 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept Component Analysis: A Principled Approach for Concept Extraction in LLMs
Jan 29, 2026Developing human understandable interpretation of large language models (LLMs) becomes increasingly critical for their deployment in essential domains. Mechanistic interpretability seeks to mitigate the issues through extracts human-interpretable process and concepts from LLMs' activations. Sparse autoencoders (SAEs) have emerged as a popular approach for extracting interpretable and monosemantic concepts by decomposing the LLM internal representations into a dictionary. Despite their empirical progress, SAEs suffer from a fundamental theoretical ambiguity: the well-defined correspondence between LLM representations and human-interpretable concepts remains unclear. This lack of theoretical grounding gives rise to several methodological challenges, including difficulties in principled method design and evaluation criteria. In this work, we show that, under mild assumptions, LLM representations can be approximated as a {linear mixture} of the log-posteriors over concepts given the input context, through the lens of a latent variable model where concepts are treated as latent variables. This motivates a principled framework for concept extraction, namely Concept Component Analysis (ConCA), which aims to recover the log-posterior of each concept from LLM representations through a {unsupervised} linear unmixing process. We explore a specific variant, termed sparse ConCA, which leverages a sparsity prior to address the inherent ill-posedness of the unmixing problem. We implement 12 sparse ConCA variants and demonstrate their ability to extract meaningful concepts across multiple LLMs, offering theory-backed advantages over SAEs.
HyperAlign: Hypernetwork for Efficient Test-Time Alignment of Diffusion Models
Jan 22, 2026Diffusion models achieve state-of-the-art performance but often fail to generate outputs that align with human preferences and intentions, resulting in images with poor aesthetic quality and semantic inconsistencies. Existing alignment methods present a difficult trade-off: fine-tuning approaches suffer from loss of diversity with reward over-optimization, while test-time scaling methods introduce significant computational overhead and tend to under-optimize. To address these limitations, we propose HyperAlign, a novel framework that trains a hypernetwork for efficient and effective test-time alignment. Instead of modifying latent states, HyperAlign dynamically generates low-rank adaptation weights to modulate the diffusion model's generation operators. This allows the denoising trajectory to be adaptively adjusted based on input latents, timesteps and prompts for reward-conditioned alignment. We introduce multiple variants of HyperAlign that differ in how frequently the hypernetwork is applied, balancing between performance and efficiency. Furthermore, we optimize the hypernetwork using a reward score objective regularized with preference data to reduce reward hacking. We evaluate HyperAlign on multiple extended generative paradigms, including Stable Diffusion and FLUX. It significantly outperforms existing fine-tuning and test-time scaling baselines in enhancing semantic consistency and visual appeal.
Model Inversion with Layer-Specific Modeling and Alignment for Data-Free Continual Learning
Oct 30, 2025Continual learning (CL) aims to incrementally train a model on a sequence of tasks while retaining performance on prior ones. However, storing and replaying data is often infeasible due to privacy or security constraints and impractical for arbitrary pre-trained models. Data-free CL seeks to update models without access to previous data. Beyond regularization, we employ model inversion to synthesize data from the trained model, enabling replay without storing samples. Yet, model inversion in predictive models faces two challenges: (1) generating inputs solely from compressed output labels causes drift between synthetic and real data, and replaying such data can erode prior knowledge; (2) inversion is computationally expensive since each step backpropagates through the full model. These issues are amplified in large pre-trained models such as CLIP. To improve efficiency, we propose Per-layer Model Inversion (PMI), inspired by faster convergence in single-layer optimization. PMI provides strong initialization for full-model inversion, substantially reducing iterations. To mitigate feature shift, we model class-wise features via Gaussian distributions and contrastive model, ensuring alignment between synthetic and real features. Combining PMI and feature modeling, our approach enables continual learning of new classes by generating pseudo-images from semantic-aware projected features, achieving strong effectiveness and compatibility across multiple CL settings.
