 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcMEM: Learning Reusable Procedural Memory from Experience via Non-Parametric PPO for LLM Agents
Feb 02, 2026LLM-driven agents demonstrate strong performance in sequential decision-making but often rely on on-the-fly reasoning, re-deriving solutions even in recurring scenarios. This insufficient experience reuse leads to computational redundancy and execution instability. To bridge this gap, we propose ProcMEM, a framework that enables agents to autonomously learn procedural memory from interaction experiences without parameter updates. By formalizing a Skill-MDP, ProcMEM transforms passive episodic narratives into executable Skills defined by activation, execution, and termination conditions to ensure executability. To achieve reliable reusability without capability degradation, we introduce Non-Parametric PPO, which leverages semantic gradients for high-quality candidate generation and a PPO Gate for robust Skill verification. Through score-based maintenance, ProcMEM sustains compact, high-quality procedural memory. Experimental results across in-domain, cross-task, and cross-agent scenarios demonstrate that ProcMEM achieves superior reuse rates and significant performance gains with extreme memory compression. Visualized evolutionary trajectories and Skill distributions further reveal how ProcMEM transparently accumulates, refines, and reuses procedural knowledge to facilitate long-term autonomy.
KIMAs: A Configurable Knowledge Integrated Multi-Agent System
Feb 13, 2025Knowledge-intensive conversations supported by large language models (LLMs) have become one of the most popular and helpful applications that can assist people in different aspects. Many current knowledge-intensive applications are centered on retrieval-augmented generation (RAG) techniques. While many open-source RAG frameworks facilitate the development of RAG-based applications, they often fall short in handling practical scenarios complicated by heterogeneous data in topics and formats, conversational context management, and the requirement of low-latency response times. This technical report presents a configurable knowledge integrated multi-agent system, KIMAs, to address these challenges. KIMAs features a flexible and configurable system for integrating diverse knowledge sources with 1) context management and query rewrite mechanisms to improve retrieval accuracy and multi-turn conversational coherency, 2) efficient knowledge routing and retrieval, 3) simple but effective filter and reference generation mechanisms, and 4) optimized parallelizable multi-agent pipeline execution. Our work provides a scalable framework for advancing the deployment of LLMs in real-world settings. To show how KIMAs can help developers build knowledge-intensive applications with different scales and emphases, we demonstrate how we configure the system to three applications already running in practice with reliable performance.
