 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Token's Dilemma: Dynamic MoE with Drift-Aware Token Assignment for Continual Learning of Large Vision Language Models
Mar 29, 2026Multimodal Continual Instruction Tuning aims to continually enhance Large Vision Language Models (LVLMs) by learning from new data without forgetting previously acquired knowledge. Mixture of Experts (MoE) architectures naturally facilitate this by incrementally adding new experts and expanding routers while keeping the existing ones frozen. However, despite expert isolation, MoE-based continual learners still suffer from forgetting due to routing-drift: old-task tokens become mistakenly attracted to newly added experts, degrading performance on prior tasks. We analyze the failure mode at the token level and reveal the token's dilemma: ambiguous and old tokens in new-task data offer minimal learning benefit yet induce forgetting when routed to new experts, due to their ambiguous routing assignment during training. Motivated by this, we propose LLaVA-DyMoE, a dynamic MoE framework that incrementally expands the MoE with drift-aware token assignment. We characterize token types via their routing score distributions and apply targeted regularization. Specifically, a token-level assignment guidance steers ambiguous and old tokens away from new experts to preserve established routing patterns and alleviate routing-drift, while complementary routing score regularizations enforce expert-group separation and promote new-expert specialization. Extensive experiments demonstrate that our LLaVA-DyMoE effectively mitigates routing-drift-induced forgetting, achieving over a 7% gain in mean final accuracy and a 12% reduction in forgetting compared to baselines. The project page is https://zhaoc5.github.io/DyMoE.
MM-OpenFGL: A Comprehensive Benchmark for Multimodal Federated Graph Learning
Jan 29, 2026Multimodal-attributed graphs (MMAGs) provide a unified framework for modeling complex relational data by integrating heterogeneous modalities with graph structures. While centralized learning has shown promising performance, MMAGs in real-world applications are often distributed across isolated platforms and cannot be shared due to privacy concerns or commercial constraints. Federated graph learning (FGL) offers a natural solution for collaborative training under such settings; however, existing studies largely focus on single-modality graphs and do not adequately address the challenges unique to multimodal federated graph learning (MMFGL). To bridge this gap, we present MM-OpenFGL, the first comprehensive benchmark that systematically formalizes the MMFGL paradigm and enables rigorous evaluation. MM-OpenFGL comprises 19 multimodal datasets spanning 7 application domains, 8 simulation strategies capturing modality and topology variations, 6 downstream tasks, and 57 state-of-the-art methods implemented through a modular API. Extensive experiments investigate MMFGL from the perspectives of necessity, effectiveness, robustness, and efficiency, offering valuable insights for future research on MMFGL.
DANCE: Dynamic, Available, Neighbor-gated Condensation for Federated Text-Attributed Graphs
Jan 23, 2026Federated graph learning (FGL) enables collaborative training on graph data across multiple clients. With the rise of large language models (LLMs), textual attributes in FGL graphs are gaining attention. Text-attributed graph federated learning (TAG-FGL) improves FGL by explicitly leveraging LLMs to process and integrate these textual features. However, current TAG-FGL methods face three main challenges: \textbf{(1) Overhead.} LLMs for processing long texts incur high token and computation costs. To make TAG-FGL practical, we introduce graph condensation (GC) to reduce computation load, but this choice also brings new issues. \textbf{(2) Suboptimal.} To reduce LLM overhead, we introduce GC into TAG-FGL by compressing multi-hop texts/neighborhoods into a condensed core with fixed LLM surrogates. However, this one-shot condensation is often not client-adaptive, leading to suboptimal performance. \textbf{(3) Interpretability.} LLM-based condensation further introduces a black-box bottleneck: summaries lack faithful attribution and clear grounding to specific source spans, making local inspection and auditing difficult. To address the above issues, we propose \textbf{DANCE}, a new TAG-FGL paradigm with GC. To improve \textbf{suboptimal} performance, DANCE performs round-wise, model-in-the-loop condensation refresh using the latest global model. To enhance \textbf{interpretability}, DANCE preserves provenance by storing locally inspectable evidence packs that trace predictions to selected neighbors and source text spans. Across 8 TAG datasets, DANCE improves accuracy by \textbf{2.33\%} at an \textbf{8\%} condensation ratio, with \textbf{33.42\%} fewer tokens than baselines.
