 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks on LLM-based Recommender Systems
Aug 26, 2025Large language models (LLMs) based Recommender Systems (RecSys) can flexibly adapt recommendation systems to different domains. It utilizes in-context learning (ICL), i.e., the prompts, to customize the recommendation functions, which include sensitive historical user-specific item interactions, e.g., implicit feedback like clicked items or explicit product reviews. Such private information may be exposed to novel privacy attack. However, no study has been done on this important issue. We design four membership inference attacks (MIAs), aiming to reveal whether victims' historical interactions have been used by system prompts. They are \emph{direct inquiry, hallucination, similarity, and poisoning attacks}, each of which utilizes the unique features of LLMs or RecSys. We have carefully evaluated them on three LLMs that have been used to develop ICL-LLM RecSys and two well-known RecSys benchmark datasets. The results confirm that the MIA threat on LLM RecSys is realistic: direct inquiry and poisoning attacks showing significantly high attack advantages. We have also analyzed the factors affecting these attacks, such as the number of shots in system prompts and the position of the victim in the shots.
Auditing Approximate Machine Unlearning for Differentially Private Models
Aug 26, 2025Approximate machine unlearning aims to remove the effect of specific data from trained models to ensure individuals' privacy. Existing methods focus on the removed records and assume the retained ones are unaffected. However, recent studies on the \emph{privacy onion effect} indicate this assumption might be incorrect. Especially when the model is differentially private, no study has explored whether the retained ones still meet the differential privacy (DP) criterion under existing machine unlearning methods. This paper takes a holistic approach to auditing both unlearned and retained samples' privacy risks after applying approximate unlearning algorithms. We propose the privacy criteria for unlearned and retained samples, respectively, based on the perspectives of DP and membership inference attacks (MIAs). To make the auditing process more practical, we also develop an efficient MIA, A-LiRA, utilizing data augmentation to reduce the cost of shadow model training. Our experimental findings indicate that existing approximate machine unlearning algorithms may inadvertently compromise the privacy of retained samples for differentially private models, and we need differentially private unlearning algorithms. For reproducibility, we have pubished our code: https://anonymous.4open.science/r/Auditing-machine-unlearning-CB10/README.md
FT-PrivacyScore: Personalized Privacy Scoring Service for Machine Learning Participation
Oct 30, 2024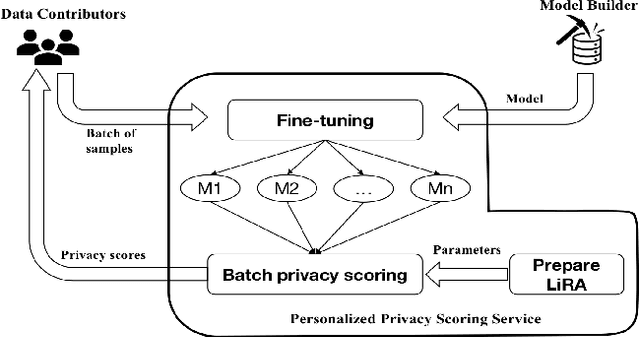
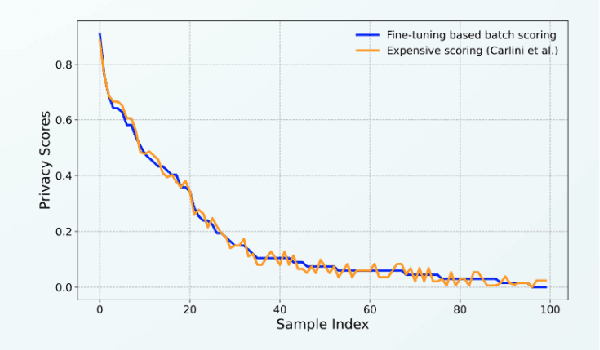
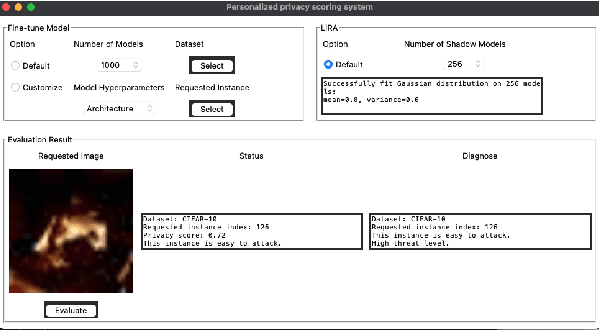
Training data privacy has been a top concern in AI modeling. While methods like differentiated private learning allow data contributors to quantify acceptable privacy loss, model utility is often significantly damaged. In practice, controlled data access remains a mainstream method for protecting data privacy in many industrial and research environments. In controlled data access, authorized model builders work in a restricted environment to access sensitive data, which can fully preserve data utility with reduced risk of data leak. However, unlike differential privacy, there is no quantitative measure for individual data contributors to tell their privacy risk before participating in a machine learning task. We developed the demo prototype FT-PrivacyScore to show that it's possible to efficiently and quantitatively estimate the privacy risk of participating in a model fine-tuning task. The demo source code will be available at \url{https://github.com/RhincodonE/demo_privacy_scoring}.
