 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Spatial Intelligence from a Generative Perspective
Apr 22, 2026Spatial intelligence is essential for multimodal large language models, yet current benchmarks largely assess it only from an understanding perspective. We ask whether modern generative or unified multimodal models also possess generative spatial intelligence (GSI), the ability to respect and manipulate 3D spatial constraints during image generation, and whether such capability can be measured or improved. We introduce GSI-Bench, the first benchmark designed to quantify GSI through spatially grounded image editing. It consists of two complementary components: GSI-Real, a high-quality real-world dataset built via a 3D-prior-guided generation and filtering pipeline, and GSI-Syn, a large-scale synthetic benchmark with controllable spatial operations and fully automated labeling. Together with a unified evaluation protocol, GSI-Bench enables scalable, model-agnostic assessment of spatial compliance and editing fidelity. Experiments show that fine-tuning unified multimodal models on GSI-Syn yields substantial gains on both synthetic and real tasks and, strikingly, also improves downstream spatial understanding. This provides the first clear evidence that generative training can tangibly strengthen spatial reasoning, establishing a new pathway for advancing spatial intelligence in multimodal models.
RealHD: A High-Quality Dataset for Robust Detection of State-of-the-Art AI-Generated Images
Feb 11, 2026The rapid advancement of generative AI has raised concerns about the authenticity of digital images, as highly realistic fake images can now be generated at low cost, potentially increasing societal risks. In response, several datasets have been established to train detection models aimed at distinguishing AI-generated images from real ones. However, existing datasets suffer from limited generalization, low image quality, overly simple prompts, and insufficient image diversity. To address these limitations, we propose a high-quality, large-scale dataset comprising over 730,000 images across multiple categories, including both real and AI-generated images. The generated images are synthesized via state-of-the-art methods, including text-to-image generation (guided by over 10,000 carefully designed prompts), image inpainting, image refinement, and face swapping. Each generated image is annotated with its generation method and category. Inpainting images further include binary masks to indicate inpainted regions, providing rich metadata for analysis. Compared to existing datasets, detection models trained on our dataset demonstrate superior generalization capabilities. Our dataset not only serves as a strong benchmark for evaluating detection methods but also contributes to advancing the robustness of AI-generated image detection techniques. Building upon this, we propose a lightweight detection method based on image noise entropy, which transforms the original image into an entropy tensor of Non-Local Means (NLM) noise before classification. Extensive experiments demonstrate that models trained on our dataset achieve strong generalization, and our method delivers competitive performance, establishing a solid baseline for future research. The dataset and source code are publicly available at https://real-hd.github.io.
* Published in the Proceedings of the 33rd ACM International Conference on Multimedia (ACM MM 2025)
Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time Distillation
Jun 24, 2025Distilled video generation models offer fast and efficient synthesis but struggle with motion customization when guided by reference videos, especially under training-free settings. Existing training-free methods, originally designed for standard diffusion models, fail to generalize due to the accelerated generative process and large denoising steps in distilled models. To address this, we propose MotionEcho, a novel training-free test-time distillation framework that enables motion customization by leveraging diffusion teacher forcing. Our approach uses high-quality, slow teacher models to guide the inference of fast student models through endpoint prediction and interpolation. To maintain efficiency, we dynamically allocate computation across timesteps according to guidance needs. Extensive experiments across various distilled video generation models and benchmark datasets demonstrate that our method significantly improves motion fidelity and generation quality while preserving high efficiency. Project page: https://euminds.github.io/motionecho/
GSORB-SLAM: Gaussian Splatting SLAM benefits from ORB features and Transmittance information
Oct 15, 2024The emergence of 3D Gaussian Splatting (3DGS) has recently sparked a renewed wave of dense visual SLAM research. However, current methods face challenges such as sensitivity to artifacts and noise, sub-optimal selection of training viewpoints, and a lack of light global optimization. In this paper, we propose a dense SLAM system that tightly couples 3DGS with ORB features. We design a joint optimization approach for robust tracking and effectively reducing the impact of noise and artifacts. This involves combining novel geometric observations, derived from accumulated transmittance, with ORB features extracted from pixel data. Furthermore, to improve mapping quality, we propose an adaptive Gaussian expansion and regularization method that enables Gaussian primitives to represent the scene compactly. This is coupled with a viewpoint selection strategy based on the hybrid graph to mitigate over-fitting effects and enhance convergence quality. Finally, our approach achieves compact and high-quality scene representations and accurate localization. GSORB-SLAM has been evaluated on different datasets, demonstrating outstanding performance. The code will be available.
Improving Neural Indoor Surface Reconstruction with Mask-Guided Adaptive Consistency Constraints
Sep 18, 2023



3D scene reconstruction from 2D images has been a long-standing task. Instead of estimating per-frame depth maps and fusing them in 3D, recent research leverages the neural implicit surface as a unified representation for 3D reconstruction. Equipped with data-driven pre-trained geometric cues, these methods have demonstrated promising performance. However, inaccurate prior estimation, which is usually inevitable, can lead to suboptimal reconstruction quality, particularly in some geometrically complex regions. In this paper, we propose a two-stage training process, decouple view-dependent and view-independent colors, and leverage two novel consistency constraints to enhance detail reconstruction performance without requiring extra priors. Additionally, we introduce an essential mask scheme to adaptively influence the selection of supervision constraints, thereby improving performance in a self-supervised paradigm. Experiments on synthetic and real-world datasets show the capability of reducing the interference from prior estimation errors and achieving high-quality scene reconstruction with rich geometric details.
