 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGSNav: Enhancing Vision-Language Model Reasoning for Object Navigation via Active 3D Gaussian Splatting
Feb 12, 2026Object navigation is a core capability of embodied intelligence, enabling an agent to locate target objects in unknown environments. Recent advances in vision-language models (VLMs) have facilitated zero-shot object navigation (ZSON). However, existing methods often rely on scene abstractions that convert environments into semantic maps or textual representations, causing high-level decision making to be constrained by the accuracy of low-level perception. In this work, we present 3DGSNav, a novel ZSON framework that embeds 3D Gaussian Splatting (3DGS) as persistent memory for VLMs to enhance spatial reasoning. Through active perception, 3DGSNav incrementally constructs a 3DGS representation of the environment, enabling trajectory-guided free-viewpoint rendering of frontier-aware first-person views. Moreover, we design structured visual prompts and integrate them with Chain-of-Thought (CoT) prompting to further improve VLM reasoning. During navigation, a real-time object detector filters potential targets, while VLM-driven active viewpoint switching performs target re-verification, ensuring efficient and reliable recognition. Extensive evaluations across multiple benchmarks and real-world experiments on a quadruped robot demonstrate that our method achieves robust and competitive performance against state-of-the-art approaches.The Project Page:https://aczheng-cai.github.io/3dgsnav.github.io/
Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time Distillation
Jun 24, 2025Distilled video generation models offer fast and efficient synthesis but struggle with motion customization when guided by reference videos, especially under training-free settings. Existing training-free methods, originally designed for standard diffusion models, fail to generalize due to the accelerated generative process and large denoising steps in distilled models. To address this, we propose MotionEcho, a novel training-free test-time distillation framework that enables motion customization by leveraging diffusion teacher forcing. Our approach uses high-quality, slow teacher models to guide the inference of fast student models through endpoint prediction and interpolation. To maintain efficiency, we dynamically allocate computation across timesteps according to guidance needs. Extensive experiments across various distilled video generation models and benchmark datasets demonstrate that our method significantly improves motion fidelity and generation quality while preserving high efficiency. Project page: https://euminds.github.io/motionecho/
UP-SLAM: Adaptively Structured Gaussian SLAM with Uncertainty Prediction in Dynamic Environments
May 28, 2025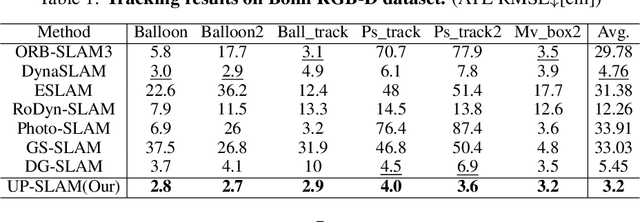
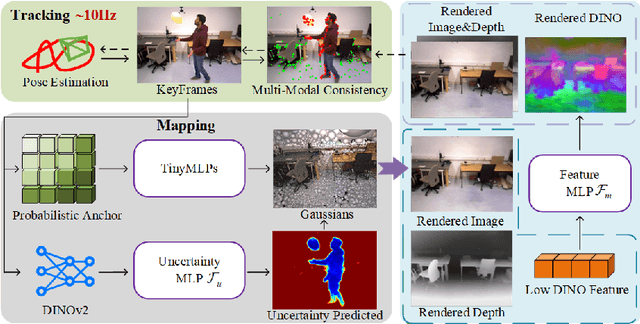

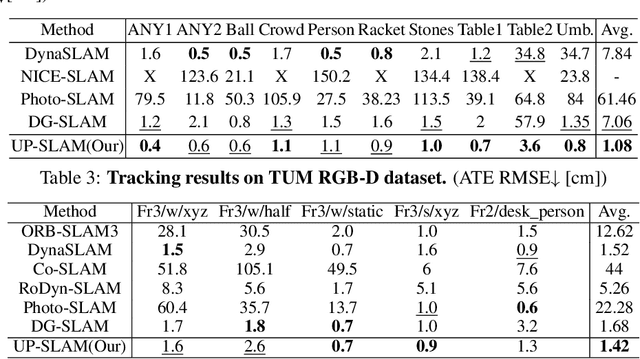
Recent 3D Gaussian Splatting (3DGS) techniques for Visual Simultaneous Localization and Mapping (SLAM) have significantly progressed in tracking and high-fidelity mapping. However, their sequential optimization framework and sensitivity to dynamic objects limit real-time performance and robustness in real-world scenarios. We present UP-SLAM, a real-time RGB-D SLAM system for dynamic environments that decouples tracking and mapping through a parallelized framework. A probabilistic octree is employed to manage Gaussian primitives adaptively, enabling efficient initialization and pruning without hand-crafted thresholds. To robustly filter dynamic regions during tracking, we propose a training-free uncertainty estimator that fuses multi-modal residuals to estimate per-pixel motion uncertainty, achieving open-set dynamic object handling without