 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA plug-and-play generative framework for multi-satellite precipitation estimation
May 14, 2026Reliable precipitation monitoring is essential for disaster risk reduction, water resources management, and agricultural decision-making. Multi-source satellite observations, particularly the combination of geostationary infrared and passive microwave measurements, have become a primary means of precipitation detection. Traditional multi-source satellite precipitation estimation methods remain computationally inefficient, and many deep learning methods lack the flexibility to incorporate new sensors without retraining the full model. Here we introduce PRISMA (Precipitation Inference from Satellite Modalities via generAtive modeling), a plug-and-play latent generative framework for multi-sensor precipitation estimation. PRISMA learns an unconditional precipitation prior from IMERG Final fields and constrains it through independently trained, sensor-specific conditional branches, allowing new observation sources to be incorporated without retraining the generative backbone. Applied to FY-4B AGRI infrared and GPM GMI microwave observations, PRISMA improves Critical Success Index by up to 40.3% and reduces root-mean-square error by 22.6% relative to infrared-only estimation within microwave swaths, while also improving probabilistic skill and maintaining an average inference time of about 37 s. Independent rain-gauge validation across China confirms consistent gains, and typhoon case studies show that microwave conditioning restores eyewall and spiral rainband structures, reducing storm-core mean absolute error by up to 42.3%. PRISMA thus provides an extensible and efficient framework for multi-sensor precipitation estimation.
FuXiWeather2: Learning accurate atmospheric state estimation for operational global weather forecasting
Mar 16, 2026Numerical weather prediction has long been constrained by the computational bottlenecks inherent in data assimilation and numerical modeling. While machine learning has accelerated forecasting, existing models largely serve as "emulators of reanalysis products," thereby retaining their systematic biases and operational latencies. Here, we present FuXiWeather2, a unified end-to-end neural framework for assimilation and forecasting. We align training objectives directly with a combination of real-world observations and reanalysis data, enabling the framework to effectively rectify inherent errors within reanalysis products. To address the distribution shift between NWP-derived background inputs during training and self-generated