 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximation Algorithm for Constrained $k$-Center Clustering: A Local Search Approach
Jan 17, 2026Clustering is a long-standing research problem and a fundamental tool in AI and data analysis. The traditional k-center problem, a fundamental theoretical challenge in clustering, has a best possible approximation ratio of 2, and any improvement to a ratio of 2 - ε would imply P = NP. In this work, we study the constrained k-center clustering problem, where instance-level cannot-link (CL) and must-link (ML) constraints are incorporated as background knowledge. Although general CL constraints significantly increase the hardness of approximation, previous work has shown that disjoint CL sets permit constant-factor approximations. However, whether local search can achieve such a guarantee in this setting remains an open question. To this end, we propose a novel local search framework based on a transformation to a dominating matching set problem, achieving the best possible approximation ratio of 2. The experimental results on both real-world and synthetic datasets demonstrate that our algorithm outperforms baselines in solution quality.
Cross-Modal Unlearning via Influential Neuron Path Editing in Multimodal Large Language Models
Nov 10, 2025Multimodal Large Language Models (MLLMs) extend foundation models to real-world applications by integrating inputs such as text and vision. However, their broad knowledge capacity raises growing concerns about privacy leakage, toxicity mitigation, and intellectual property violations. Machine Unlearning (MU) offers a practical solution by selectively forgetting targeted knowledge while preserving overall model utility. When applied to MLLMs, existing neuron-editing-based MU approaches face two fundamental challenges: (1) forgetting becomes inconsistent across modalities because existing point-wise attribution methods fail to capture the structured, layer-by-layer information flow that connects different modalities; and (2) general knowledge performance declines when sensitive neurons that also support important reasoning paths are pruned, as this disrupts the model's ability to generalize. To alleviate these limitations, we propose a multimodal influential neuron path editor (MIP-Editor) for MU. Our approach introduces modality-specific attribution scores to identify influential neuron paths responsible for encoding forget-set knowledge and applies influential-path-aware neuron-editing via representation misdirection. This strategy also enables effective and coordinated forgetting across modalities while preserving the model's general capabilities. Experimental results demonstrate that MIP-Editor achieves a superior unlearning performance on multimodal tasks, with a maximum forgetting rate of 87.75% and up to 54.26% improvement in general knowledge retention. On textual tasks, MIP-Editor achieves up to 80.65% forgetting and preserves 77.9% of general performance. Codes are available at https://github.com/PreckLi/MIP-Editor.
Little By Little: Continual Learning via Self-Activated Sparse Mixture-of-Rank Adaptive Learning
Jun 26, 2025



Continual learning (CL) with large pre-trained models is challenged by catastrophic forgetting and task interference. Existing LoRA-based Mixture-of-Experts (MoE) approaches mitigate forgetting by assigning and freezing task-specific adapters, but suffer from interference, redundancy, and ambiguous routing due to coarse adapter-level selection. However, this design introduces three key challenges: 1) Interference: Activating full LoRA experts per input leads to subspace interference and prevents selective reuse of useful components across tasks. 2) Redundancy: Newly added experts often duplicate or contradict existing knowledge due to unnecessary activation of unrelated ranks and insufficient reuse of relevant ones. 3) Ambiguity: Overlapping features across tasks confuse the router, resulting in unstable expert assignments. As more experts accumulate, earlier task routing degrades, accelerating forgetting. We propose MoRA, a Mixture-of-Rank Adaptive learning approach with self-activated and sparse rank activation for CL. Unlike mixing multiple low-rank matrices, MoRA decomposes each rank-r update into r rank-1 components, each treated as an independent expert, enabling fine-grained mixture of rank-1 expert utilization while mitigating interference and redundancy. To avoid ambiguous routing, we propose that each rank-1 expert can infer its own relevance via intermediate activations. Coupled with our proposed rank pruning and activation budgets, MoRA adaptively selects a sparse mixture of ranks per input. We validate MoRA on continual learning tasks with CLIP and large language models (LLMs), analyzing both in-domain learning and out-of-domain forgetting/generalization during fine-tuning. MoRA shows significant effectiveness on enhancing CL with PTMs, and improving generalization while mitigating forgetting.
Continual Learning on CLIP via Incremental Prompt Tuning with Intrinsic Textual Anchors
May 27, 2025Continual learning (CL) enables deep networks to acquire new knowledge while avoiding catastrophic forgetting. The powerful generalization ability of pre-trained models (PTMs), such as the Contrastive Language-Image Pre-training (CLIP) model, has inspired a range of CL methods targeting new and specialized tasks, providing rich multi-modal embeddings that support lightweight, incremental prompt tuning. Existing methods often rely on complex designs built upon specific assumptions, such as intricate regularization schemes for prompt pools, specialized routing mechanisms, or multi-stage incrementations, that introduce additional-and possibly unnecessary-complexity, underutilizing CLIP's intrinsic capabilities. In this paper, we propose a concise CL approach for CLIP based on incremental prompt tuning that fully exploits its multi-modal structure and the stability of textual representations. Our method, Textual Prototype-guided Prompt Tuning (TPPT), introduces textual prototypes not merely as static classifiers, as in existing methods, but as stable anchors to guide the learning of visual prompts, thereby shaping the embedding space (i.e., TPPT-V). We show that our bidirectional supervision strategy enables more effective learning of new knowledge while reducing forgetting. To further close the vision-language gap during CL, we jointly optimizes visual and textual prompts (i.e., TPPT-VT). We also introduce a relational diversity regularization on the textual anchors to prevent embedding space collapse and mitigate correlated forgetting. Extensive experiments and analyses demonstrate the effectiveness of our proposed approach, highlighting the benefits of leveraging CLIP's intrinsic guidance for continual adaptation.
Adaptive Rank, Reduced Forgetting: Knowledge Retention in Continual Learning Vision-Language Models with Dynamic Rank-Selective LoRA
Dec 03, 2024We investigate whether the pre-trained knowledge of vision-language models (VLMs), such as CLIP, can be retained or even enhanced during continual learning (CL) while absorbing knowledge from a data stream. Existing methods often rely on additional reference data, isolated components for distribution or domain predictions, leading to high training costs, increased inference complexity, and limited improvement potential for pre-trained models. To address these challenges, we first comprehensively analyze the effects of parameter update locations and ranks on downstream adaptation and knowledge retention. Based on these insights, we propose Dynamic Rank-Selective Low Rank Adaptation (LoRA), a universal and efficient CL approach that adaptively assigns ranks to LoRA modules based on their relevance to the current data. Unlike prior methods, our approach continually enhances the pre-trained VLM by retaining both the pre-trained knowledge and the knowledge acquired during CL. Our approach eliminates the need for explicit domain or distribution prediction and additional reference data, enabling seamless integration of new tasks while preserving pre-trained capabilities. It also maintains the original architecture and deployment pipeline of the pre-trained model without incurring any additional inference overhead. Extensive experiments and analyses demonstrate that our method outperforms state-of-the-art approaches in continually absorbing knowledge of downstream tasks while retaining pre-trained knowledge.
Effects of Exponential Gaussian Distribution on (Double Sampling) Randomized Smoothing
Jun 04, 2024