reliance on semantic labels. Furthermore, a temporal encoder is designed to enhance rendering quality. Concurrently, low-dimensional features are efficiently transformed via a shallow multilayer perceptron to construct DINO features, which are then employed to enrich the Gaussian field and improve the robustness of uncertainty prediction. Extensive experiments on multiple challenging datasets suggest that UP-SLAM outperforms state-of-the-art methods in both localization accuracy (by 59.8%) and rendering quality (by 4.57 dB PSNR), while maintaining real-time performance and producing reusable, artifact-free static maps in dynamic environments.The project: https://aczheng-cai.github.io/up_slam.github.io/
Channel Merging: Preserving Specialization for Merged Experts
Dec 18, 2024Lately, the practice of utilizing task-specific fine-tuning has been implemented to improve the performance of large language models (LLM) in subsequent tasks. Through the integration of diverse LLMs, the overall competency of LLMs is significantly boosted. Nevertheless, traditional ensemble methods are notably memory-intensive, necessitating the simultaneous loading of all specialized models into GPU memory. To address the inefficiency, model merging strategies have emerged, merging all LLMs into one model to reduce the memory footprint during inference. Despite these advances, model merging often leads to parameter conflicts and performance decline as the number of experts increases. Previous methods to mitigate these conflicts include post-pruning and partial merging. However, both approaches have limitations, particularly in terms of performance and storage efficiency when merged experts increase. To address these challenges, we introduce Channel Merging, a novel strategy designed to minimize parameter conflicts while enhancing storage efficiency. This method clusters and merges channel parameters based on their similarity to form several groups offline. By ensuring that only highly similar parameters are merged within each group, it significantly reduces parameter conflicts. During inference, we can instantly look up the expert parameters from the merged groups, preserving specialized knowledge. Our experiments demonstrate that Channel Merging consistently delivers high performance, matching unmerged models in tasks like English and Chinese reasoning, mathematical reasoning, and code generation. Moreover, it obtains results comparable to model ensemble with just 53% parameters when used with a task-specific router.
GSORB-SLAM: Gaussian Splatting SLAM benefits from ORB features and Transmittance information
Oct 15, 2024The emergence of 3D Gaussian Splatting (3DGS) has recently sparked a renewed wave of dense visual SLAM research. However, current methods face challenges such as sensitivity to artifacts and noise, sub-optimal selection of training viewpoints, and a lack of light global optimization. In this paper, we propose a dense SLAM system that tightly couples 3DGS with ORB features. We design a joint optimization approach for robust tracking and effectively reducing the impact of noise and artifacts. This involves combining novel geometric observations, derived from accumulated transmittance, with ORB features extracted from pixel data. Furthermore, to improve mapping quality, we propose an adaptive Gaussian expansion and regularization method that enables Gaussian primitives to represent the scene compactly. This is coupled with a viewpoint selection strategy based on the hybrid graph to mitigate over-fitting effects and enhance convergence quality. Finally, our approach achieves compact and high-quality scene representations and accurate localization. GSORB-SLAM has been evaluated on different datasets, demonstrating outstanding performance. The code will be available.
