 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruning Meets Low-Rank Parameter-Efficient Fine-Tuning
Paper and Code
May 31, 2023
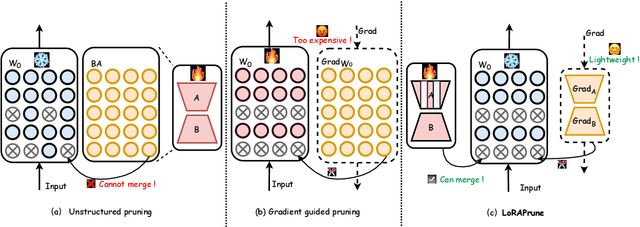
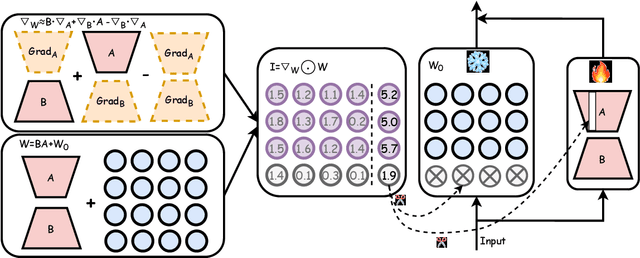
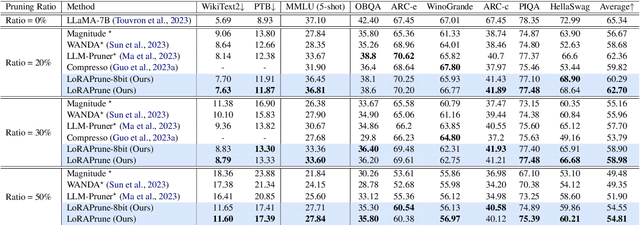
Large pre-trained models (LPMs), such as LLaMA and ViT-G, have shown exceptional performance across various tasks. Although parameter-efficient fine-tuning (PEFT) has emerged to cheaply fine-tune these large models on downstream tasks, their deployment is still hindered by the vast model scale and computational costs. Neural network pruning offers a solution for model compression by removing redundant parameters, but most existing methods rely on computing parameter gradients. However, obtaining the gradients is computationally prohibitive for LPMs, which necessitates the exploration of alternative approaches. To this end, we propose a unified framework for efficient fine-tuning and deployment of LPMs, termed LoRAPrune. We first design a PEFT-aware pruning criterion, which utilizes the values and gradients of Low-Rank Adaption (LoRA), rather than the gradients of pre-trained parameters for importance estimation. We then propose an iterative pruning procedure to remove redundant parameters while maximizing the advantages of PEFT. Thus, our LoRAPrune delivers an accurate, compact model for efficient inference in a highly cost-effective manner. Experimental results on various tasks demonstrate that our method achieves state-of-the-art results. For instance, in the VTAB-1k benchmark, LoRAPrune utilizes only 0.76% of the trainable parameters and outperforms magnitude and movement pruning methods by a significant margin, achieving a mean Top-1 accuracy that is 5.7% and 4.3% higher, respectively. Moreover, our approach achieves comparable performance to PEFT methods, highlighting its efficacy in delivering high-quality results while benefiting from the advantages of pruning.