Retrieval-Enhanced Visual Prompt Learning for Few-shot Classification
Jun 04, 2023Prompt learning has become a popular approach for adapting large vision-language models, such as CLIP, to downstream tasks. Typically, prompt learning relies on a fixed prompt token or an input-conditional token to fit a small amount of data under full supervision. While this paradigm can generalize to a certain range of unseen classes, it may struggle when domain gap increases, such as in fine-grained classification and satellite image segmentation. To address this limitation, we propose Retrieval-enhanced Prompt learning (RePrompt), which introduces retrieval mechanisms to cache the knowledge representations from downstream tasks. we first construct a retrieval database from training examples, or from external examples when available. We then integrate this retrieval-enhanced mechanism into various stages of a simple prompt learning baseline. By referencing similar samples in the training set, the enhanced model is better able to adapt to new tasks with few samples. Our extensive experiments over 15 vision datasets, including 11 downstream tasks with few-shot setting and 4 domain generalization benchmarks, demonstrate that RePrompt achieves considerably improved performance. Our proposed approach provides a promising solution to the challenges faced by prompt learning when domain gap increases. The code and models will be available.
De-IReps: Searching for improved Re-parameterizing Architecture based on Differentiable Evolution Strategy
Apr 13, 2022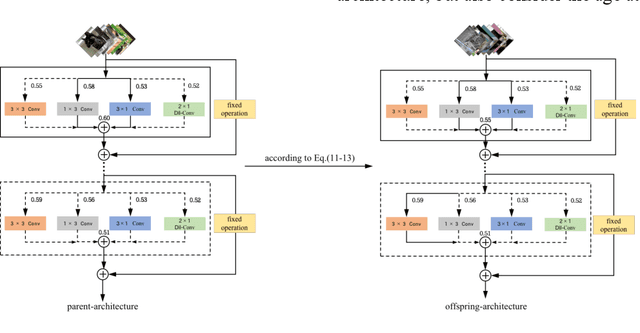
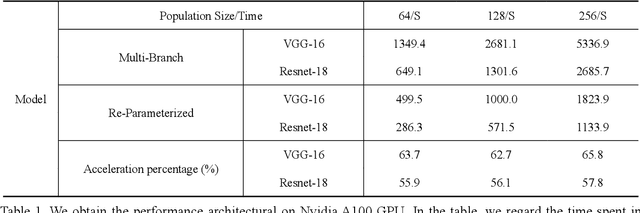
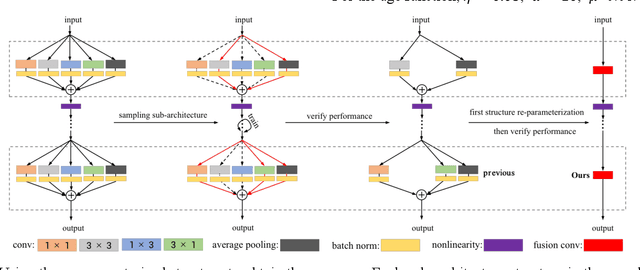
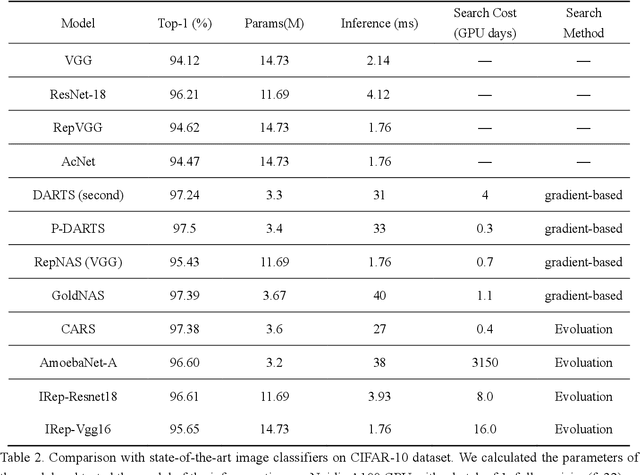
In recent years, neural architecture search (NAS) has shown great competitiveness in many fields and re-parameterization techniques have started to appear in the field of architectural search. However, most edge devices do not adapt well to networks, especially the multi-branch structure, which is searched by NAS. Therefore, in this work we design a search space that covers almost all re-parameterization operations. In this search space, multiple-path networks can be unconditionally re-parameterized into single-path networks. Thus, enhancing the usefulness of traditional nas. Meanwhile we summarize the characteristics of the re-parameterization search space and propose a differentiable evolutionary strategy (DES) to explore the re-parameterization search space. We visualize the features of the searched architecture and give our explanation for the appearance of this architecture. In this work, we can achieve efficient search and find better network structures. Respectively, we completed the architecture search on CIFAR-10 with the test accuracy of 96.64% (IrepResNet-18) and 95.65% (IrepVGG-16) and on ImageNet with the test accuracy of 77.92% (Irep-ResNet-50).