Boosting Box-supervised Instance Segmentation with Pseudo Depth
Mar 02, 2024The realm of Weakly Supervised Instance Segmentation (WSIS) under box supervision has garnered substantial attention, showcasing remarkable advancements in recent years. However, the limitations of box supervision become apparent in its inability to furnish effective information for distinguishing foreground from background within the specified target box. This research addresses this challenge by introducing pseudo-depth maps into the training process of the instance segmentation network, thereby boosting its performance by capturing depth differences between instances. These pseudo-depth maps are generated using a readily available depth predictor and are not necessary during the inference stage. To enable the network to discern depth features when predicting masks, we integrate a depth prediction layer into the mask prediction head. This innovative approach empowers the network to simultaneously predict masks and depth, enhancing its ability to capture nuanced depth-related information during the instance segmentation process. We further utilize the mask generated in the training process as supervision to distinguish the foreground from the background. When selecting the best mask for each box through the Hungarian algorithm, we use depth consistency as one calculation cost item. The proposed method achieves significant improvements on Cityscapes and COCO dataset.
Improving Neural Indoor Surface Reconstruction with Mask-Guided Adaptive Consistency Constraints
Sep 18, 2023



3D scene reconstruction from 2D images has been a long-standing task. Instead of estimating per-frame depth maps and fusing them in 3D, recent research leverages the neural implicit surface as a unified representation for 3D reconstruction. Equipped with data-driven pre-trained geometric cues, these methods have demonstrated promising performance. However, inaccurate prior estimation, which is usually inevitable, can lead to suboptimal reconstruction quality, particularly in some geometrically complex regions. In this paper, we propose a two-stage training process, decouple view-dependent and view-independent colors, and leverage two novel consistency constraints to enhance detail reconstruction performance without requiring extra priors. Additionally, we introduce an essential mask scheme to adaptively influence the selection of supervision constraints, thereby improving performance in a self-supervised paradigm. Experiments on synthetic and real-world datasets show the capability of reducing the interference from prior estimation errors and achieving high-quality scene reconstruction with rich geometric details.
ShiftNAS: Improving One-shot NAS via Probability Shift
Jul 17, 2023One-shot Neural architecture search (One-shot NAS) has been proposed as a time-efficient approach to obtain optimal subnet architectures and weights under different complexity cases by training only once. However, the subnet performance obtained by weight sharing is often inferior to the performance achieved by retraining. In this paper, we investigate the performance gap and attribute it to the use of uniform sampling, which is a common approach in supernet training. Uniform sampling concentrates training resources on subnets with intermediate computational resources, which are sampled with high probability. However, subnets with different complexity regions require different optimal training strategies for optimal performance. To address the problem of uniform sampling, we propose ShiftNAS, a method that can adjust the sampling probability based on the complexity of subnets. We achieve this by evaluating the performance variation of subnets with different complexity and designing an architecture generator that can accurately and efficiently provide subnets with the desired complexity. Both the sampling probability and the architecture generator can be trained end-to-end in a gradient-based manner. With ShiftNAS, we can directly obtain the optimal model architecture and parameters for a given computational complexity. We evaluate our approach on multiple visual network models, including convolutional neural networks (CNNs) and vision transformers (ViTs), and demonstrate that ShiftNAS is model-agnostic. Experimental results on ImageNet show that ShiftNAS can improve the performance of one-shot NAS without additional consumption. Source codes are available at https://github.com/bestfleer/ShiftNAS.