Calibrating Practical Privacy Risks for Differentially Private Machine Learning
Oct 30, 2024Differential privacy quantifies privacy through the privacy budget $\epsilon$, yet its practical interpretation is complicated by variations across models and datasets. Recent research on differentially private machine learning and membership inference has highlighted that with the same theoretical $\epsilon$ setting, the likelihood-ratio-based membership inference (LiRA) attacking success rate (ASR) may vary according to specific datasets and models, which might be a better indicator for evaluating real-world privacy risks. Inspired by this practical privacy measure, we study the approaches that can lower the attacking success rate to allow for more flexible privacy budget settings in model training. We find that by selectively suppressing privacy-sensitive features, we can achieve lower ASR values without compromising application-specific data utility. We use the SHAP and LIME model explainer to evaluate feature sensitivities and develop feature-masking strategies. Our findings demonstrate that the LiRA $ASR^M$ on model $M$ can properly indicate the inherent privacy risk of a dataset for modeling, and it's possible to modify datasets to enable the use of larger theoretical $\epsilon$ settings to achieve equivalent practical privacy protection. We have conducted extensive experiments to show the inherent link between ASR and the dataset's privacy risk. By carefully selecting features to mask, we can preserve more data utility with equivalent practical privacy protection and relaxed $\epsilon$ settings. The implementation details are shared online at the provided GitHub URL \url{https://anonymous.4open.science/r/On-sensitive-features-and-empirical-epsilon-lower-bounds-BF67/}.
Adaptive Domain Inference Attack
Dec 22, 2023As deep neural networks are increasingly deployed in sensitive application domains, such as healthcare and security, it's necessary to understand what kind of sensitive information can be inferred from these models. Existing model-targeted attacks all assume the attacker has known the application domain or training data distribution, which plays an essential role in successful attacks. Can removing the domain information from model APIs protect models from these attacks? This paper studies this critical problem. Unfortunately, even with minimal knowledge, i.e., accessing the model as an unnamed function without leaking the meaning of input and output, the proposed adaptive domain inference attack (ADI) can still successfully estimate relevant subsets of training data. We show that the extracted relevant data can significantly improve, for instance, the performance of model-inversion attacks. Specifically, the ADI method utilizes a concept hierarchy built on top of a large collection of available public and private datasets and a novel algorithm to adaptively tune the likelihood of leaf concepts showing up in the unseen training data. The ADI attack not only extracts partial training data at the concept level, but also converges fast and requires much fewer target-model accesses than another domain inference attack, GDI.
A Comparative Study of Image Disguising Methods for Confidential Outsourced Learning
Dec 31, 2022



Large training data and expensive model tweaking are standard features of deep learning for images. As a result, data owners often utilize cloud resources to develop large-scale complex models, which raises privacy concerns. Existing solutions are either too expensive to be practical or do not sufficiently protect the confidentiality of data and models. In this paper, we study and compare novel \emph{image disguising} mechanisms, DisguisedNets and InstaHide, aiming to achieve a better trade-off among the level of protection for outsourced DNN model training, the expenses, and the utility of data. DisguisedNets are novel combinations of image blocktization, block-level random permutation, and two block-level secure transformations: random multidimensional projection (RMT) and AES pixel-level encryption (AES). InstaHide is an image mixup and random pixel flipping technique \cite{huang20}. We have analyzed and evaluated them under a multi-level threat model. RMT provides a better security guarantee than InstaHide, under the Level-1 adversarial knowledge with well-preserved model quality. In contrast, AES provides a security guarantee under the Level-2 adversarial knowledge, but it may affect model quality more. The unique features of image disguising also help us to protect models from model-targeted attacks. We have done an extensive experimental evaluation to understand how these methods work in different settings for different datasets.
