 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePacTure: Efficient PBR Texture Generation on Packed Views with Visual Autoregressive Models
May 28, 2025We present PacTure, a novel framework for generating physically-based rendering (PBR) material textures from an untextured 3D mesh, a text description, and an optional image prompt. Early 2D generation-based texturing approaches generate textures sequentially from different views, resulting in long inference times and globally inconsistent textures. More recent approaches adopt multi-view generation with cross-view attention to enhance global consistency, which, however, limits the resolution for each view. In response to these weaknesses, we first introduce view packing, a novel technique that significantly increases the effective resolution for each view during multi-view generation without imposing additional inference cost, by formulating the arrangement of multi-view maps as a 2D rectangle bin packing problem. In contrast to UV mapping, it preserves the spatial proximity essential for image generation and maintains full compatibility with current 2D generative models. To further reduce the inference cost, we enable fine-grained control and multi-domain generation within the next-scale prediction autoregressive framework to create an efficient multi-view multi-domain generative backbone. Extensive experiments show that PacTure outperforms state-of-the-art methods in both quality of generated PBR textures and efficiency in training and inference.
Bilateral Propagation Network for Depth Completion
Apr 01, 2024



Depth completion aims to derive a dense depth map from sparse depth measurements with a synchronized color image. Current state-of-the-art (SOTA) methods are predominantly propagation-based, which work as an iterative refinement on the initial estimated dense depth. However, the initial depth estimations mostly result from direct applications of convolutional layers on the sparse depth map. In this paper, we present a Bilateral Propagation Network (BP-Net), that propagates depth at the earliest stage to avoid directly convolving on sparse data. Specifically, our approach propagates the target depth from nearby depth measurements via a non-linear model, whose coefficients are generated through a multi-layer perceptron conditioned on both \emph{radiometric difference} and \emph{spatial distance}. By integrating bilateral propagation with multi-modal fusion and depth refinement in a multi-scale framework, our BP-Net demonstrates outstanding performance on both indoor and outdoor scenes. It achieves SOTA on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. Experimental results not only show the effectiveness of bilateral propagation but also emphasize the significance of early-stage propagation in contrast to the refinement stage. Our code and trained models will be available on the project page.
Active Lighting Recurrence by Parallel Lighting Analogy for Fine-Grained Change Detection
Feb 22, 2020
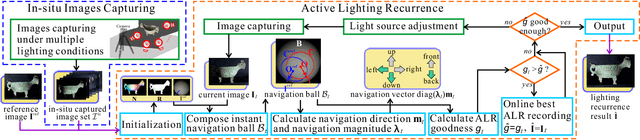
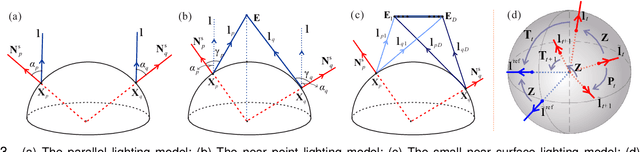
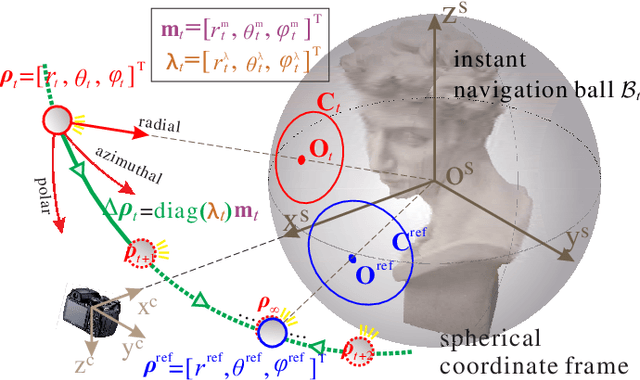
This paper studies a new problem, namely active lighting recurrence (ALR) that physically relocalizes a light source to reproduce the lighting condition from single reference image for a same scene, which may suffer from fine-grained changes during twice observations. ALR is of great importance for fine-grained visual inspection and change detection, because some phenomena or minute changes can only be clearly observed under particular lighting conditions. Therefore, effective ALR should be able to online navigate a light source toward the target pose, which is challenging due to the complexity and diversity of real-world lighting and imaging processes. To this end, we propose to use the simple parallel lighting as an analogy model and based on Lambertian law to compose an instant navigation ball for this purpose. We theoretically prove the feasibility, i.e., equivalence and convergence, of this ALR approach for realistic near point light source and small near surface light source. Besides, we also theoretically prove the invariance of our ALR approach to the ambiguity of normal and lighting decomposition. The effectiveness and superiority of the proposed approach have been verified by both extensive quantitative experiments and challenging real-world tasks on fine-grained change detection of cultural heritages. We also validate the generality of our approach to non-Lambertian scenes.
Learning Guided Convolutional Network for Depth Completion
Aug 03, 2019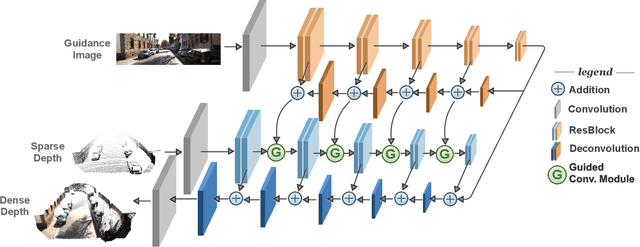
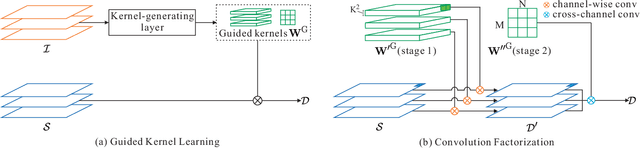


Dense depth perception is critical for autonomous driving and other robotics applications. However, modern LiDAR sensors only provide sparse depth measurement. It is thus necessary to complete the sparse LiDAR data, where a synchronized guidance RGB image is often used to facilitate this completion. Many neural networks have been designed for this task. However, they often na\"{\i}vely fuse the LiDAR data and RGB image information by performing feature concatenation or element-wise addition. Inspired by the guided image filtering, we design a novel guided network to predict kernel weights from the guidance image. These predicted kernels are then applied to extract the depth image features. In this way, our network generates content-dependent and spatially-variant kernels for multi-modal feature fusion. Dynamically generated spatially-variant kernels could lead to prohibitive GPU memory consumption and computation overhead. We further design a convolution factorization to reduce computation and memory consumption. The GPU memory reduction makes it possible for feature fusion to work in multi-stage scheme. We conduct comprehensive experiments to verify our method on real-world outdoor, indoor and synthetic datasets. Our method produces strong results. It outperforms state-of-the-art methods on the NYUv2 dataset and ranks 1st on the KITTI depth completion benchmark at the time of submission. It also presents strong generalization capability under different 3D point densities, various lighting and weather conditions as well as cross-dataset evaluations. The code will be released for reproduction.