Data Mixing Made Efficient: A Bivariate Scaling Law for Language Model Pretraining
May 23, 2024Large language models exhibit exceptional generalization capabilities, primarily attributed to the utilization of diversely sourced data. However, conventional practices in integrating this diverse data heavily rely on heuristic schemes, lacking theoretical guidance. This research tackles these limitations by investigating strategies based on low-cost proxies for data mixtures, with the aim of streamlining data curation to enhance training efficiency. Specifically, we propose a unified scaling law, termed BiMix, which accurately models the bivariate scaling behaviors of both data quantity and mixing proportions. We conduct systematic experiments and provide empirical evidence for the predictive power and fundamental principles of BiMix. Notably, our findings reveal that entropy-driven training-free data mixtures can achieve comparable or even better performance than more resource-intensive methods. We hope that our quantitative insights can shed light on further judicious research and development in cost-effective language modeling.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024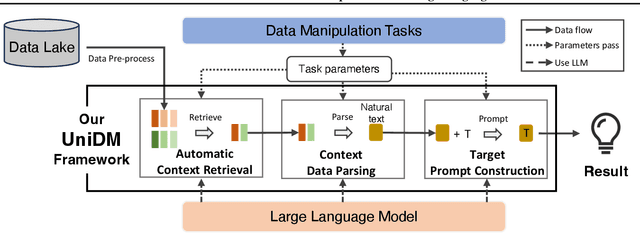
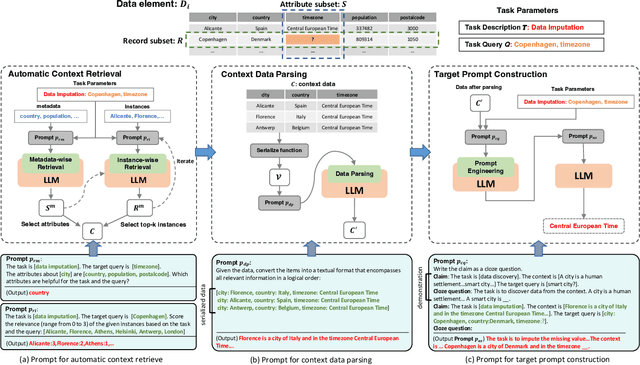
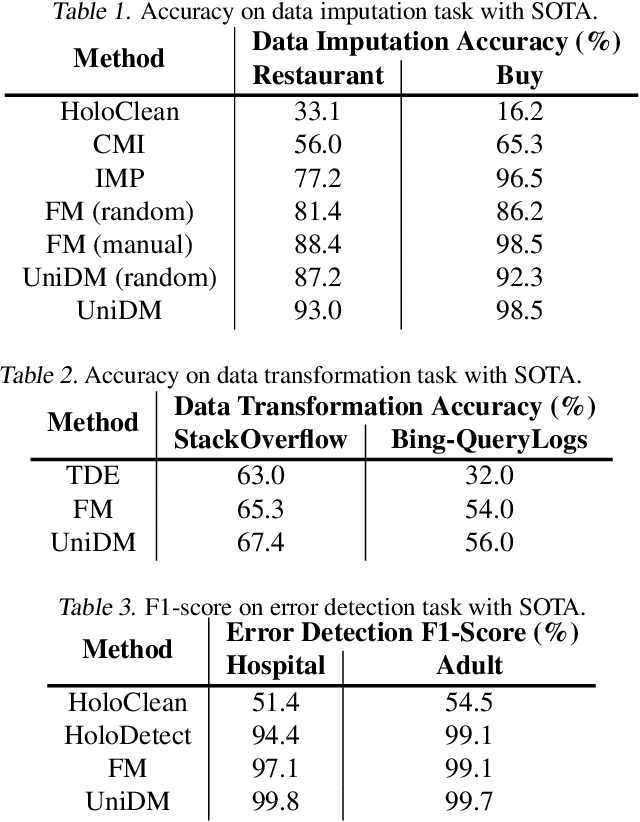
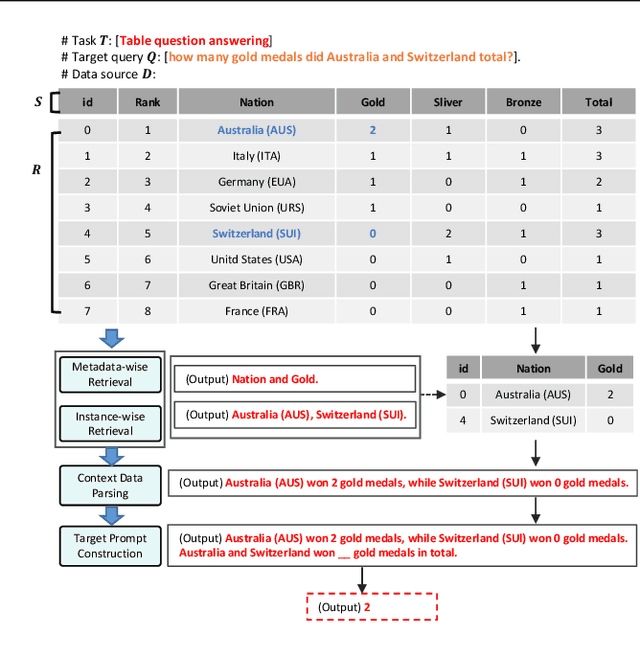
Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
AgentScope: A Flexible yet Robust Multi-Agent Platform
Feb 21, 2024With the rapid advancement of Large Language Models (LLMs), significant progress has been made in multi-agent applications. However, the complexities in coordinating agents' cooperation and LLMs' erratic performance pose notable challenges in developing robust and efficient multi-agent applications. To tackle these challenges, we propose AgentScope, a developer-centric multi-agent platform with message exchange as its core communication mechanism. Together with abundant syntactic tools, built-in resources, and user-friendly interactions, our communication mechanism significantly reduces the barriers to both development and understanding. Towards robust and flexible multi-agent application, AgentScope provides both built-in and customizable fault tolerance mechanisms while it is also armed with system-level supports for multi-modal data generation, storage and transmission. Additionally, we design an actor-based distribution framework, enabling easy conversion between local and distributed deployments and automatic parallel optimization without extra effort. With these features, AgentScope empowers developers to build applications that fully realize the potential of intelligent agents. We have released AgentScope at https://github.com/modelscope/agentscope, and hope AgentScope invites wider participation and innovation in this fast-moving field.