GAN-based Domain Inference Attack
Dec 22, 2022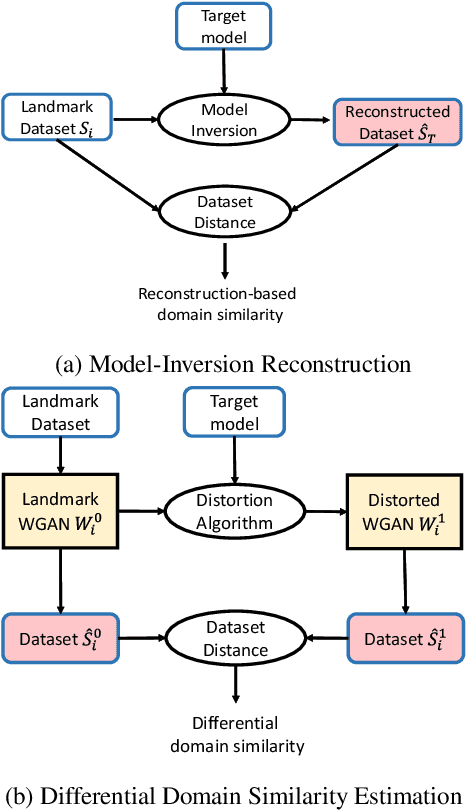
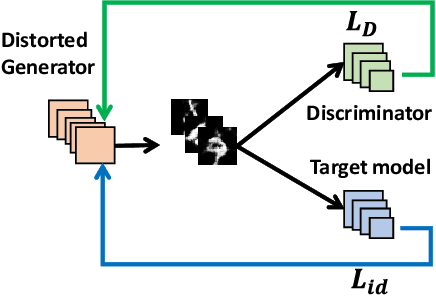
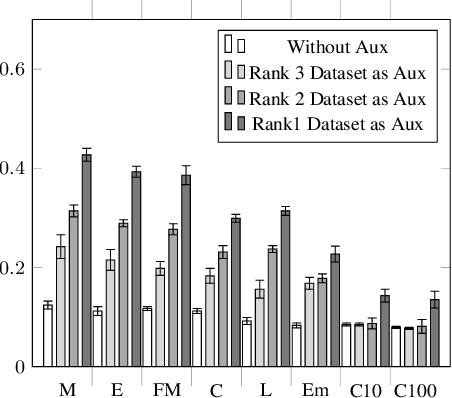
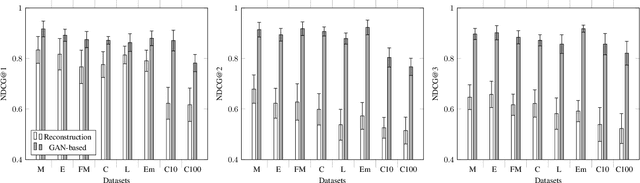
Model-based attacks can infer training data information from deep neural network models. These attacks heavily depend on the attacker's knowledge of the application domain, e.g., using it to determine the auxiliary data for model-inversion attacks. However, attackers may not know what the model is used for in practice. We propose a generative adversarial network (GAN) based method to explore likely or similar domains of a target model -- the model domain inference (MDI) attack. For a given target (classification) model, we assume that the attacker knows nothing but the input and output formats and can use the model to derive the prediction for any input in the desired form. Our basic idea is to use the target model to affect a GAN training process for a candidate domain's dataset that is easy to obtain. We find that the target model may distract the training procedure less if the domain is more similar to the target domain. We then measure the distraction level with the distance between GAN-generated datasets, which can be used to rank candidate domains for the target model. Our experiments show that the auxiliary dataset from an MDI top-ranked domain can effectively boost the result of model-inversion attacks.