 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo AI Overviews Benefit Search Engines? An Ecosystem Perspective
Jan 30, 2026The integration of AI Overviews into search engines enhances user experience but diverts traffic from content creators, potentially discouraging high-quality content creation and causing user attrition that undermines long-term search engine profit. To address this issue, we propose a game-theoretic model of creator competition with costly effort, characterize equilibrium behavior, and design two incentive mechanisms: a citation mechanism that references sources within an AI Overview, and a compensation mechanism that offers monetary rewards to creators. For both cases, we provide structural insights and near-optimal profit-maximizing mechanisms. Evaluations on real click data show that although AI Overviews harm long-term search engine profit, interventions based on our proposed mechanisms can increase long-term profit across a range of realistic scenarios, pointing toward a more sustainable trajectory for AI-enhanced search ecosystems.
Towards Deeper Emotional Reflection: Crafting Affective Image Filters with Generative Priors
Dec 19, 2025

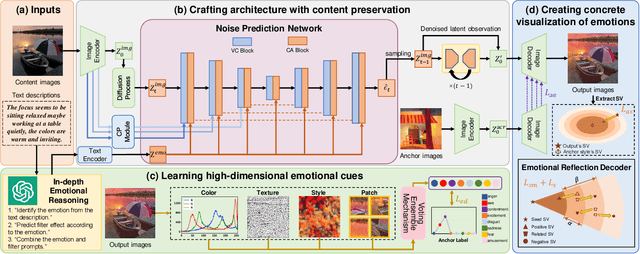

Social media platforms enable users to express emotions by posting text with accompanying images. In this paper, we propose the Affective Image Filter (AIF) task, which aims to reflect visually-abstract emotions from text into visually-concrete images, thereby creating emotionally compelling results. We first introduce the AIF dataset and the formulation of the AIF models. Then, we present AIF-B as an initial attempt based on a multi-modal transformer architecture. After that, we propose AIF-D as an extension of AIF-B towards deeper emotional reflection, effectively leveraging generative priors from pre-trained large-scale diffusion models. Quantitative and qualitative experiments demonstrate that AIF models achieve superior performance for both content consistency and emotional fidelity compared to state-of-the-art methods. Extensive user study experiments demonstrate that AIF models are significantly more effective at evoking specific emotions. Based on the presented results, we comprehensively discuss the value and potential of AIF models.
Hybrid Mesh-Gaussian Representation for Efficient Indoor Scene Reconstruction
Jun 08, 20253D Gaussian splatting (3DGS) has demonstrated exceptional performance in image-based 3D reconstruction and real-time rendering. However, regions with complex textures require numerous Gaussians to capture significant color variations accurately, leading to inefficiencies in rendering speed. To address this challenge, we introduce a hybrid representation for indoor scenes that combines 3DGS with textured meshes. Our approach uses textured meshes to handle texture-rich flat areas, while retaining Gaussians to model intricate geometries. The proposed method begins by pruning and refining the extracted mesh to eliminate geometrically complex regions. We then employ a joint optimization for 3DGS and mesh, incorporating a warm-up strategy and transmittance-aware supervision to balance their contributions seamlessly.Extensive experiments demonstrate that the hybrid representation maintains comparable rendering quality and achieves superior frames per second FPS with fewer Gaussian primitives.
PacTure: Efficient PBR Texture Generation on Packed Views with Visual Autoregressive Models
May 28, 2025We present PacTure, a novel framework for generating physically-based rendering (PBR) material textures from an untextured 3D mesh, a text description, and an optional image prompt. Early 2D generation-based texturing approaches generate textures sequentially from different views, resulting in long inference times and globally inconsistent textures. More recent approaches adopt multi-view generation with cross-view attention to enhance global consistency, which, however, limits the resolution for each view. In response to these weaknesses, we first introduce view packing, a novel technique that significantly increases the effective resolution for each view during multi-view generation without imposing additional inference cost, by formulating the arrangement of multi-view maps as a 2D rectangle bin packing problem. In contrast to UV mapping, it preserves the spatial proximity essential for image generation and maintains full compatibility with current 2D generative models. To further reduce the inference cost, we enable fine-grained control and multi-domain generation within the next-scale prediction autoregressive framework to create an efficient multi-view multi-domain generative backbone. Extensive experiments show that PacTure outperforms state-of-the-art methods in both quality of generated PBR textures and efficiency in training and inference.
