 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAN-based Domain Inference Attack
Paper and Code
Dec 22, 2022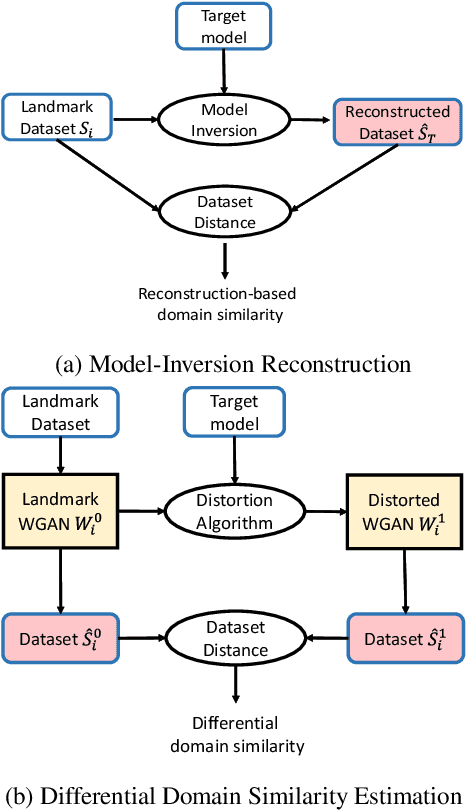
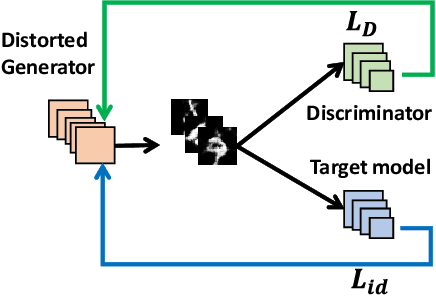
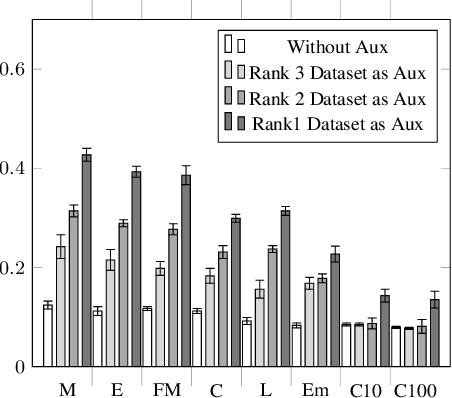
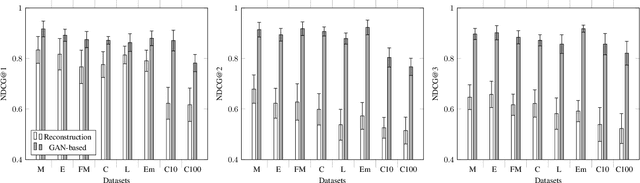
Model-based attacks can infer training data information from deep neural network models. These attacks heavily depend on the attacker's knowledge of the application domain, e.g., using it to determine the auxiliary data for model-inversion attacks. However, attackers may not know what the model is used for in practice. We propose a generative adversarial network (GAN) based method to explore likely or similar domains of a target model -- the model domain inference (MDI) attack. For a given target (classification) model, we assume that the attacker knows nothing but the input and output formats and can use the model to derive the prediction for any input in the desired form. Our basic idea is to use the target model to affect a GAN training process for a candidate domain's dataset that is easy to obtain. We find that the target model may distract the training procedure less if the domain is more similar to the target domain. We then measure the distraction level with the distance between GAN-generated datasets, which can be used to rank candidate domains for the target model. Our experiments show that the auxiliary dataset from an MDI top-ranked domain can effectively boost the result of model-inversion attacks.