 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks on LLM-based Recommender Systems
Aug 26, 2025Large language models (LLMs) based Recommender Systems (RecSys) can flexibly adapt recommendation systems to different domains. It utilizes in-context learning (ICL), i.e., the prompts, to customize the recommendation functions, which include sensitive historical user-specific item interactions, e.g., implicit feedback like clicked items or explicit product reviews. Such private information may be exposed to novel privacy attack. However, no study has been done on this important issue. We design four membership inference attacks (MIAs), aiming to reveal whether victims' historical interactions have been used by system prompts. They are \emph{direct inquiry, hallucination, similarity, and poisoning attacks}, each of which utilizes the unique features of LLMs or RecSys. We have carefully evaluated them on three LLMs that have been used to develop ICL-LLM RecSys and two well-known RecSys benchmark datasets. The results confirm that the MIA threat on LLM RecSys is realistic: direct inquiry and poisoning attacks showing significantly high attack advantages. We have also analyzed the factors affecting these attacks, such as the number of shots in system prompts and the position of the victim in the shots.
Auditing Approximate Machine Unlearning for Differentially Private Models
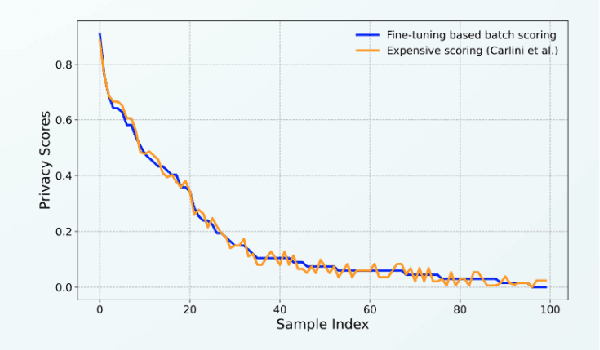
Aug 26, 2025Approximate machine unlearning aims to remove the effect of specific data from trained models to ensure individuals' privacy. Existing methods focus on the removed records and assume the retained ones are unaffected. However, recent studies on the \emph{privacy onion effect} indicate this assumption might be incorrect. Especially when the model is differentially private, no study has explored whether the retained ones still meet the differential privacy (DP) criterion under existing machine unlearning methods. This paper takes a holistic approach to auditing both unlearned and retained samples' privacy risks after applying approximate unlearning algorithms. We propose the privacy criteria for unlearned and retained samples, respectively, based on the perspectives of DP and membership inference attacks (MIAs). To make the auditing process more practical, we also develop an efficient MIA, A-LiRA, utilizing data augmentation to reduce the cost of shadow model training. Our experimental findings indicate that existing approximate machine unlearning algorithms may inadvertently compromise the privacy of retained samples for differentially private models, and we need differentially private unlearning algorithms. For reproducibility, we have pubished our code: https://anonymous.4open.science/r/Auditing-machine-unlearning-CB10/README.md
UP-SLAM: Adaptively Structured Gaussian SLAM with Uncertainty Prediction in Dynamic Environments
May 28, 2025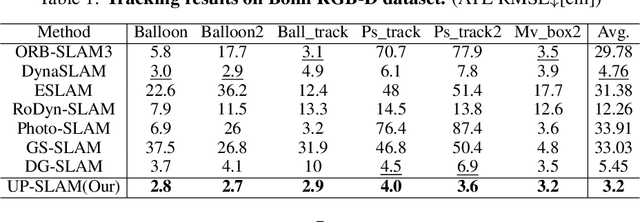
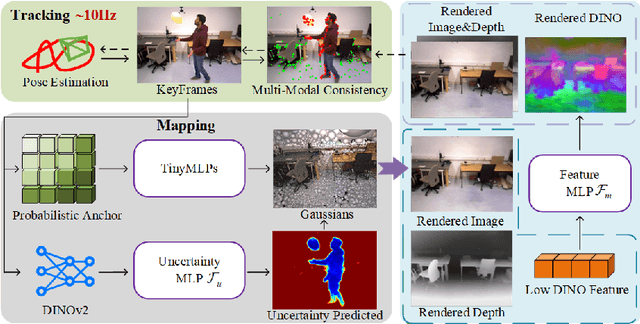