Improved Algorithm and Bounds for Successive Projection
Mar 16, 2024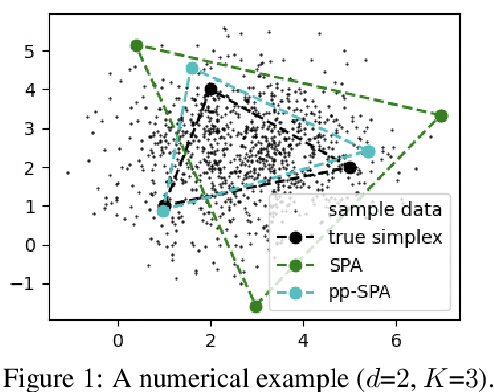

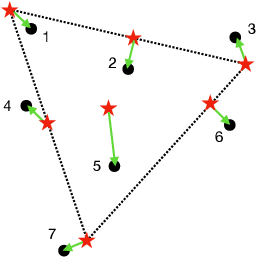
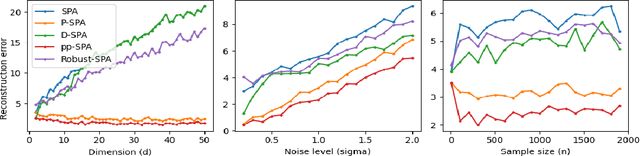
Given a $K$-vertex simplex in a $d$-dimensional space, suppose we measure $n$ points on the simplex with noise (hence, some of the observed points fall outside the simplex). Vertex hunting is the problem of estimating the $K$ vertices of the simplex. A popular vertex hunting algorithm is successive projection algorithm (SPA). However, SPA is observed to perform unsatisfactorily under strong noise or outliers. We propose pseudo-point SPA (pp-SPA). It uses a projection step and a denoise step to generate pseudo-points and feed them into SPA for vertex hunting. We derive error bounds for pp-SPA, leveraging on extreme value theory of (possibly) high-dimensional random vectors. The results suggest that pp-SPA has faster rates and better numerical performances than SPA. Our analysis includes an improved non-asymptotic bound for the original SPA, which is of independent interest.
DeRenderNet: Intrinsic Image Decomposition of Urban Scenes with Shape-(In)dependent Shading Rendering
Apr 28, 2021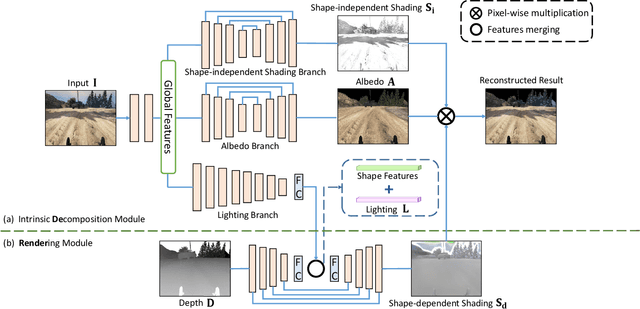
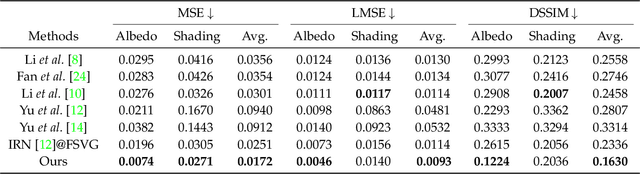
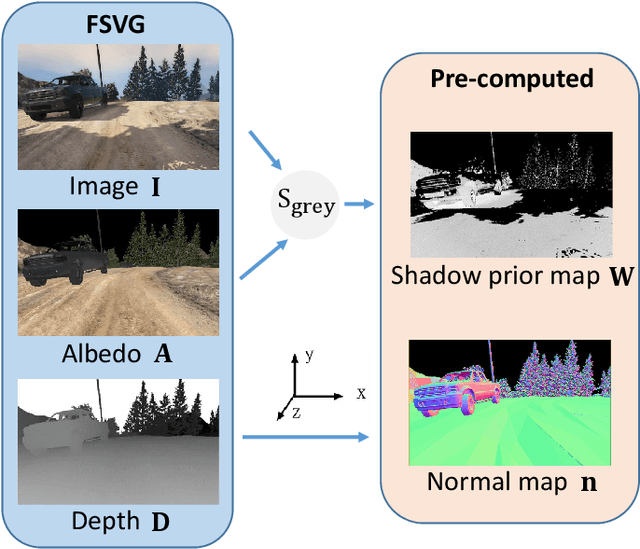
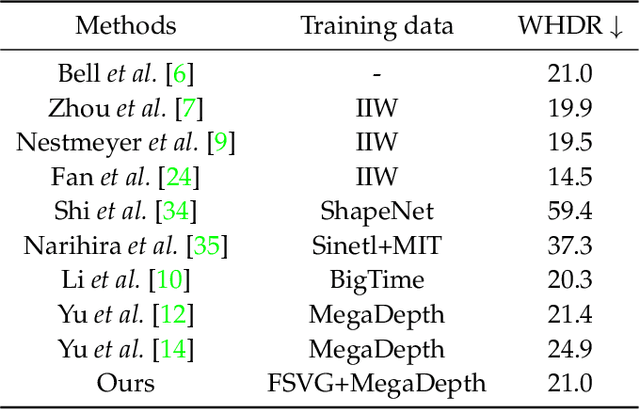
We propose DeRenderNet, a deep neural network to decompose the albedo and latent lighting, and render shape-(in)dependent shadings, given a single image of an outdoor urban scene, trained in a self-supervised manner. To achieve this goal, we propose to use the albedo maps extracted from scenes in videogames as direct supervision and pre-compute the normal and shadow prior maps based on the depth maps provided as indirect supervision. Compared with state-of-the-art intrinsic image decomposition methods, DeRenderNet produces shadow-free albedo maps with clean details and an accurate prediction of shadows in the shape-independent shading, which is shown to be effective in re-rendering and improving the accuracy of high-level vision tasks for urban scenes.