MultiEdit: Advancing Instruction-based Image Editing on Diverse and Challenging Tasks
Sep 18, 2025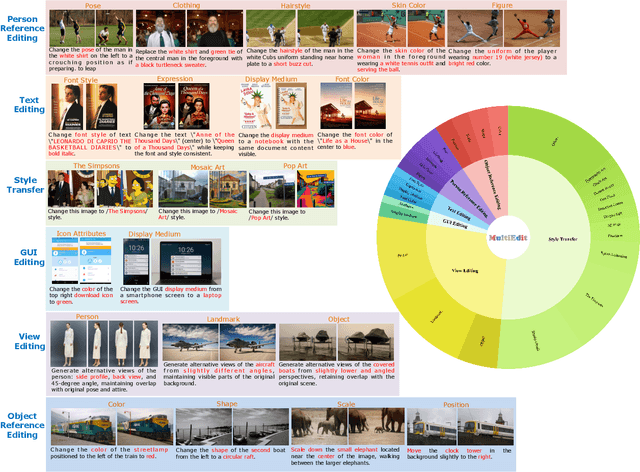
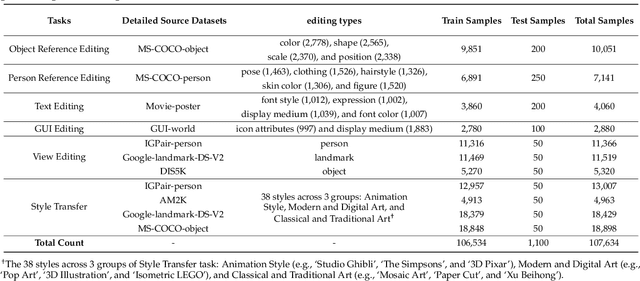
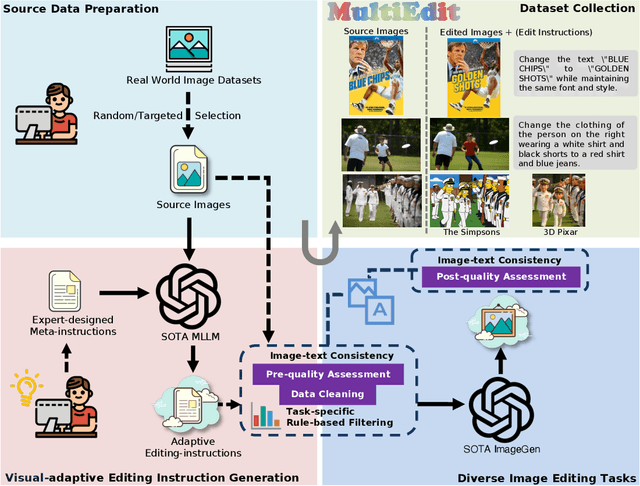
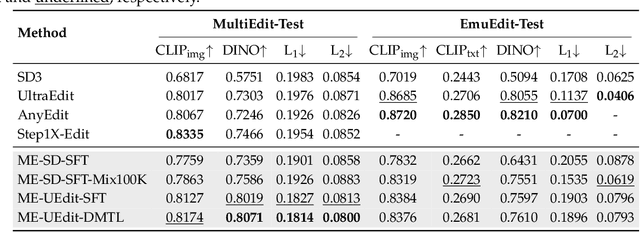
Current instruction-based image editing (IBIE) methods struggle with challenging editing tasks, as both editing types and sample counts of existing datasets are limited. Moreover, traditional dataset construction often contains noisy image-caption pairs, which may introduce biases and limit model capabilities in complex editing scenarios. To address these limitations, we introduce MultiEdit, a comprehensive dataset featuring over 107K high-quality image editing samples. It encompasses 6 challenging editing tasks through a diverse collection of 18 non-style-transfer editing types and 38 style transfer operations, covering a spectrum from sophisticated style transfer to complex semantic operations like person reference editing and in-image text editing. We employ a novel dataset construction pipeline that utilizes two multi-modal large language models (MLLMs) to generate visual-adaptive editing instructions and produce high-fidelity edited images, respectively. Extensive experiments demonstrate that fine-tuning foundational open-source models with our MultiEdit-Train set substantially improves models' performance on sophisticated editing tasks in our proposed MultiEdit-Test benchmark, while effectively preserving their capabilities on the standard editing benchmark. We believe MultiEdit provides a valuable resource for advancing research into more diverse and challenging IBIE capabilities. Our dataset is available at https://huggingface.co/datasets/inclusionAI/MultiEdit.
Little By Little: Continual Learning via Self-Activated Sparse Mixture-of-Rank Adaptive Learning
Jun 26, 2025



Continual learning (CL) with large pre-trained models is challenged by catastrophic forgetting and task interference. Existing LoRA-based Mixture-of-Experts (MoE) approaches mitigate forgetting by assigning and freezing task-specific adapters, but suffer from interference, redundancy, and ambiguous routing due to coarse adapter-level selection. However, this design introduces three key challenges: 1) Interference: Activating full LoRA experts per input leads to subspace interference and prevents selective reuse of useful components across tasks. 2) Redundancy: Newly added experts often duplicate or contradict existing knowledge due to unnecessary activation of unrelated ranks and insufficient reuse of relevant ones. 3) Ambiguity: Overlapping features across tasks confuse the router, resulting in unstable expert assignments. As more experts accumulate, earlier task routing degrades, accelerating forgetting. We propose MoRA, a Mixture-of-Rank Adaptive learning approach with self-activated and sparse rank activation for CL. Unlike mixing multiple low-rank matrices, MoRA decomposes each rank-r update into r rank-1 components, each treated as an independent expert, enabling fine-grained mixture of rank-1 expert utilization while mitigating interference and redundancy. To avoid ambiguous routing, we propose that each rank-1 expert can infer its own relevance via intermediate activations. Coupled with our proposed rank pruning and activation budgets, MoRA adaptively selects a sparse mixture of ranks per input. We validate MoRA on continual learning tasks with CLIP and large language models (LLMs), analyzing both in-domain learning and out-of-domain forgetting/generalization during fine-tuning. MoRA shows significant effectiveness on enhancing CL with PTMs, and improving generalization while mitigating forgetting.
Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time Distillation
Jun 24, 2025Distilled video generation models offer fast and efficient synthesis but struggle with motion customization when guided by reference videos, especially under training-free settings. Existing training-free methods, originally designed for standard diffusion models, fail to generalize due to the accelerated generative process and large denoising steps in distilled models. To address this, we propose MotionEcho, a novel training-free test-time distillation framework that enables motion customization by leveraging diffusion teacher forcing. Our approach uses high-quality, slow teacher models to guide the inference of fast student models through endpoint prediction and interpolation. To maintain efficiency, we dynamically allocate computation across timesteps according to guidance needs. Extensive experiments across various distilled video generation models and benchmark datasets demonstrate that our method significantly improves motion fidelity and generation quality while preserving high efficiency. Project page: https://euminds.github.io/motionecho/
Let Your Video Listen to Your Music!
Jun 23, 2025Aligning the rhythm of visual motion in a video with a given music track is a practical need in multimedia production, yet remains an underexplored task in autonomous video editing. Effective alignment between motion and musical beats enhances viewer engagement and visual appeal, particularly in music videos, promotional content, and cinematic editing. Existing methods typically depend on labor-intensive manual cutting, speed adjustments, or heuristic-based editing techniques to achieve synchronization. While some generative models handle joint video and music generation, they often entangle the two modalities, limiting flexibility in aligning video to music beats while preserving the full visual content. In this paper, we propose a novel and efficient framework, termed MVAA (Music-Video Auto-Alignment), that automatically edits video to align with the rhythm of a given music track while preserving the original visual content. To enhance flexibility, we modularize the task into a two-step process in our MVAA: aligning motion keyframes with audio beats, followed by rhythm-aware video inpainting. Specifically, we first insert keyframes at timestamps aligned with musical beats, then use a frame-conditioned diffusion model to generate coherent intermediate frames, preserving the original video's semantic content. Since comprehensive test-time training can be time-consuming, we adopt a two-stage strategy: pretraining the inpainting module on a small video set to learn general motion priors, followed by rapid inference-time fine-tuning for video-specific adaptation. This hybrid approach enables adaptation within 10 minutes with one epoch on a single NVIDIA 4090 GPU using CogVideoX-5b-I2V as the backbone. Extensive experiments show that our approach can achieve high-quality beat alignment and visual smoothness.
Continual Learning on CLIP via Incremental Prompt Tuning with Intrinsic Textual Anchors
May 27, 2025Continual learning (CL) enables deep networks to acquire new knowledge while avoiding catastrophic forgetting. The powerful generalization ability of pre-trained models (PTMs), such as the Contrastive Language-Image Pre-training (CLIP) model, has inspired a range of CL methods targeting new and specialized tasks, providing rich multi-modal embeddings that support lightweight, incremental prompt tuning. Existing methods often rely on complex designs built upon specific assumptions, such as intricate regularization schemes for prompt pools, specialized routing mechanisms, or multi-stage incrementations, that introduce additional-and possibly unnecessary-complexity, underutilizing CLIP's intrinsic capabilities. In this paper, we propose a concise CL approach for CLIP based on incremental prompt tuning that fully exploits its multi-modal structure and the stability of textual representations. Our method, Textual Prototype-guided Prompt Tuning (TPPT), introduces textual prototypes not merely as static classifiers, as in existing methods, but as stable anchors to guide the learning of visual prompts, thereby shaping the embedding space (i.e., TPPT-V). We show that our bidirectional supervision strategy enables more effective learning of new knowledge while reducing forgetting. To further close the vision-language gap during CL, we jointly optimizes visual and textual prompts (i.e., TPPT-VT). We also introduce a relational diversity regularization on the textual anchors to prevent embedding space collapse and mitigate correlated forgetting. Extensive experiments and analyses demonstrate the effectiveness of our proposed approach, highlighting the benefits of leveraging CLIP's intrinsic guidance for continual adaptation.
