manner, enabling reliable integration of complementary phase information. In the final stage, Global Representation Fusion (GRF) further combines the grouped representations and adaptively balances their contributions to produce a unified and discriminative identity representation. Moreover, considering ECG signals are continuously acquired, multiple heartbeats can be collected for each individual. We propose a Heartbeat-Aware Multi-prototype (HAM) enrollment strategy, which constructs a multi-prototype gallery template set to reduce the impact of heartbeat-specific noise and variability. Extensive experiments on three public datasets demonstrate that HPAF achieves state-of-the-art results in the comparison with other methods under both closed and open-set settings.
Exploiting the Potential Supervision Information of Clean Samples in Partial Label Learning
May 14, 2025Diminishing the impact of false-positive labels is critical for conducting disambiguation in partial label learning. However, the existing disambiguation strategies mainly focus on exploiting the characteristics of individual partial label instances while neglecting the strong supervision information of clean samples randomly lying in the datasets. In this work, we show that clean samples can be collected to offer guidance and enhance the confidence of the most possible candidates. Motivated by the manner of the differentiable count loss strat- egy and the K-Nearest-Neighbor algorithm, we proposed a new calibration strategy called CleanSE. Specifically, we attribute the most reliable candidates with higher significance under the assumption that for each clean sample, if its label is one of the candidates of its nearest neighbor in the representation space, it is more likely to be the ground truth of its neighbor. Moreover, clean samples offer help in characterizing the sample distributions by restricting the label counts of each label to a specific interval. Extensive experiments on 3 synthetic benchmarks and 5 real-world PLL datasets showed this calibration strategy can be applied to most of the state-of-the-art PLL methods as well as enhance their performance.
GBRIP: Granular Ball Representation for Imbalanced Partial Label Learning
Dec 19, 2024Partial label learning (PLL) is a complicated weakly supervised multi-classification task compounded by class imbalance. Currently, existing methods only rely on inter-class pseudo-labeling from inter-class features, often overlooking the significant impact of the intra-class imbalanced features combined with the inter-class. To address these limitations, we introduce Granular Ball Representation for Imbalanced PLL (GBRIP), a novel framework for imbalanced PLL. GBRIP utilizes coarse-grained granular ball representation and multi-center loss to construct a granular ball-based nfeature space through unsupervised learning, effectively capturing the feature distribution within each class. GBRIP mitigates the impact of confusing features by systematically refining label disambiguation and estimating imbalance distributions. The novel multi-center loss function enhances learning by emphasizing the relationships between samples and their respective centers within the granular balls. Extensive experiments on standard benchmarks demonstrate that GBRIP outperforms existing state-of-the-art methods, offering a robust solution to the challenges of imbalanced PLL.
Minimum Tuning to Unlock Long Output from LLMs with High Quality Data as the Key
Oct 15, 2024As large language models rapidly evolve to support longer context, there is a notable disparity in their capability to generate output at greater lengths. Recent study suggests that the primary cause for this imbalance may arise from the lack of data with long-output during alignment training. In light of this observation, attempts are made to re-align foundation models with data that fills the gap, which result in models capable of generating lengthy output when instructed. In this paper, we explore the impact of data-quality in tuning a model for long output, and the possibility of doing so from the starting points of human-aligned (instruct or chat) models. With careful data curation, we show that it possible to achieve similar performance improvement in our tuned models, with only a small fraction of training data instances and compute. In addition, we assess the generalizability of such approaches by applying our tuning-recipes to several models. our findings suggest that, while capacities for generating long output vary across different models out-of-the-box, our approach to tune them with high-quality data using lite compute, consistently yields notable improvement across all models we experimented on. We have made public our curated dataset for tuning long-writing capability, the implementations of model tuning and evaluation, as well as the fine-tuned models, all of which can be openly-accessed.
SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning
Aug 13, 2024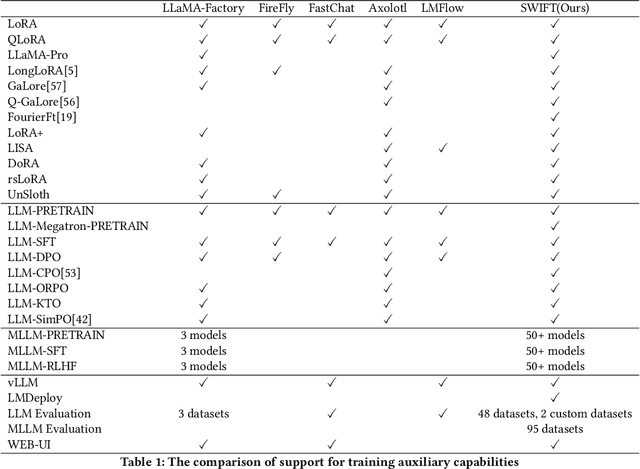
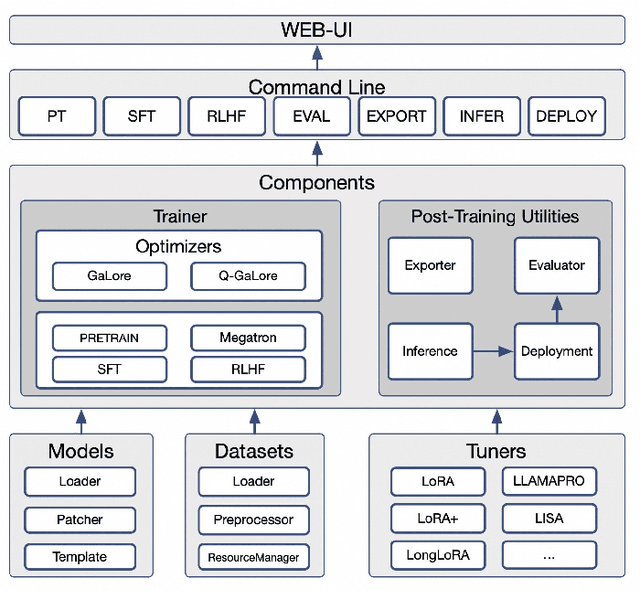


Recent development in Large Language Models (LLMs) and Multi-modal Large Language Models (MLLMs) have leverage Attention-based Transformer architectures and achieved superior performance and generalization capabilities. They have since covered extensive areas of traditional learning tasks. For instance, text-based tasks such as text-classification and sequence-labeling, as well as multi-modal tasks like Visual Question Answering (VQA) and Optical Character Recognition (OCR), which were previously addressed using different models, can now be tackled based on one foundation model. Consequently, the training and lightweight fine-tuning of LLMs and MLLMs, especially those based on Transformer architecture, has become particularly important. In recognition of these overwhelming needs, we develop SWIFT, a customizable one-stop infrastructure for large models. With support of over $300+$ LLMs and $50+$ MLLMs, SWIFT stands as the open-source framework that provide the \textit{most comprehensive support} for fine-tuning large models. In particular, it is the first training framework that provides systematic support for MLLMs. In addition to the core functionalities of fine-tuning, SWIFT also integrates post-training processes such as inference, evaluation, and model quantization, to facilitate fast adoptions of large models in various application scenarios. With a systematic integration of various training techniques, SWIFT offers helpful utilities such as benchmark comparisons among different training techniques for large models. For fine-tuning models specialized in agent framework, we show that notable improvements on the ToolBench leader-board can be achieved by training with customized dataset on SWIFT, with an increase of 5.2%-21.8% in the Act.EM metric over various baseline models, a reduction in hallucination by 1.6%-14.1%, and an average performance improvement of 8%-17%.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024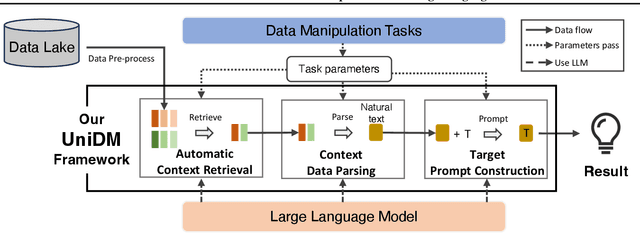
