 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Reconstructed with Dynamic Value Attention
Dec 22, 2025Since transformer was firstly published in 2017, several works have been proposed to optimize it. However, the major structure of transformer remains unchanged, ignoring one of its main intrinsic limitations, which is the same static value is used for every query in a head. Transformer itself tries to solve this problem by implementing multi-head attentions, yet the number of heads is limited by complexity. I propose a method to decide a value for each query dynamically, which could cut down all the redundant heads, keeping only one. Consequently, the following feed forward network could be cut down entirely, as each revised embedding has already fetched enough useful values far beyond the context. As a result, a single-head Dynamic Value Attention (DVA) is all you need in a transformer. According to the experiment, DVA may save 37.6% training time than the original transformer meanwhile increasing the learning capability.
Robust Cross-View Geo-Localization via Content-Viewpoint Disentanglement
May 17, 2025Cross-view geo-localization (CVGL) aims to match images of the same geographic location captured from different perspectives, such as drones and satellites. Despite recent advances, CVGL remains highly challenging due to significant appearance changes and spatial distortions caused by viewpoint variations. Existing methods typically assume that cross-view images can be directly aligned within a shared feature space by maximizing feature similarity through contrastive learning. Nonetheless, this assumption overlooks the inherent conflicts induced by viewpoint discrepancies, resulting in extracted features containing inconsistent information that hinders precise localization. In this study, we take a manifold learning perspective and model the feature space of cross-view images as a composite manifold jointly governed by content and viewpoint information. Building upon this insight, we propose $\textbf{CVD}$, a new CVGL framework that explicitly disentangles $\textit{content}$ and $\textit{viewpoint}$ factors. To promote effective disentanglement, we introduce two constraints: $\textit{(i)}$ An intra-view independence constraint, which encourages statistical independence between the two factors by minimizing their mutual information. $\textit{(ii)}$ An inter-view reconstruction constraint that reconstructs each view by cross-combining $\textit{content}$ and $\textit{viewpoint}$ from paired images, ensuring factor-specific semantics are preserved. As a plug-and-play module, CVD can be seamlessly integrated into existing geo-localization pipelines. Extensive experiments on four benchmarks, i.e., University-1652, SUES-200, CVUSA, and CVACT, demonstrate that CVD consistently improves both localization accuracy and generalization across multiple baselines.
Graph Contrastive Learning with Generative Adversarial Network
Aug 01, 2023



Graph Neural Networks (GNNs) have demonstrated promising results on exploiting node representations for many downstream tasks through supervised end-to-end training. To deal with the widespread label scarcity issue in real-world applications, Graph Contrastive Learning (GCL) is leveraged to train GNNs with limited or even no labels by maximizing the mutual information between nodes in its augmented views generated from the original graph. However, the distribution of graphs remains unconsidered in view generation, resulting in the ignorance of unseen edges in most existing literature, which is empirically shown to be able to improve GCL's performance in our experiments. To this end, we propose to incorporate graph generative adversarial networks (GANs) to learn the distribution of views for GCL, in order to i) automatically capture the characteristic of graphs for augmentations, and ii) jointly train the graph GAN model and the GCL model. Specifically, we present GACN, a novel Generative Adversarial Contrastive learning Network for graph representation learning. GACN develops a view generator and a view discriminator to generate augmented views automatically in an adversarial style. Then, GACN leverages these views to train a GNN encoder with two carefully designed self-supervised learning losses, including the graph contrastive loss and the Bayesian personalized ranking Loss. Furthermore, we design an optimization framework to train all GACN modules jointly. Extensive experiments on seven real-world datasets show that GACN is able to generate high-quality augmented views for GCL and is superior to twelve state-of-the-art baseline methods. Noticeably, our proposed GACN surprisingly discovers that the generated views in data augmentation finally conform to the well-known preferential attachment rule in online networks.