backgrounds during deployment, we introduce a recursive unrolling training method to enhance the precision and stability of analysis generation. Furthermore, our model is trained on a hybrid dataset of raw and simulated observations to mitigate the impact of observational distribution inconsistency. FuXiWeather2 generates high-resolution ($0.25^{\circ}$) global analysis fields and 10-day forecasts within minutes. The analysis fields surpass the NCEP-GFS across most variables and demonstrate superior accuracy over both ERA5 and the ECMWF-HRES system in lower-tropospheric and surface variables. These high-quality analysis fields drive deterministic forecasts that exceed the skill of the HRES system in 91\% of evaluated metrics. Additionally, its outstanding performance in typhoon track prediction underscores its practical value for rapid response to extreme weather events. The FuXiWeather2 analysis dataset is available at https://doi.org/10.5281/zenodo.18872728.
FuXi Weather: An end-to-end machine learning weather data assimilation and forecasting system
Aug 10, 2024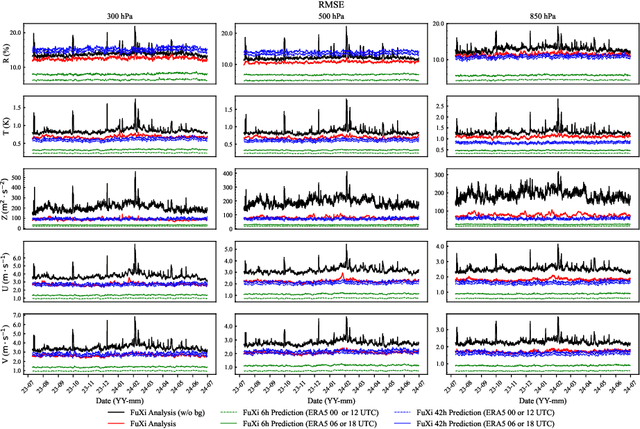
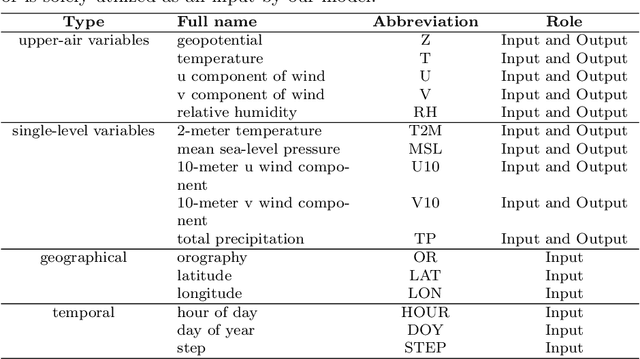
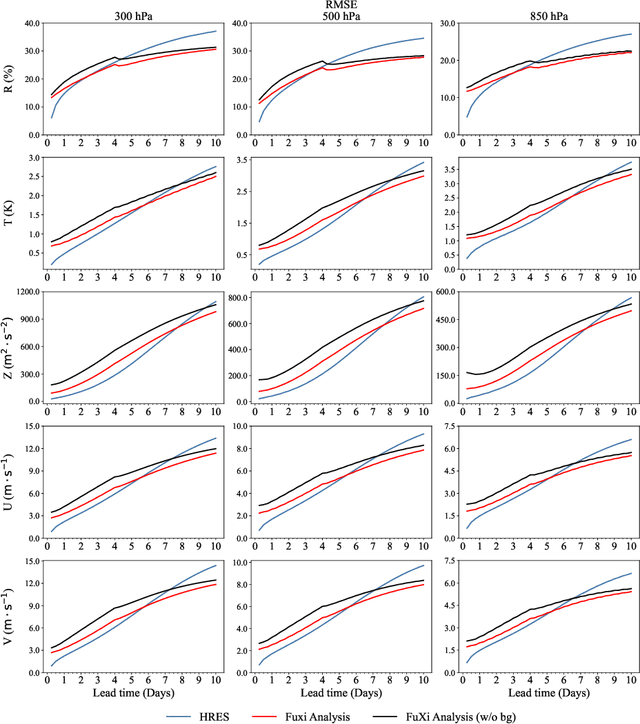
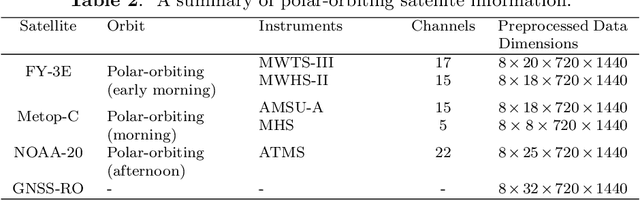
Operational numerical weather prediction systems consist of three fundamental components: the global observing system for data collection, data assimilation for generating initial conditions, and the forecasting model to predict future weather conditions. While NWP have undergone a quiet revolution, with forecast skills progressively improving over the past few decades, their advancement has slowed due to challenges such as high computational costs and the complexities associated with assimilating an increasing volume of observational data and managing finer spatial grids. Advances in machine learning offer an alternative path towards more efficient and accurate weather forecasts. The rise of machine learning based weather forecasting models has also spurred the development of machine learning based DA models or even purely machine learning based weather forecasting systems. This paper introduces FuXi Weather, an end-to-end machine learning based weather forecasting system. FuXi Weather employs specialized data preprocessing and multi-modal data fusion techniques to integrate information from diverse sources under all-sky conditions, including microwave sounders from 3 polar-orbiting satellites and radio occultation data from Global Navigation Satellite System. Operating on a 6-hourly DA and forecasting cycle, FuXi Weather independently generates robust and accurate 10-day global