Model Inversion with Layer-Specific Modeling and Alignment for Data-Free Continual Learning
Oct 30, 2025Continual learning (CL) aims to incrementally train a model on a sequence of tasks while retaining performance on prior ones. However, storing and replaying data is often infeasible due to privacy or security constraints and impractical for arbitrary pre-trained models. Data-free CL seeks to update models without access to previous data. Beyond regularization, we employ model inversion to synthesize data from the trained model, enabling replay without storing samples. Yet, model inversion in predictive models faces two challenges: (1) generating inputs solely from compressed output labels causes drift between synthetic and real data, and replaying such data can erode prior knowledge; (2) inversion is computationally expensive since each step backpropagates through the full model. These issues are amplified in large pre-trained models such as CLIP. To improve efficiency, we propose Per-layer Model Inversion (PMI), inspired by faster convergence in single-layer optimization. PMI provides strong initialization for full-model inversion, substantially reducing iterations. To mitigate feature shift, we model class-wise features via Gaussian distributions and contrastive model, ensuring alignment between synthetic and real features. Combining PMI and feature modeling, our approach enables continual learning of new classes by generating pseudo-images from semantic-aware projected features, achieving strong effectiveness and compatibility across multiple CL settings.
Little By Little: Continual Learning via Self-Activated Sparse Mixture-of-Rank Adaptive Learning
Jun 26, 2025



Continual learning (CL) with large pre-trained models is challenged by catastrophic forgetting and task interference. Existing LoRA-based Mixture-of-Experts (MoE) approaches mitigate forgetting by assigning and freezing task-specific adapters, but suffer from interference, redundancy, and ambiguous routing due to coarse adapter-level selection. However, this design introduces three key challenges: 1) Interference: Activating full LoRA experts per input leads to subspace interference and prevents selective reuse of useful components across tasks. 2) Redundancy: Newly added experts often duplicate or contradict existing knowledge due to unnecessary activation of unrelated ranks and insufficient reuse of relevant ones. 3) Ambiguity: Overlapping features across tasks confuse the router, resulting in unstable expert assignments. As more experts accumulate, earlier task routing degrades, accelerating forgetting. We propose MoRA, a Mixture-of-Rank Adaptive learning approach with self-activated and sparse rank activation for CL. Unlike mixing multiple low-rank matrices, MoRA decomposes each rank-r update into r rank-1 components, each treated as an independent expert, enabling fine-grained mixture of rank-1 expert utilization while mitigating interference and redundancy. To avoid ambiguous routing, we propose that each rank-1 expert can infer its own relevance via intermediate activations. Coupled with our proposed rank pruning and activation budgets, MoRA adaptively selects a sparse mixture of ranks per input. We validate MoRA on continual learning tasks with CLIP and large language models (LLMs), analyzing both in-domain learning and out-of-domain forgetting/generalization during fine-tuning. MoRA shows significant effectiveness on enhancing CL with PTMs, and improving generalization while mitigating forgetting.