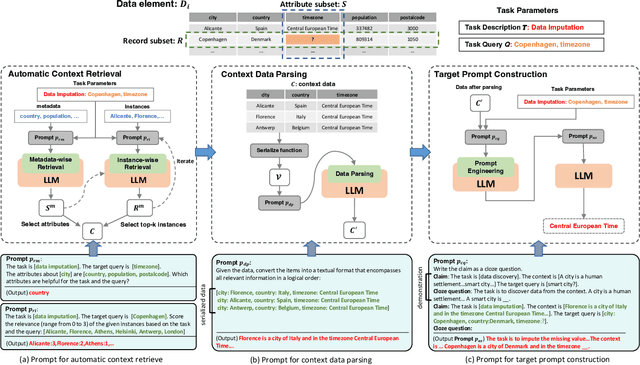
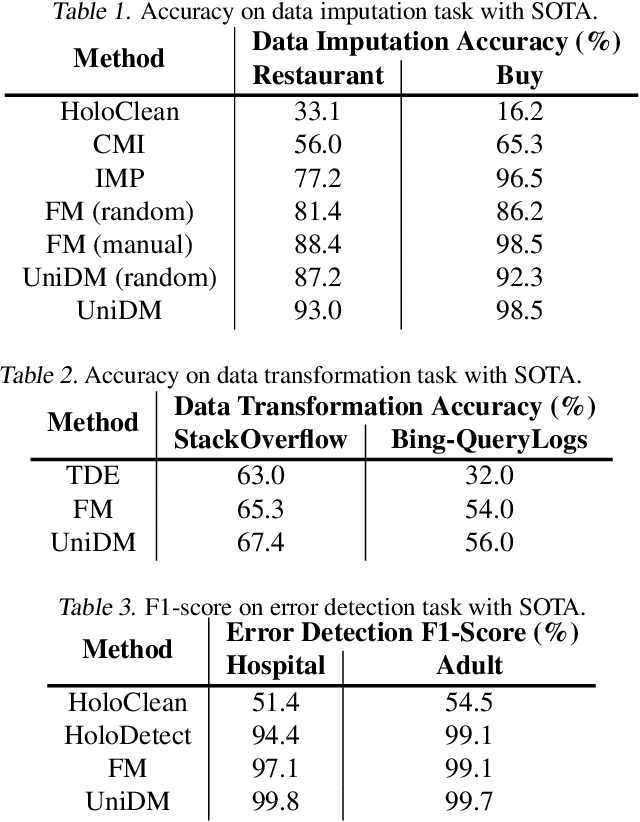
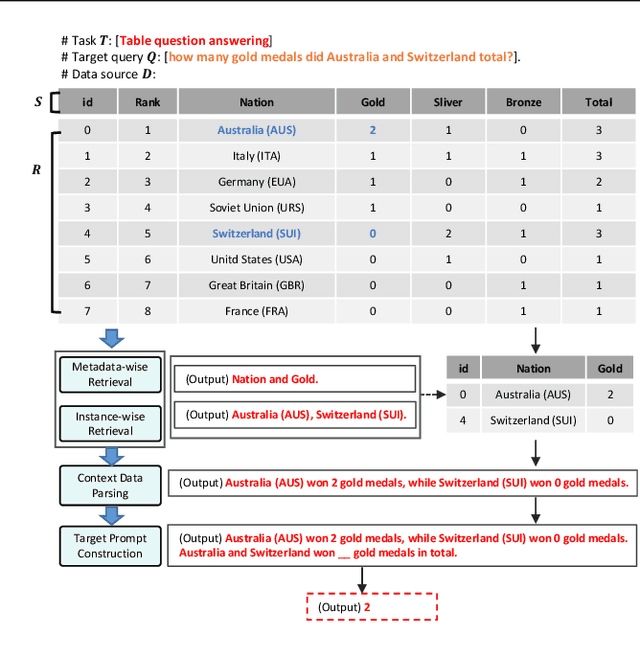
Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
Trustworthy Partial Label Learning with Out-of-distribution Detection
Mar 11, 2024Partial Label Learning (PLL) grapples with learning from ambiguously labelled data, and it has been successfully applied in fields such as image recognition. Nevertheless, traditional PLL methods rely on the closed-world assumption, which can be limiting in open-world scenarios and negatively impact model performance and generalization. To tackle these challenges, our study introduces a novel method called PLL-OOD, which is the first to incorporate Out-of-Distribution (OOD) detection into the PLL framework. PLL-OOD significantly enhances model adaptability and accuracy by merging self-supervised learning with partial label loss and pioneering the Partial-Energy (PE) score for OOD detection. This approach improves data feature representation and effectively disambiguates candidate labels, using a dynamic label confidence matrix to refine predictions. The PE score, adjusted by label confidence, precisely identifies OOD instances, optimizing model training towards in-distribution data. This innovative method markedly boosts PLL model robustness and performance in open-world settings. To validate our approach, we conducted a comprehensive comparative experiment combining the existing state-of-the-art PLL model with multiple OOD scores on the CIFAR-10 and CIFAR-100 datasets with various OOD datasets. The results demonstrate that the proposed PLL-OOD framework is highly effective and effectiveness outperforms existing models, showcasing its superiority and effectiveness.