A novel adversarial learning strategy for medical image classification
Jul 07, 2022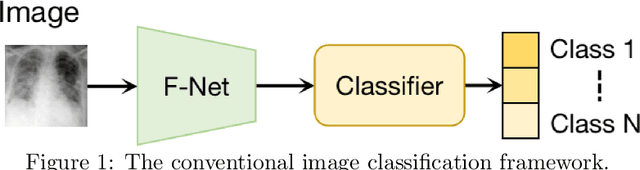
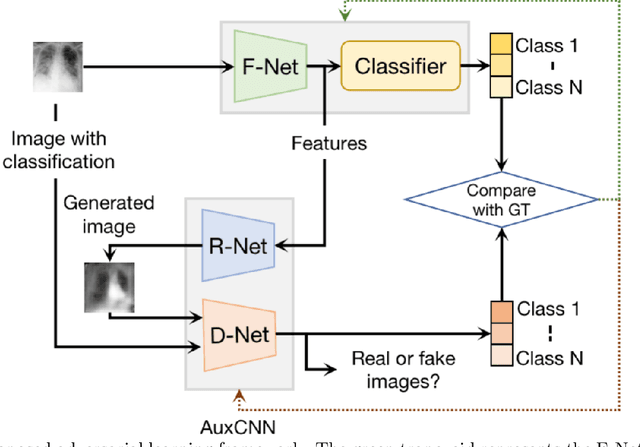
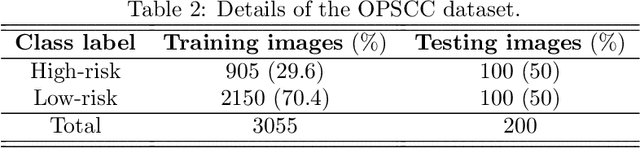
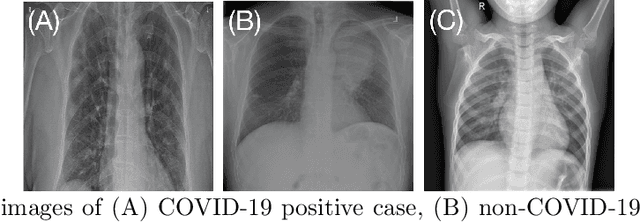
Deep learning (DL) techniques have been extensively utilized for medical image classification. Most DL-based classification networks are generally structured hierarchically and optimized through the minimization of a single loss function measured at the end of the networks. However, such a single loss design could potentially lead to optimization of one specific value of interest but fail to leverage informative features from intermediate layers that might benefit classification performance and reduce the risk of overfitting. Recently, auxiliary convolutional neural networks (AuxCNNs) have been employed on top of traditional classification networks to facilitate the training of intermediate layers to improve classification performance and robustness. In this study, we proposed an adversarial learning-based AuxCNN to support the training of deep neural networks for medical image classification. Two main innovations were adopted in our AuxCNN classification framework. First, the proposed AuxCNN architecture includes an image generator and an image discriminator for extracting more informative image features for medical image classification, motivated by the concept of generative adversarial network (GAN) and its impressive ability in approximating target data distribution. Second, a hybrid loss function is designed to guide the model training by incorporating different objectives of the classification network and AuxCNN to reduce overfitting. Comprehensive experimental studies demonstrated the superior classification performance of the proposed model. The effect of the network-related factors on classification performance was investigated.