Data-Juicer: A One-Stop Data Processing System for Large Language Models
Sep 05, 2023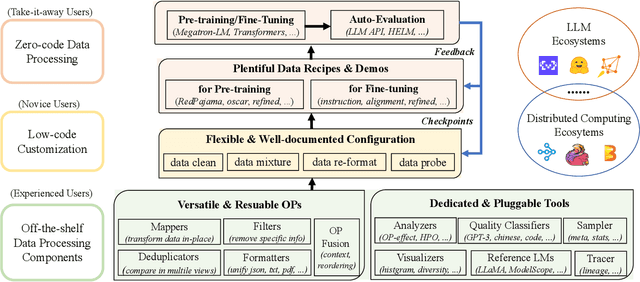
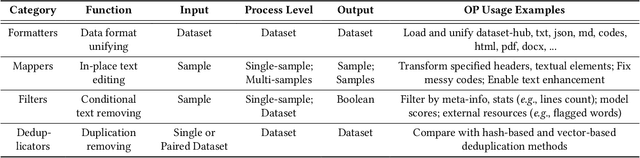
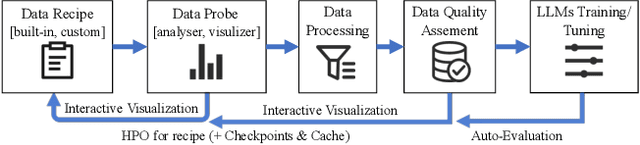
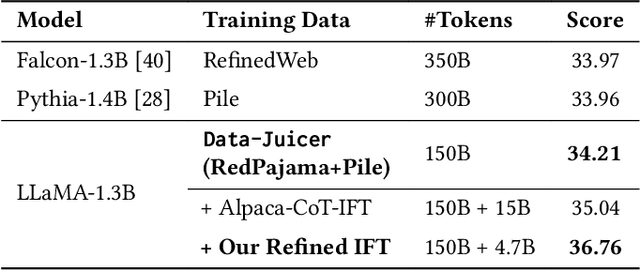
The immense evolution in Large Language Models (LLMs) has underscored the importance of massive, diverse, and high-quality data. Despite this, existing open-source tools for LLM data processing remain limited and mostly tailored to specific datasets, with an emphasis on the reproducibility of released data over adaptability and usability, inhibiting potential applications. In response, we propose a one-stop, powerful yet flexible and user-friendly LLM data processing system named Data-Juicer. Our system offers over 50 built-in versatile operators and pluggable tools, which synergize modularity, composability, and extensibility dedicated to diverse LLM data processing needs. By incorporating visualized and automatic evaluation capabilities, Data-Juicer enables a timely feedback loop to accelerate data processing and gain data insights. To enhance usability, Data-Juicer provides out-of-the-box components for users with various backgrounds, and fruitful data recipes for LLM pre-training and post-tuning usages. Further, we employ multi-facet system optimization and seamlessly integrate Data-Juicer with both LLM and distributed computing ecosystems, to enable efficient and scalable data processing. Empirical validation of the generated data recipes reveals considerable improvements in LLaMA performance for various pre-training and post-tuning cases, demonstrating up to 7.45% relative improvement of averaged score across 16 LLM benchmarks and 16.25% higher win rate using pair-wise GPT-4 evaluation. The system's efficiency and scalability are also validated, supported by up to 88.7% reduction in single-machine processing time, 77.1% and 73.1% less memory and CPU usage respectively, and 7.91x processing acceleration when utilizing distributed computing ecosystems. Our system, data recipes, and multiple tutorial demos are released, calling for broader research centered on LLM data.