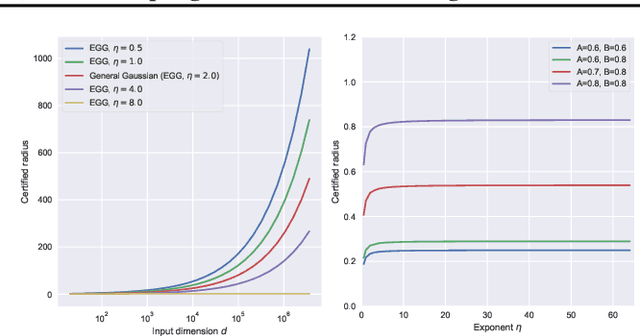

Randomized Smoothing (RS) is currently a scalable certified defense method providing robustness certification against adversarial examples. Although significant progress has been achieved in providing defenses against $\ell_p$ adversaries, the interaction between the smoothing distribution and the robustness certification still remains vague. In this work, we comprehensively study the effect of two families of distributions, named Exponential Standard Gaussian (ESG) and Exponential General Gaussian (EGG) distributions, on Randomized Smoothing and Double Sampling Randomized Smoothing (DSRS). We derive an analytic formula for ESG's certified radius, which converges to the origin formula of RS as the dimension $d$ increases. Additionally, we prove that EGG can provide tighter constant factors than DSRS in providing $\Omega(\sqrt{d})$ lower bounds of $\ell_2$ certified radius, and thus further addresses the curse of dimensionality in RS. Our experiments on real-world datasets confirm our theoretical analysis of the ESG distributions, that they provide almost the same certification under different exponents $\eta$ for both RS and DSRS. In addition, EGG
Learning with Mixture of Prototypes for Out-of-Distribution Detection
Feb 05, 2024



Out-of-distribution (OOD) detection aims to detect testing samples far away from the in-distribution (ID) training data, which is crucial for the safe deployment of machine learning models in the real world. Distance-based OOD detection methods have emerged with enhanced deep representation learning. They identify unseen OOD samples by measuring their distances from ID class centroids or prototypes. However, existing approaches learn the representation relying on oversimplified data assumptions, e.g, modeling ID data of each class with one centroid class prototype or using loss functions not designed for OOD detection, which overlook the natural diversities within the data. Naively enforcing data samples of each class to be compact around only one prototype leads to inadequate modeling of realistic data and limited performance. To tackle these issues, we propose PrototypicAl Learning with a Mixture of prototypes (PALM) which models each class with multiple prototypes to capture the sample diversities, and learns more faithful and compact samples embeddings to enhance OOD detection. Our method automatically identifies and dynamically updates prototypes, assigning each sample to a subset of prototypes via reciprocal neighbor soft assignment weights. PALM optimizes a maximum likelihood estimation (MLE) loss to encourage the sample embeddings to be compact around the associated prototypes, as well as a contrastive loss on all prototypes to enhance intra-class compactness and inter-class discrimination at the prototype level. Moreover, the automatic estimation of prototypes enables our approach to be extended to the challenging OOD detection task with unlabelled ID data. Extensive experiments demonstrate the superiority of PALM, achieving state-of-the-art average AUROC performance of 93.82 on the challenging CIFAR-100 benchmark. Code is available at https://github.com/jeff024/PALM.