De-IReps: Searching for improved Re-parameterizing Architecture based on Differentiable Evolution Strategy
Apr 13, 2022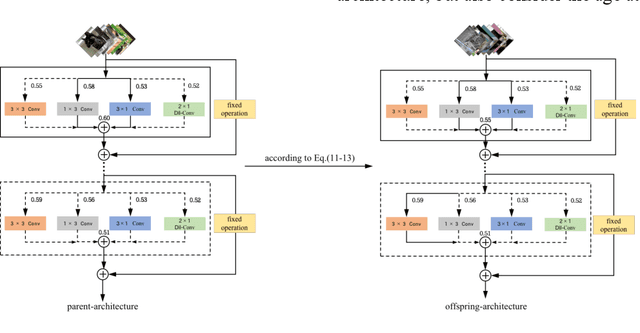
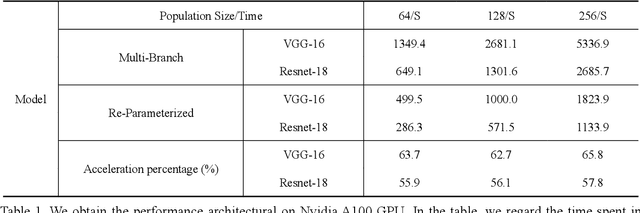
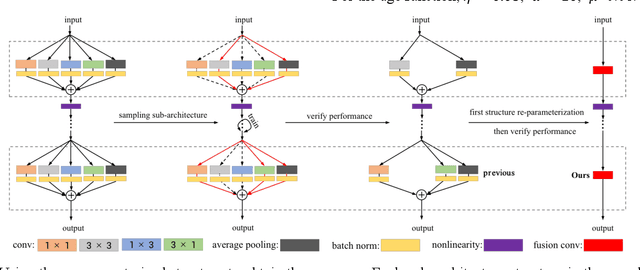
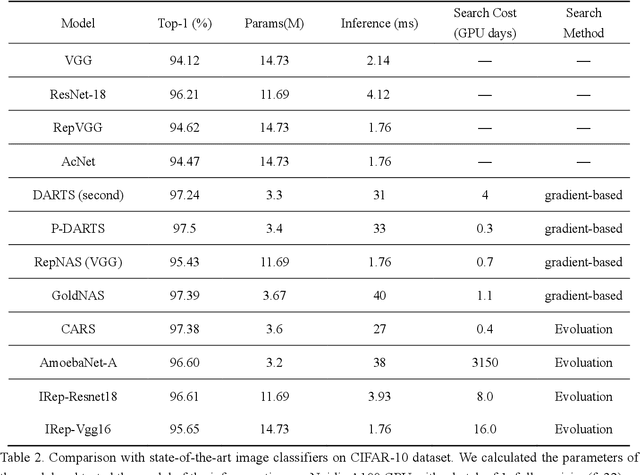
In recent years, neural architecture search (NAS) has shown great competitiveness in many fields and re-parameterization techniques have started to appear in the field of architectural search. However, most edge devices do not adapt well to networks, especially the multi-branch structure, which is searched by NAS. Therefore, in this work we design a search space that covers almost all re-parameterization operations. In this search space, multiple-path networks can be unconditionally re-parameterized into single-path networks. Thus, enhancing the usefulness of traditional nas. Meanwhile we summarize the characteristics of the re-parameterization search space and propose a differentiable evolutionary strategy (DES) to explore the re-parameterization search space. We visualize the features of the searched architecture and give our explanation for the appearance of this architecture. In this work, we can achieve efficient search and find better network structures. Respectively, we completed the architecture search on CIFAR-10 with the test accuracy of 96.64% (IrepResNet-18) and 95.65% (IrepVGG-16) and on ImageNet with the test accuracy of 77.92% (Irep-ResNet-50).