weather forecasts at a spatial resolution of 0.25\textdegree. It surpasses the European Centre for Medium-range Weather Forecasts high-resolution forecasts in terms of predictability, extending the skillful forecast lead times for several key weather variables such as the geopotential height at 500 hPa from 9.25 days to 9.5 days. The system's high computational efficiency and robust performance, even with limited observations, demonstrates its potential as a promising alternative to traditional NWP systems.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024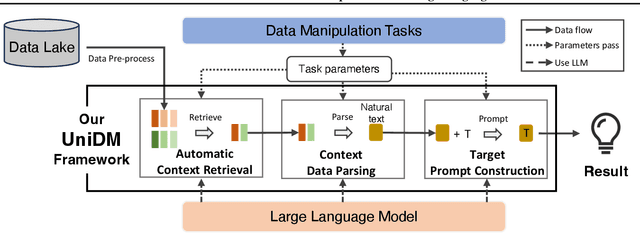
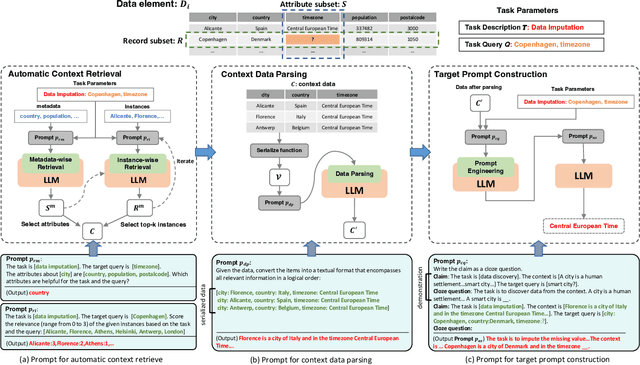
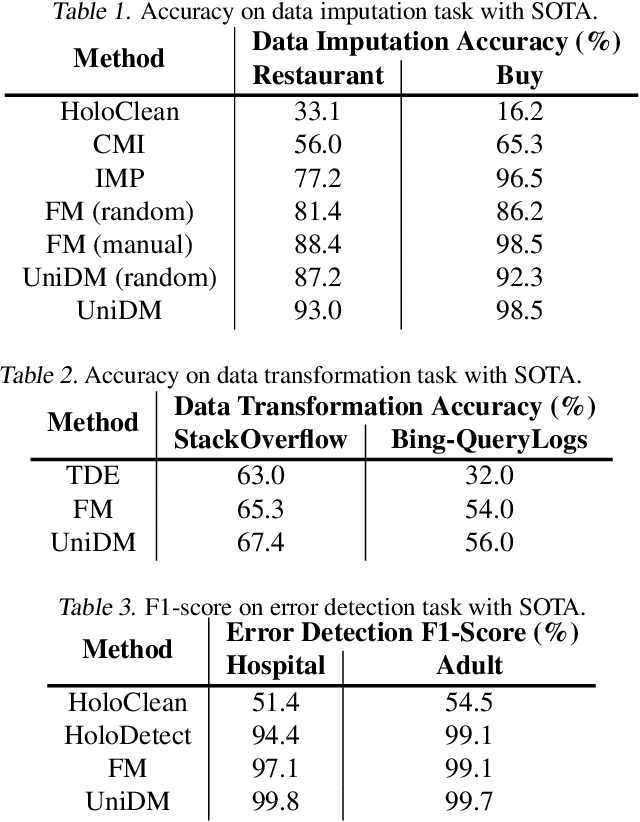
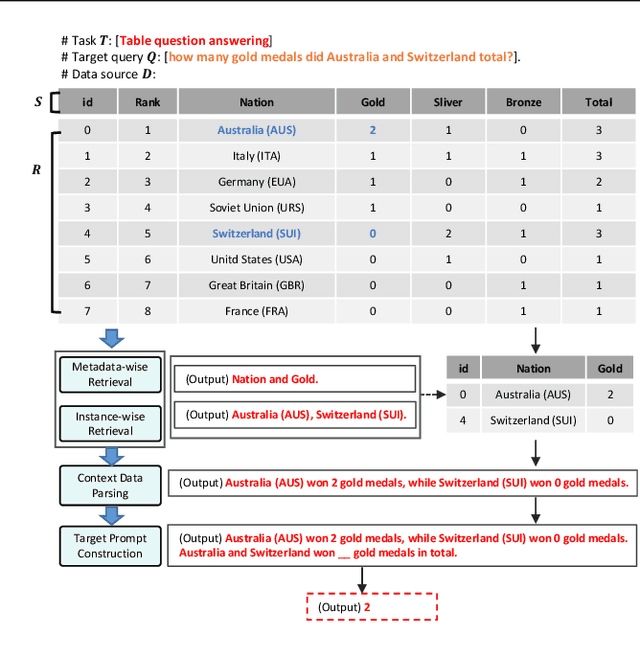
Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
Fuxi-DA: A Generalized Deep Learning Data Assimilation Framework for Assimilating Satellite Observations
Apr 12, 2024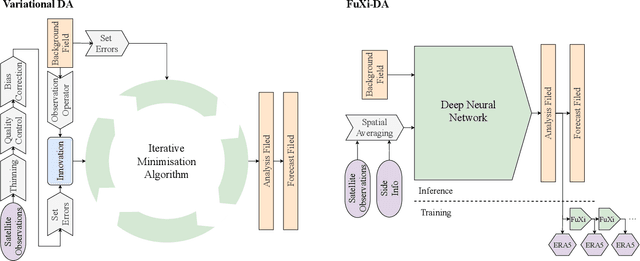



Data assimilation (DA), as an indispensable component within contemporary Numerical Weather Prediction (NWP) systems, plays a crucial role in generating the analysis that significantly impacts forecast performance. Nevertheless, the development of an efficient DA system poses significant challenges, particularly in establishing intricate relationships between the background data and the vast amount of multi-source observation data within limited time windows in operational settings. To address these challenges, researchers design complex pre-processing methods for each observation type, leveraging approximate modeling and the power of super-computing clusters to expedite solutions. The emergence of deep learning (DL) models has been a game-changer, offering unified multi-modal modeling, enhanced nonlinear representation capabilities, and superior parallelization. These advantages have spurred efforts to integrate DL models into various domains of weather modeling. Remarkably, DL models have shown promise in matching, even surpassing, the forecast accuracy of leading operational NWP models worldwide. This success motivates the exploration of DL-based DA frameworks tailored for weather forecasting models. In this study, we introduces FuxiDA, a generalized DL-based DA framework for assimilating satellite observations. By assimilating data from Advanced Geosynchronous Radiation Imager (AGRI) aboard Fengyun-4B, FuXi-DA consistently mitigates analysis errors and significantly improves forecast performance. Furthermore, through a series of single-observation experiments, Fuxi-DA has been validated against established atmospheric physics, demonstrating its consistency and reliability.