FedPIT: Towards Privacy-preserving and Few-shot Federated Instruction Tuning
Mar 10, 2024



Instruction tuning has proven essential for enhancing the performance of large language models (LLMs) in generating human-aligned responses. However, collecting diverse, high-quality instruction data for tuning poses challenges, particularly in privacy-sensitive domains. Federated instruction tuning (FedIT) has emerged as a solution, leveraging federated learning from multiple data owners while preserving privacy. Yet, it faces challenges due to limited instruction data and vulnerabilities to training data extraction attacks. To address these issues, we propose a novel federated algorithm, FedPIT, which utilizes LLMs' in-context learning capability to self-generate task-specific synthetic data for training autonomously. Our method employs parameter-isolated training to maintain global parameters trained on synthetic data and local parameters trained on augmented local data, effectively thwarting data extraction attacks. Extensive experiments on real-world medical data demonstrate the effectiveness of FedPIT in improving federated few-shot performance while preserving privacy and robustness against data heterogeneity.
FedNoisy: Federated Noisy Label Learning Benchmark
Jun 20, 2023Federated learning has gained popularity for distributed learning without aggregating sensitive data from clients. But meanwhile, the distributed and isolated nature of data isolation may be complicated by data quality, making it more vulnerable to noisy labels. Many efforts exist to defend against the negative impacts of noisy labels in centralized or federated settings. However, there is a lack of a benchmark that comprehensively considers the impact of noisy labels in a wide variety of typical FL settings. In this work, we serve the first standardized benchmark that can help researchers fully explore potential federated noisy settings. Also, we conduct comprehensive experiments to explore the characteristics of these data settings and unravel challenging scenarios on the federated noisy label learning, which may guide method development in the future. We highlight the 20 basic settings for more than 5 datasets proposed in our benchmark and standardized simulation pipeline for federated noisy label learning. We hope this benchmark can facilitate idea verification in federated learning with noisy labels. \texttt{FedNoisy} is available at \codeword{https://github.com/SMILELab-FL/FedNoisy}.
Graph based Label Enhancement for Multi-instance Multi-label learning
Apr 21, 2023



Multi-instance multi-label (MIML) learning is widely applicated in numerous domains, such as the image classification where one image contains multiple instances correlated with multiple logic labels simultaneously. The related labels in existing MIML are all assumed as logical labels with equal significance. However, in practical applications in MIML, significance of each label for multiple instances per bag (such as an image) is significant different. Ignoring labeling significance will greatly lose the semantic information of the object, so that MIML is not applicable in complex scenes with a poor learning performance. To this end, this paper proposed a novel MIML framework based on graph label enhancement, namely GLEMIML, to improve the classification performance of MIML by leveraging label significance. GLEMIML first recognizes the correlations among instances by establishing the graph and then migrates the implicit information mined from the feature space to the label space via nonlinear mapping, thus recovering the label significance. Finally, GLEMIML is trained on the enhanced data through matching and interaction mechanisms. GLEMIML (AvgRank: 1.44) can effectively improve the performance of MIML by mining the label distribution mechanism and show better results than the SOTA method (AvgRank: 2.92) on multiple benchmark datasets.