Delayed Rewards Calibration via Reward Empirical Sufficiency
Feb 23, 2021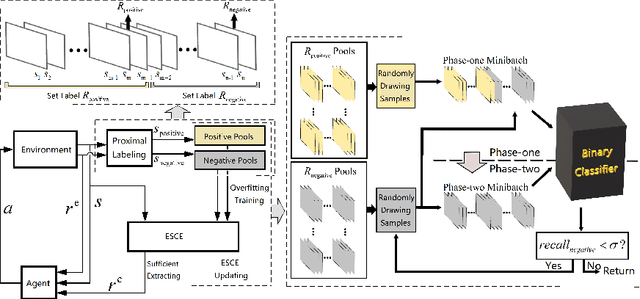
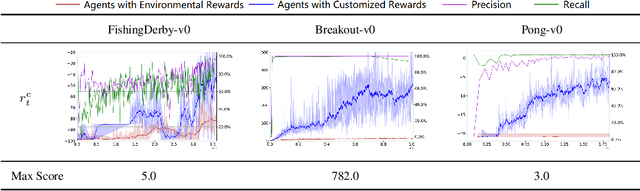

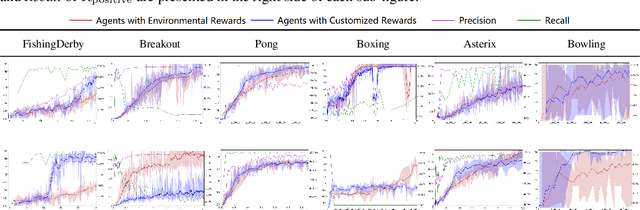
Appropriate credit assignment for delay rewards is a fundamental challenge for reinforcement learning. To tackle this problem, we introduce a delay reward calibration paradigm inspired from a classification perspective. We hypothesize that well-represented state vectors share similarities with each other since they contain the same or equivalent essential information. To this end, we define an empirical sufficient distribution, where the state vectors within the distribution will lead agents to environmental reward signals in the consequent steps. Therefore, a purify-trained classifier is designed to obtain the distribution and generate the calibrated rewards. We examine the correctness of sufficient state extraction by tracking the real-time extraction and building different reward functions in environments. The results demonstrate that the classifier could generate timely and accurate calibrated rewards. Moreover, the rewards are able to make the model training process more efficient. Finally, we identify and discuss that the sufficient states extracted by our model resonate with the observations of humans.
Inductive Granger Causal Modeling for Multivariate Time Series
Feb 10, 2021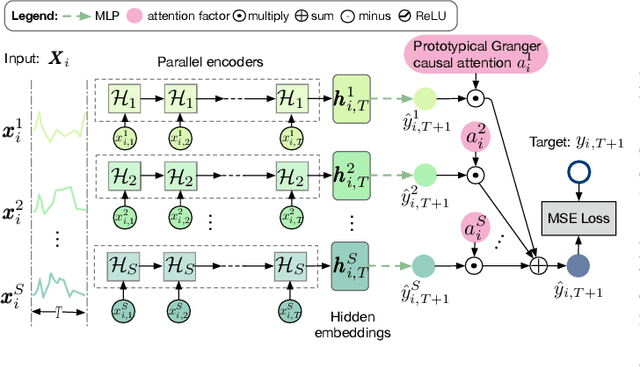
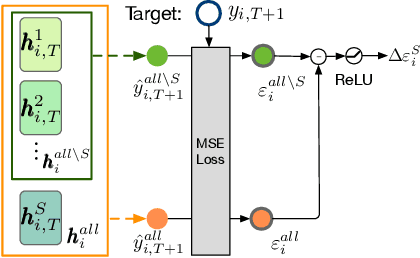

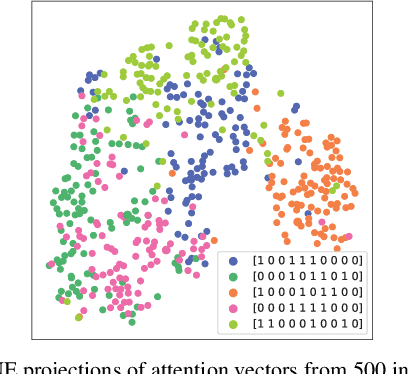
Granger causal modeling is an emerging topic that can uncover Granger causal relationship behind multivariate time series data. In many real-world systems, it is common to encounter a large amount of multivariate time series data collected from different individuals with sharing commonalities. However, there are ongoing concerns regarding Granger causality's applicability in such large scale complex scenarios, presenting both challenges and opportunities for Granger causal structure reconstruction. Existing methods usually train a distinct model for each individual, suffering from inefficiency and over-fitting issues. To bridge this gap, we propose an Inductive GRanger cAusal modeling (InGRA) framework for inductive Granger causality learning and common causal structure detection on multivariate time series, which exploits the shared commonalities underlying the different individuals. In particular, we train one global model for individuals with different Granger causal structures through a novel attention mechanism, called prototypical Granger causal attention. The model can detect common causal structures for different individuals and infer Granger causal structures for newly arrived individuals. Extensive experiments, as well as an online A/B test on an E-commercial advertising platform, demonstrate the superior performances of InGRA.
