 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODYSSEY: Open-World Quadrupeds Exploration and Manipulation for Long-Horizon Tasks
Aug 11, 2025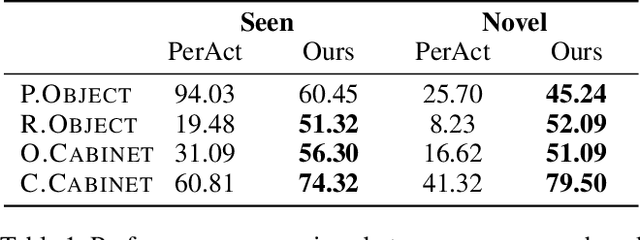
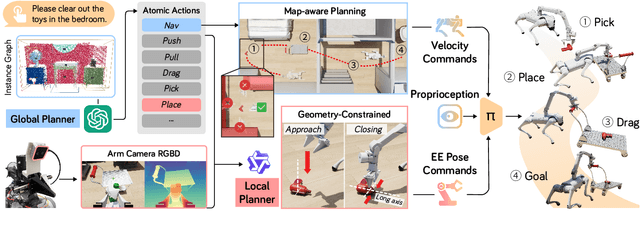


Language-guided long-horizon mobile manipulation has long been a grand challenge in embodied semantic reasoning, generalizable manipulation, and adaptive locomotion. Three fundamental limitations hinder progress: First, although large language models have improved spatial reasoning and task planning through semantic priors, existing implementations remain confined to tabletop scenarios, failing to address the constrained perception and limited actuation ranges of mobile platforms. Second, current manipulation strategies exhibit insufficient generalization when confronted with the diverse object configurations encountered in open-world environments. Third, while crucial for practical deployment, the dual requirement of maintaining high platform maneuverability alongside precise end-effector control in unstructured settings remains understudied. In this work, we present ODYSSEY, a unified mobile manipulation framework for agile quadruped robots equipped with manipulators, which seamlessly integrates high-level task planning with low-level whole-body control. To address the challenge of egocentric perception in language-conditioned tasks, we introduce a hierarchical planner powered by a vision-language model, enabling long-horizon instruction decomposition and precise action execution. At the control level, our novel whole-body policy achieves robust coordination across challenging terrains. We further present the first benchmark for long-horizon mobile manipulation, evaluating diverse indoor and outdoor scenarios. Through successful sim-to-real transfer, we demonstrate the system's generalization and robustness in real-world deployments, underscoring the practicality of legged manipulators in unstructured environments. Our work advances the feasibility of generalized robotic assistants capable of complex, dynamic tasks. Our project page: https://kaijwang.github.io/odyssey.github.io/
UP-SLAM: Adaptively Structured Gaussian SLAM with Uncertainty Prediction in Dynamic Environments
May 28, 2025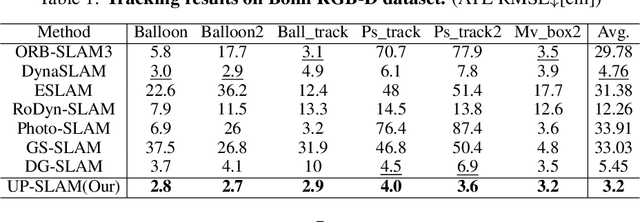
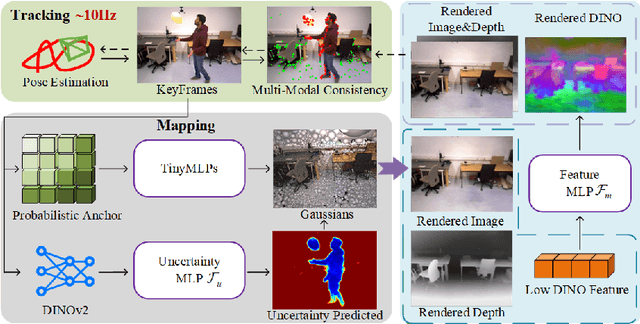