Continual Learning on CLIP via Incremental Prompt Tuning with Intrinsic Textual Anchors
May 27, 2025Continual learning (CL) enables deep networks to acquire new knowledge while avoiding catastrophic forgetting. The powerful generalization ability of pre-trained models (PTMs), such as the Contrastive Language-Image Pre-training (CLIP) model, has inspired a range of CL methods targeting new and specialized tasks, providing rich multi-modal embeddings that support lightweight, incremental prompt tuning. Existing methods often rely on complex designs built upon specific assumptions, such as intricate regularization schemes for prompt pools, specialized routing mechanisms, or multi-stage incrementations, that introduce additional-and possibly unnecessary-complexity, underutilizing CLIP's intrinsic capabilities. In this paper, we propose a concise CL approach for CLIP based on incremental prompt tuning that fully exploits its multi-modal structure and the stability of textual representations. Our method, Textual Prototype-guided Prompt Tuning (TPPT), introduces textual prototypes not merely as static classifiers, as in existing methods, but as stable anchors to guide the learning of visual prompts, thereby shaping the embedding space (i.e., TPPT-V). We show that our bidirectional supervision strategy enables more effective learning of new knowledge while reducing forgetting. To further close the vision-language gap during CL, we jointly optimizes visual and textual prompts (i.e., TPPT-VT). We also introduce a relational diversity regularization on the textual anchors to prevent embedding space collapse and mitigate correlated forgetting. Extensive experiments and analyses demonstrate the effectiveness of our proposed approach, highlighting the benefits of leveraging CLIP's intrinsic guidance for continual adaptation.
Adaptive Rank, Reduced Forgetting: Knowledge Retention in Continual Learning Vision-Language Models with Dynamic Rank-Selective LoRA
Dec 03, 2024We investigate whether the pre-trained knowledge of vision-language models (VLMs), such as CLIP, can be retained or even enhanced during continual learning (CL) while absorbing knowledge from a data stream. Existing methods often rely on additional reference data, isolated components for distribution or domain predictions, leading to high training costs, increased inference complexity, and limited improvement potential for pre-trained models. To address these challenges, we first comprehensively analyze the effects of parameter update locations and ranks on downstream adaptation and knowledge retention. Based on these insights, we propose Dynamic Rank-Selective Low Rank Adaptation (LoRA), a universal and efficient CL approach that adaptively assigns ranks to LoRA modules based on their relevance to the current data. Unlike prior methods, our approach continually enhances the pre-trained VLM by retaining both the pre-trained knowledge and the knowledge acquired during CL. Our approach eliminates the need for explicit domain or distribution prediction and additional reference data, enabling seamless integration of new tasks while preserving pre-trained capabilities. It also maintains the original architecture and deployment pipeline of the pre-trained model without incurring any additional inference overhead. Extensive experiments and analyses demonstrate that our method outperforms state-of-the-art approaches in continually absorbing knowledge of downstream tasks while retaining pre-trained knowledge.
Self-Expansion of Pre-trained Models with Mixture of Adapters for Continual Learning
Mar 27, 2024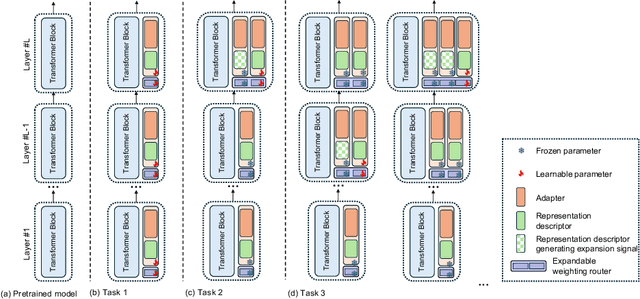
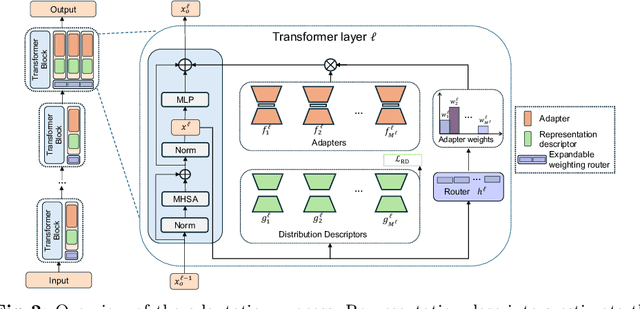
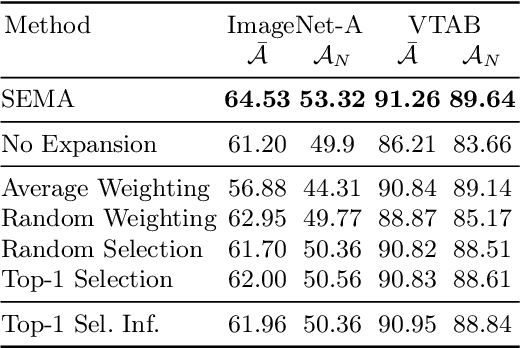