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
Sep 08, 2023



Large language models (LLMs) have emerged as a new paradigm for Text-to-SQL task. However, the absence of a systematical benchmark inhibits the development of designing effective, efficient and economic LLM-based Text-to-SQL solutions. To address this challenge, in this paper, we first conduct a systematical and extensive comparison over existing prompt engineering methods, including question representation, example selection and example organization, and with these experimental results, we elaborate their pros and cons. Based on these findings, we propose a new integrated solution, named DAIL-SQL, which refreshes the Spider leaderboard with 86.6% execution accuracy and sets a new bar. To explore the potential of open-source LLM, we investigate them in various scenarios, and further enhance their performance with supervised fine-tuning. Our explorations highlight open-source LLMs' potential in Text-to-SQL, as well as the advantages and disadvantages of the supervised fine-tuning. Additionally, towards an efficient and economic LLM-based Text-to-SQL solution, we emphasize the token efficiency in prompt engineering and compare the prior studies under this metric. We hope that our work provides a deeper understanding of Text-to-SQL with LLMs, and inspires further investigations and broad applications.
Avatar Knowledge Distillation: Self-ensemble Teacher Paradigm with Uncertainty
May 04, 2023Knowledge distillation is an effective paradigm for boosting the performance of pocket-size model, especially when multiple teacher models are available, the student would break the upper limit again. However, it is not economical to train diverse teacher models for the disposable distillation. In this paper, we introduce a new concept dubbed Avatars for distillation, which are the inference ensemble models derived from the teacher. Concretely, (1) For each iteration of distillation training, various Avatars are generated by a perturbation transformation. We validate that Avatars own higher upper limit of working capacity and teaching ability, aiding the student model in learning diverse and receptive knowledge perspectives from the teacher model. (2) During the distillation, we propose an uncertainty-aware factor from the variance of statistical differences between the vanilla teacher and Avatars, to adjust Avatars' contribution on knowledge transfer adaptively. Avatar Knowledge Distillation AKD is fundamentally different from existing methods and refines with the innovative view of unequal training. Comprehensive experiments demonstrate the effectiveness of our Avatars mechanism, which polishes up the state-of-the-art distillation methods for dense prediction without more extra computational cost. The AKD brings at most 0.7 AP gains on COCO 2017 for Object Detection and 1.83 mIoU gains on Cityscapes for Semantic Segmentation, respectively.