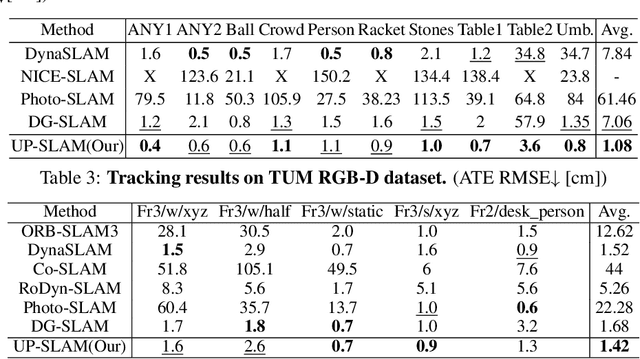
Recent 3D Gaussian Splatting (3DGS) techniques for Visual Simultaneous Localization and Mapping (SLAM) have significantly progressed in tracking and high-fidelity mapping. However, their sequential optimization framework and sensitivity to dynamic objects limit real-time performance and robustness in real-world scenarios. We present UP-SLAM, a real-time RGB-D SLAM system for dynamic environments that decouples tracking and mapping through a parallelized framework. A probabilistic octree is employed to manage Gaussian primitives adaptively, enabling efficient initialization and pruning without hand-crafted thresholds. To robustly filter dynamic regions during tracking, we propose a training-free uncertainty estimator that fuses multi-modal residuals to estimate per-pixel motion uncertainty, achieving open-set dynamic object handling without reliance on semantic labels. Furthermore, a temporal encoder is designed to enhance rendering quality. Concurrently, low-dimensional features are efficiently transformed via a shallow multilayer perceptron to construct DINO features, which are then employed to enrich the Gaussian field and improve the robustness of uncertainty prediction. Extensive experiments on multiple challenging datasets suggest that UP-SLAM outperforms state-of-the-art methods in both localization accuracy (by 59.8%) and rendering quality (by 4.57 dB PSNR), while maintaining real-time performance and producing reusable, artifact-free static maps in dynamic environments.The project: https://aczheng-cai.github.io/up_slam.github.io/
FT-PrivacyScore: Personalized Privacy Scoring Service for Machine Learning Participation
Oct 30, 2024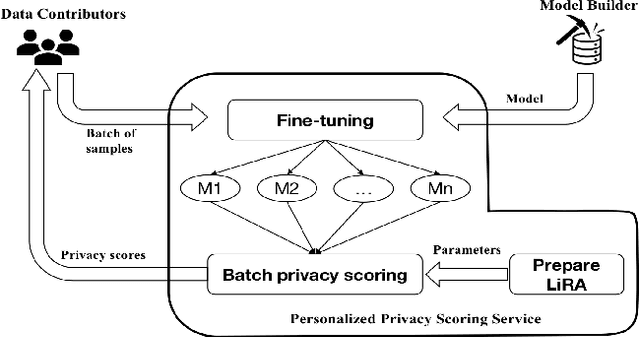
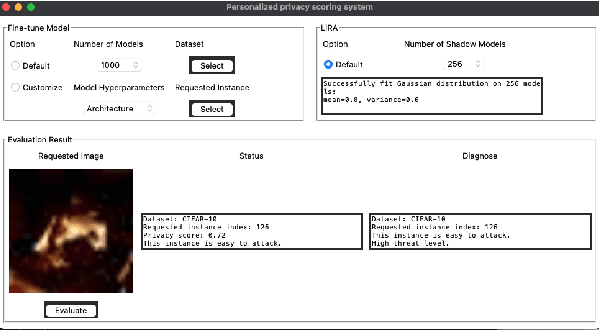
Training data privacy has been a top concern in AI modeling. While methods like differentiated private learning allow data contributors to quantify acceptable privacy loss, model utility is often significantly damaged. In practice, controlled data access remains a mainstream method for protecting data privacy in many industrial and research environments. In controlled data access, authorized model builders work in a restricted environment to access sensitive data, which can fully preserve data utility with reduced risk of data leak. However, unlike differential privacy, there is no quantitative measure for individual data contributors to tell their privacy risk before participating in a machine learning task. We developed the demo prototype FT-PrivacyScore to show that it's possible to efficiently and quantitatively estimate the privacy risk of participating in a model fine-tuning task. The demo source code will be available at \url{https://github.com/RhincodonE/demo_privacy_scoring}.
Double A3C: Deep Reinforcement Learning on OpenAI Gym Games
Mar 04, 2023

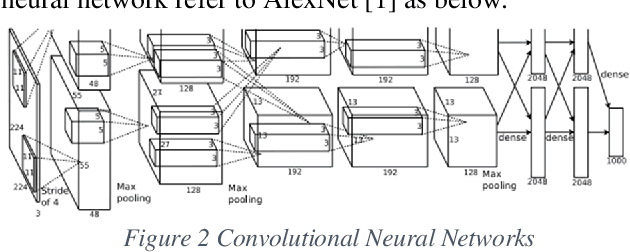

Reinforcement Learning (RL) is an area of machine learning figuring out how agents take actions in an unknown environment to maximize its rewards. Unlike classical Markov Decision Process (MDP) in which agent has full knowledge of its state, rewards, and transitional probability, reinforcement learning utilizes exploration and exploitation for the model uncertainty. Under the condition that the model usually has a large state space, a neural network (NN) can be used to correlate its input state to its output actions to maximize the agent's rewards. However, building and training an efficient neural network is challenging. Inspired by Double Q-learning and Asynchronous Advantage Actor-Critic (A3C) algorithm, we will propose and implement an improved version of Double A3C algorithm which utilizing the strength of both algorithms to play OpenAI Gym Atari 2600 games to beat its benchmarks for our project.