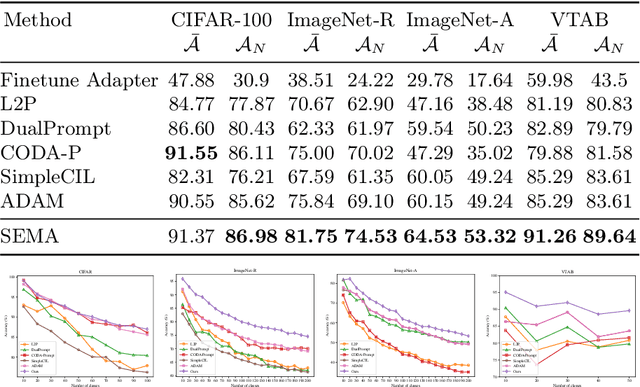
Continual learning aims to learn from a stream of continuously arriving data with minimum forgetting of previously learned knowledge. While previous works have explored the effectiveness of leveraging the generalizable knowledge from pre-trained models in continual learning, existing parameter-efficient fine-tuning approaches focus on the use of a predetermined or task-wise set of adapters or prompts. However, these approaches still suffer from forgetting due to task interference on jointly used parameters or restricted flexibility. The reliance on a static model architecture may lead to the allocation of excessive parameters that are not essential or, conversely, inadequate adaptation for downstream tasks, given that the scale and distribution of incoming data are unpredictable in continual learning. We propose Self-Expansion of pre-trained models with Modularized Adaptation (SEMA), a novel fine-tuning approach which automatically decides to reuse or add adapter modules on demand in continual learning, depending on whether drastic distribution shift that could not be handled by existing modules is detected at different representation levels. We design each adapter module to consist of an adapter and a representation descriptor, specifically, implemented as an autoencoder. The representation descriptor functions as a distributional shift indicator during training and triggers adapter expansion. For better usage of the adapters, an expandable weighting router is learned jointly for mixture of adapter outputs. By comparing with vision-transformer-based continual learning adaptation methods, we demonstrate that the proposed framework outperforms the state-of-the-art without memory rehearsal.
Learning with Mixture of Prototypes for Out-of-Distribution Detection
Feb 05, 2024



Out-of-distribution (OOD) detection aims to detect testing samples far away from the in-distribution (ID) training data, which is crucial for the safe deployment of machine learning models in the real world. Distance-based OOD detection methods have emerged with enhanced deep representation learning. They identify unseen OOD samples by measuring their distances from ID class centroids or prototypes. However, existing approaches learn the representation relying on oversimplified data assumptions, e.g, modeling ID data of each class with one centroid class prototype or using loss functions not designed for OOD detection, which overlook the natural diversities within the data. Naively enforcing data samples of each class to be compact around only one prototype leads to inadequate modeling of realistic data and limited performance. To tackle these issues, we propose PrototypicAl Learning with a Mixture of prototypes (PALM) which models each class with multiple prototypes to capture the sample diversities, and learns more faithful and compact samples embeddings to enhance OOD detection. Our method automatically identifies and dynamically updates prototypes, assigning each sample to a subset of prototypes via reciprocal neighbor soft assignment weights. PALM optimizes a maximum likelihood estimation (MLE) loss to encourage the sample embeddings to be compact around the associated prototypes, as well as a contrastive loss on all prototypes to enhance intra-class compactness and inter-class discrimination at the prototype level. Moreover, the automatic estimation of prototypes enables our approach to be extended to the challenging OOD detection task with unlabelled ID data. Extensive experiments demonstrate the superiority of PALM, achieving state-of-the-art average AUROC performance of 93.82 on the challenging CIFAR-100 benchmark. Code is available at https://github.com/jeff024/PALM.