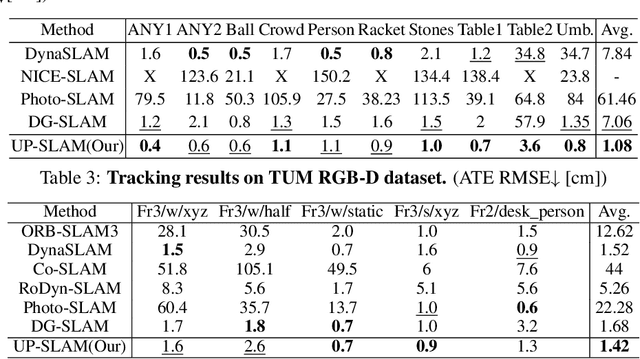
Recent 3D Gaussian Splatting (3DGS) techniques for Visual Simultaneous Localization and Mapping (SLAM) have significantly progressed in tracking and high-fidelity mapping. However, their sequential optimization framework and sensitivity to dynamic objects limit real-time performance and robustness in real-world scenarios. We present UP-SLAM, a real-time RGB-D SLAM system for dynamic environments that decouples tracking and mapping through a parallelized framework. A probabilistic octree is employed to manage Gaussian primitives adaptively, enabling efficient initialization and pruning without hand-crafted thresholds. To robustly filter dynamic regions during tracking, we propose a training-free uncertainty estimator that fuses multi-modal residuals to estimate per-pixel motion uncertainty, achieving open-set dynamic object handling without reliance on semantic labels. Furthermore, a temporal encoder is designed to enhance rendering quality. Concurrently, low-dimensional features are efficiently transformed via a shallow multilayer perceptron to construct DINO features, which are then employed to enrich the Gaussian field and improve the robustness of uncertainty prediction. Extensive experiments on multiple challenging datasets suggest that UP-SLAM outperforms state-of-the-art methods in both localization accuracy (by 59.8%) and rendering quality (by 4.57 dB PSNR), while maintaining real-time performance and producing reusable, artifact-free static maps in dynamic environments.The project: https://aczheng-cai.github.io/up_slam.github.io/
GSORB-SLAM: Gaussian Splatting SLAM benefits from ORB features and Transmittance information
Oct 15, 2024The emergence of 3D Gaussian Splatting (3DGS) has recently sparked a renewed wave of dense visual SLAM research. However, current methods face challenges such as sensitivity to artifacts and noise, sub-optimal selection of training viewpoints, and a lack of light global optimization. In this paper, we propose a dense SLAM system that tightly couples 3DGS with ORB features. We design a joint optimization approach for robust tracking and effectively reducing the impact of noise and artifacts. This involves combining novel geometric observations, derived from accumulated transmittance, with ORB features extracted from pixel data. Furthermore, to improve mapping quality, we propose an adaptive Gaussian expansion and regularization method that enables Gaussian primitives to represent the scene compactly. This is coupled with a viewpoint selection strategy based on the hybrid graph to mitigate over-fitting effects and enhance convergence quality. Finally, our approach achieves compact and high-quality scene representations and accurate localization. GSORB-SLAM has been evaluated on different datasets, demonstrating outstanding performance. The code will be available.
Multi-subgoal Robot Navigation in Crowds with History Information and Interactions
May 04, 2022



Robot navigation in dynamic environments shared with humans is an important but challenging task, which suffers from performance deterioration as the crowd grows. In this paper, multi-subgoal robot navigation approach based on deep reinforcement learning is proposed, which can reason about more comprehensive relationships among all agents (robot and humans). Specifically, the next position point is planned for the robot by introducing history information and interactions in our work. Firstly, based on subgraph network, the history information of all agents is aggregated before encoding interactions through a graph neural network, so as to improve the ability of the robot to anticipate the future scenarios implicitly. Further consideration, in order to reduce the probability of unreliable next position points, the selection module is designed after policy network in the reinforcement learning framework. In addition, the next position point generated from the selection module satisfied the task requirements better than that obtained directly from the policy network. The experiments demonstrate that our approach outperforms state-of-the-art approaches in terms of both success rate and collision rate, especially in crowded human environments.