 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
Aug 11, 2025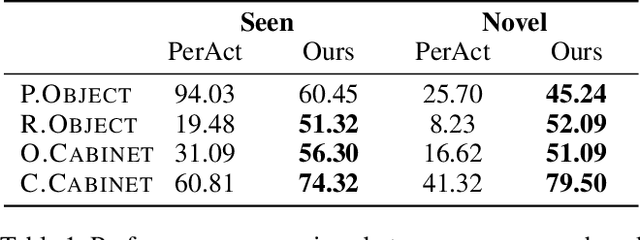
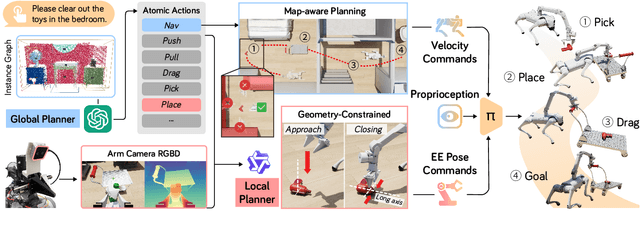


Language-guided long-horizon mobile manipulation has long been a grand challenge in embodied semantic reasoning, generalizable manipulation, and adaptive locomotion. Three fundamental limitations hinder progress: First, although large language models have improved spatial reasoning and task planning through semantic priors, existing implementations remain confined to tabletop scenarios, failing to address the constrained perception and limited actuation ranges of mobile platforms. Second, current manipulation strategies exhibit insufficient generalization when confronted with the diverse object configurations encountered in open-world environments. Third, while crucial for practical deployment, the dual requirement of maintaining high platform maneuverability alongside precise end-effector control in unstructured settings remains understudied. In this work, we present ODYSSEY, a unified mobile manipulation framework for agile quadruped robots equipped with manipulators, which seamlessly integrates high-level task planning with low-level whole-body control. To address the challenge of egocentric perception in language-conditioned tasks, we introduce a hierarchical planner powered by a vision-language model, enabling long-horizon instruction decomposition and precise action execution. At the control level, our novel whole-body policy achieves robust coordination across challenging terrains. We further present the first benchmark for long-horizon mobile manipulation, evaluating diverse indoor and outdoor scenarios. Through successful sim-to-real transfer, we demonstrate the system's generalization and robustness in real-world deployments, underscoring the practicality of legged manipulators in unstructured environments. Our work advances the feasibility of generalized robotic assistants capable of complex, dynamic tasks. Our project page: https://kaijwang.github.io/odyssey.github.io/
Improving Neural Indoor Surface Reconstruction with Mask-Guided Adaptive Consistency Constraints
Sep 18, 2023



3D scene reconstruction from 2D images has been a long-standing task. Instead of estimating per-frame depth maps and fusing them in 3D, recent research leverages the neural implicit surface as a unified representation for 3D reconstruction. Equipped with data-driven pre-trained geometric cues, these methods have demonstrated promising performance. However, inaccurate prior estimation, which is usually inevitable, can lead to suboptimal reconstruction quality, particularly in some geometrically complex regions. In this paper, we propose a two-stage training process, decouple view-dependent and view-independent colors, and leverage two novel consistency constraints to enhance detail reconstruction performance without requiring extra priors. Additionally, we introduce an essential mask scheme to adaptively influence the selection of supervision constraints, thereby improving performance in a self-supervised paradigm. Experiments on synthetic and real-world datasets show the capability of reducing the interference from prior estimation errors and achieving high-quality scene reconstruction with rich geometric details.