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
Mar 30, 2023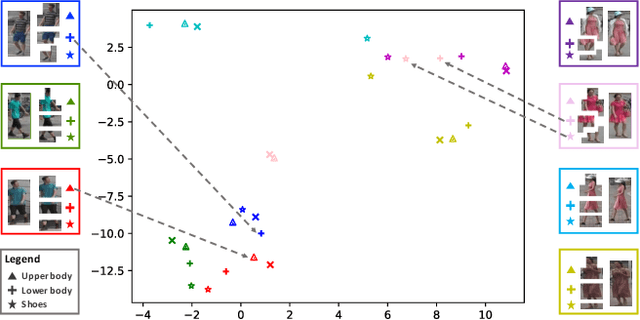
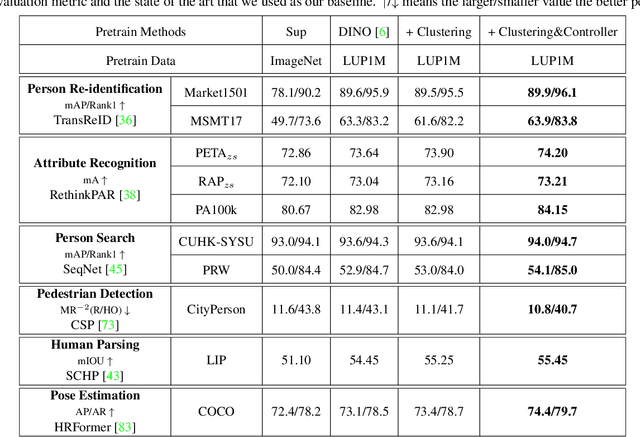
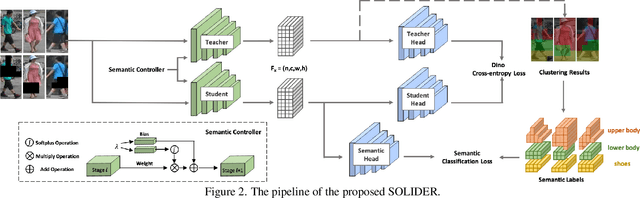
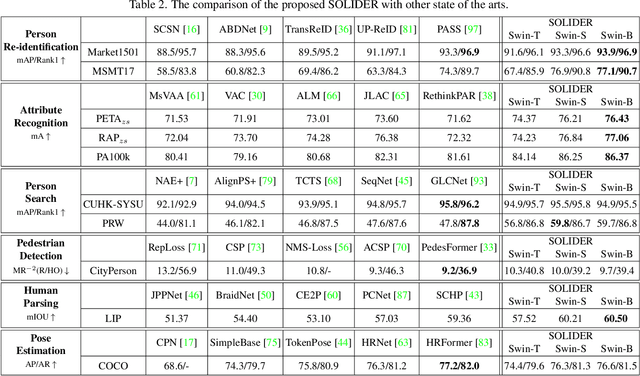
Human-centric visual tasks have attracted increasing research attention due to their widespread applications. In this paper, we aim to learn a general human representation from massive unlabeled human images which can benefit downstream human-centric tasks to the maximum extent. We call this method SOLIDER, a Semantic cOntrollable seLf-supervIseD lEaRning framework. Unlike the existing self-supervised learning methods, prior knowledge from human images is utilized in SOLIDER to build pseudo semantic labels and import more semantic information into the learned representation. Meanwhile, we note that different downstream tasks always require different ratios of semantic information and appearance information. For example, human parsing requires more semantic information, while person re-identification needs more appearance information for identification purpose. So a single learned representation cannot fit for all requirements. To solve this problem, SOLIDER introduces a conditional network with a semantic controller. After the model is trained, users can send values to the controller to produce representations with different ratios of semantic information, which can fit different needs of downstream tasks. Finally, SOLIDER is verified on six downstream human-centric visual tasks. It outperforms state of the arts and builds new baselines for these tasks. The code is released in https://github.com/tinyvision/SOLIDER.
DeepMAD: Mathematical Architecture Design for Deep Convolutional Neural Network
Mar 05, 2023



The rapid advances in Vision Transformer (ViT) refresh the state-of-the-art performances in various vision tasks, overshadowing the conventional CNN-based models. This ignites a few recent striking-back research in the CNN world showing that pure CNN models can achieve as good performance as ViT models when carefully tuned. While encouraging, designing such high-performance CNN models is challenging, requiring non-trivial prior knowledge of network design. To this end, a novel framework termed Mathematical Architecture Design for Deep CNN (DeepMAD) is proposed to design high-performance CNN models in a principled way. In DeepMAD, a CNN network is modeled as an information processing system whose expressiveness and effectiveness can be analytically formulated by their structural parameters. Then a constrained mathematical programming (MP) problem is proposed to optimize these structural parameters. The MP problem can be easily solved by off-the-shelf MP solvers on CPUs with a small memory footprint. In addition, DeepMAD is a pure mathematical framework: no GPU or training data is required during network design. The superiority of DeepMAD is validated on multiple large-scale computer vision benchmark datasets. Notably on ImageNet-1k, only using conventional convolutional layers, DeepMAD achieves 0.7% and 1.5% higher top-1 accuracy than ConvNeXt and Swin on Tiny level, and 0.8% and 0.9% higher on Small level.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 20233D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.