Hierarchical and Step-Layer-Wise Tuning of Attention Specialty for Multi-Instance Synthesis in Diffusion Transformers
Apr 14, 2025Text-to-image (T2I) generation models often struggle with multi-instance synthesis (MIS), where they must accurately depict multiple distinct instances in a single image based on complex prompts detailing individual features. Traditional MIS control methods for UNet architectures like SD v1.5/SDXL fail to adapt to DiT-based models like FLUX and SD v3.5, which rely on integrated attention between image and text tokens rather than text-image cross-attention. To enhance MIS in DiT, we first analyze the mixed attention mechanism in DiT. Our token-wise and layer-wise analysis of attention maps reveals a hierarchical response structure: instance tokens dominate early layers, background tokens in middle layers, and attribute tokens in later layers. Building on this observation, we propose a training-free approach for enhancing MIS in DiT-based models with hierarchical and step-layer-wise attention specialty tuning (AST). AST amplifies key regions while suppressing irrelevant areas in distinct attention maps across layers and steps, guided by the hierarchical structure. This optimizes multimodal interactions by hierarchically decoupling the complex prompts with instance-based sketches. We evaluate our approach using upgraded sketch-based layouts for the T2I-CompBench and customized complex scenes. Both quantitative and qualitative results confirm our method enhances complex layout generation, ensuring precise instance placement and attribute representation in MIS.
Analytic DAG Constraints for Differentiable DAG Learning
Mar 24, 2025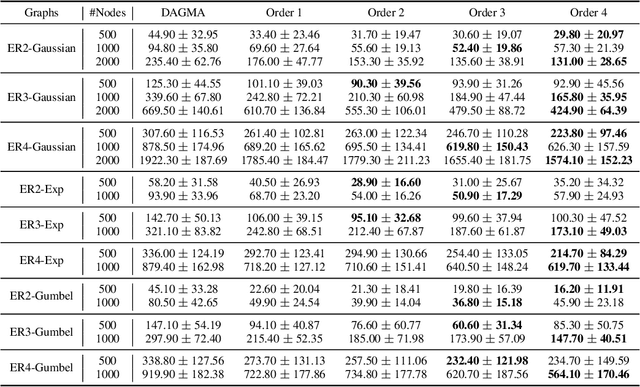
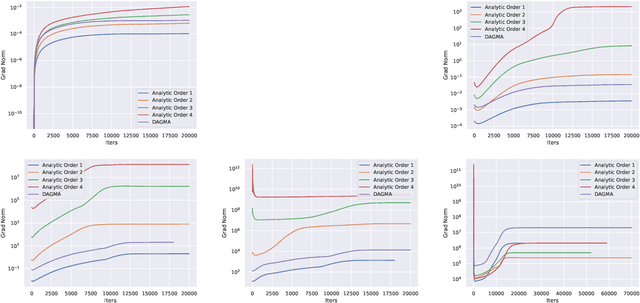
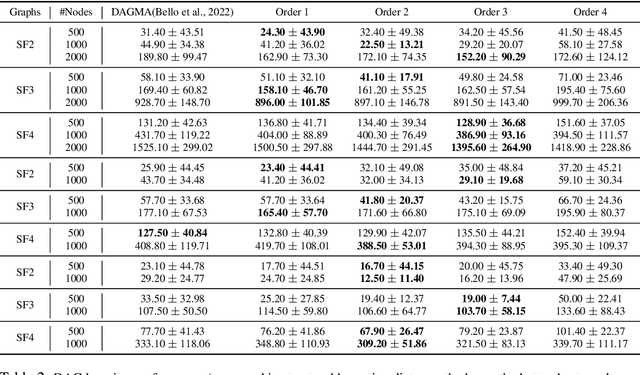

Recovering the underlying Directed Acyclic Graph (DAG) structures from observational data presents a formidable challenge, partly due to the combinatorial nature of the DAG-constrained optimization problem. Recently, researchers have identified gradient vanishing as one of the primary obstacles in differentiable DAG learning and have proposed several DAG constraints to mitigate this issue. By developing the necessary theory to establish a connection between analytic functions and DAG constraints, we demonstrate that analytic functions from the set $\{f(x) = c_0 + \sum_{i=1}^{\infty}c_ix^i | \forall i > 0, c_i > 0; r = \lim_{i\rightarrow \infty}c_{i}/c_{i+1} > 0\}$ can be employed to formulate effective DAG constraints. Furthermore, we establish that this set of functions is closed under several functional operators, including differentiation, summation, and multiplication. Consequently, these operators can be leveraged to create novel DAG constraints based on existing ones. Using these properties, we design a series of DAG constraints and develop an efficient algorithm to evaluate them. Experiments in various settings demonstrate that our DAG constraints outperform previous state-of-the-art comparators. Our implementation is available at https://github.com/zzhang1987/AnalyticDAGLearning.
* Accepted to ICLR 2025