Retrieval-Enhanced Visual Prompt Learning for Few-shot Classification
Jun 04, 2023Prompt learning has become a popular approach for adapting large vision-language models, such as CLIP, to downstream tasks. Typically, prompt learning relies on a fixed prompt token or an input-conditional token to fit a small amount of data under full supervision. While this paradigm can generalize to a certain range of unseen classes, it may struggle when domain gap increases, such as in fine-grained classification and satellite image segmentation. To address this limitation, we propose Retrieval-enhanced Prompt learning (RePrompt), which introduces retrieval mechanisms to cache the knowledge representations from downstream tasks. we first construct a retrieval database from training examples, or from external examples when available. We then integrate this retrieval-enhanced mechanism into various stages of a simple prompt learning baseline. By referencing similar samples in the training set, the enhanced model is better able to adapt to new tasks with few samples. Our extensive experiments over 15 vision datasets, including 11 downstream tasks with few-shot setting and 4 domain generalization benchmarks, demonstrate that RePrompt achieves considerably improved performance. Our proposed approach provides a promising solution to the challenges faced by prompt learning when domain gap increases. The code and models will be available.
Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
May 31, 2023
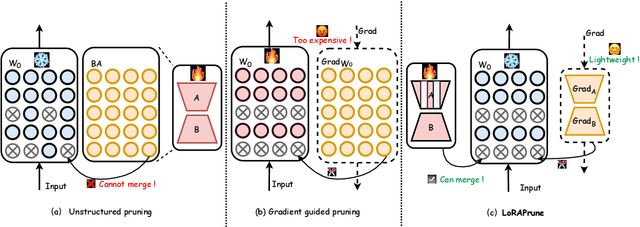
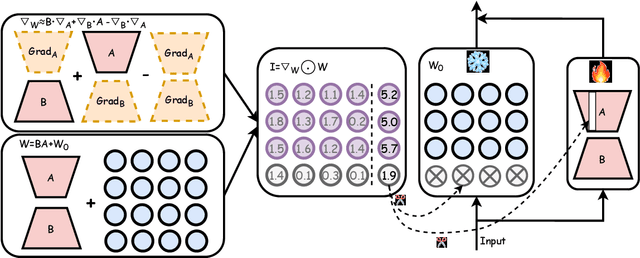
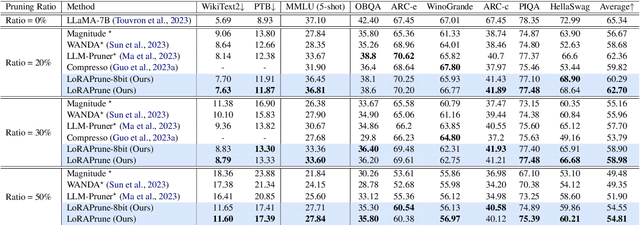
Large pre-trained models (LPMs), such as LLaMA and ViT-G, have shown exceptional performance across various tasks. Although parameter-efficient fine-tuning (PEFT) has emerged to cheaply fine-tune these large models on downstream tasks, their deployment is still hindered by the vast model scale and computational costs. Neural network pruning offers a solution for model compression by removing redundant parameters, but most existing methods rely on computing parameter gradients. However, obtaining the gradients is computationally prohibitive for LPMs, which necessitates the exploration of alternative approaches. To this end, we propose a unified framework for efficient fine-tuning and deployment of LPMs, termed LoRAPrune. We first design a PEFT-aware pruning criterion, which utilizes the values and gradients of Low-Rank Adaption (LoRA), rather than the gradients of pre-trained parameters for importance estimation. We then propose an iterative pruning procedure to remove redundant parameters while maximizing the advantages of PEFT. Thus, our LoRAPrune delivers an accurate, compact model for efficient inference in a highly cost-effective manner. Experimental results on various tasks demonstrate that our method achieves state-of-the-art results. For instance, in the VTAB-1k benchmark, LoRAPrune utilizes only 0.76% of the trainable parameters and outperforms magnitude and movement pruning methods by a significant margin, achieving a mean Top-1 accuracy that is 5.7% and 4.3% higher, respectively. Moreover, our approach achieves comparable performance to PEFT methods, highlighting its efficacy in delivering high-quality results while benefiting from the advantages of pruning.