Active Lighting Recurrence by Parallel Lighting Analogy for Fine-Grained Change Detection
Feb 22, 2020
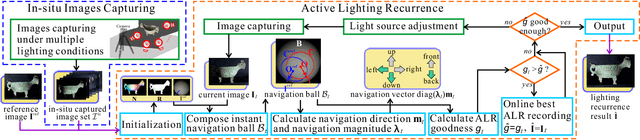
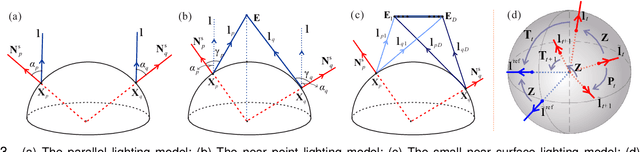
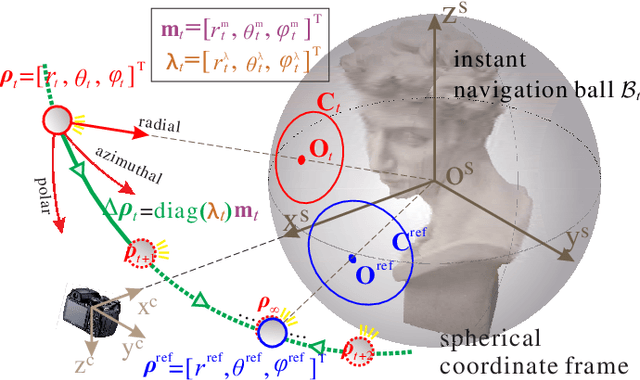
This paper studies a new problem, namely active lighting recurrence (ALR) that physically relocalizes a light source to reproduce the lighting condition from single reference image for a same scene, which may suffer from fine-grained changes during twice observations. ALR is of great importance for fine-grained visual inspection and change detection, because some phenomena or minute changes can only be clearly observed under particular lighting conditions. Therefore, effective ALR should be able to online navigate a light source toward the target pose, which is challenging due to the complexity and diversity of real-world lighting and imaging processes. To this end, we propose to use the simple parallel lighting as an analogy model and based on Lambertian law to compose an instant navigation ball for this purpose. We theoretically prove the feasibility, i.e., equivalence and convergence, of this ALR approach for realistic near point light source and small near surface light source. Besides, we also theoretically prove the invariance of our ALR approach to the ambiguity of normal and lighting decomposition. The effectiveness and superiority of the proposed approach have been verified by both extensive quantitative experiments and challenging real-world tasks on fine-grained change detection of cultural heritages. We also validate the generality of our approach to non-Lambertian scenes.
Sequential Scenario-Specific Meta Learner for Online Recommendation
Jun 02, 2019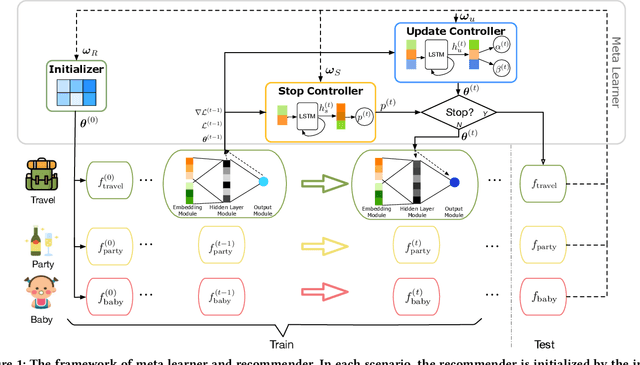

Cold-start problems are long-standing challenges for practical recommendations. Most existing recommendation algorithms rely on extensive observed data and are brittle to recommendation scenarios with few interactions. This paper addresses such problems using few-shot learning and meta learning. Our approach is based on the insight that having a good generalization from a few examples relies on both a generic model initialization and an effective strategy for adapting this model to newly arising tasks. To accomplish this, we combine the scenario-specific learning with a model-agnostic sequential meta-learning and unify them into an integrated end-to-end framework, namely Scenario-specific Sequential Meta learner (or s^2 meta). By doing so, our meta-learner produces a generic initial model through aggregating contextual information from a variety of prediction tasks while effectively adapting to specific tasks by leveraging learning-to-learn knowledge. Extensive experiments on various real-world datasets demonstrate that our proposed model can achieve significant gains over the state-of-the-arts for cold-start problems in online recommendation. Deployment is at the Guess You Like session, the front page of the Mobile Taobao.
Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
May 09, 2018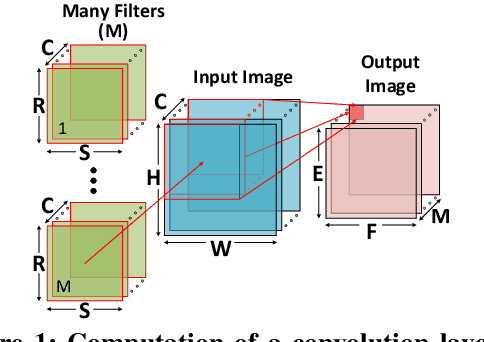
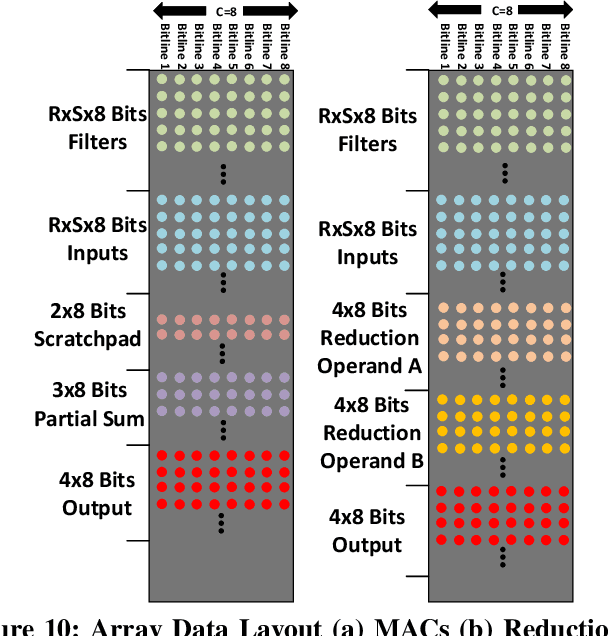
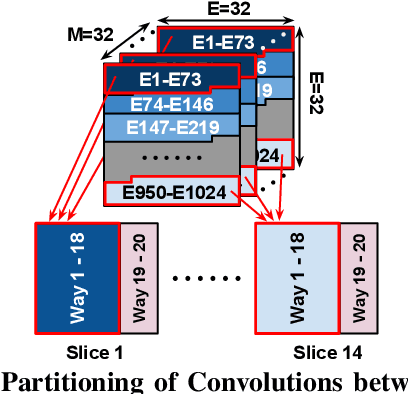
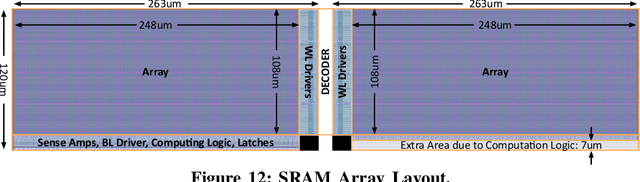
This paper presents the Neural Cache architecture, which re-purposes cache structures to transform them into massively parallel compute units capable of running inferences for Deep Neural Networks. Techniques to do in-situ arithmetic in SRAM arrays, create efficient data mapping and reducing data movement are proposed. The Neural Cache architecture is capable of fully executing convolutional, fully connected, and pooling layers in-cache. The proposed architecture also supports quantization in-cache. Our experimental results show that the proposed architecture can improve inference latency by 18.3x over state-of-art multi-core CPU (Xeon E5), 7.7x over server class GPU (Titan Xp), for Inception v3 model. Neural Cache improves inference throughput by 12.4x over CPU (2.2x over GPU), while reducing power consumption by 50% over CPU (53% over GPU).