Complex Sequential Understanding through the Awareness of Spatial and Temporal Concepts
May 30, 2020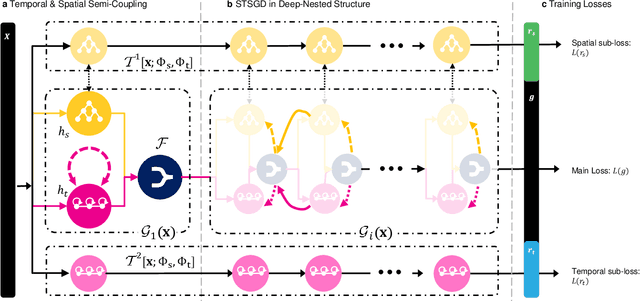
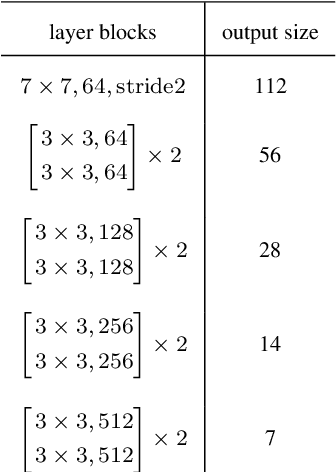
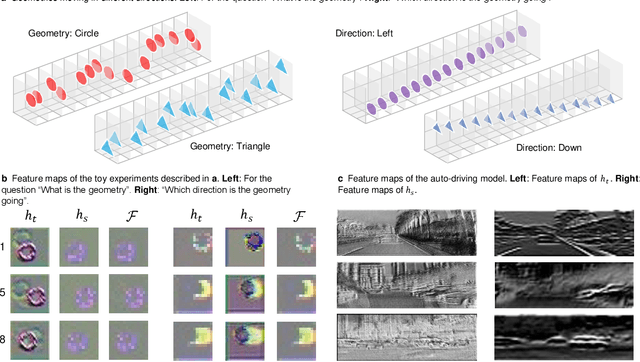
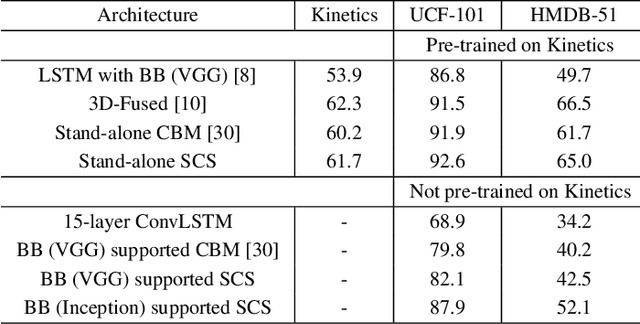
Understanding sequential information is a fundamental task for artificial intelligence. Current neural networks attempt to learn spatial and temporal information as a whole, limited their abilities to represent large scale spatial representations over long-range sequences. Here, we introduce a new modeling strategy called Semi-Coupled Structure (SCS), which consists of deep neural networks that decouple the complex spatial and temporal concepts learning. Semi-Coupled Structure can learn to implicitly separate input information into independent parts and process these parts respectively. Experiments demonstrate that a Semi-Coupled Structure can successfully annotate the outline of an object in images sequentially and perform video action recognition. For sequence-to-sequence problems, a Semi-Coupled Structure can predict future meteorological radar echo images based on observed images. Taken together, our results demonstrate that a Semi-Coupled Structure has the capacity to improve the performance of LSTM-like models on large scale sequential tasks.
* 15 pages, 5 figures, 8 tables
Asynchronous Interaction Aggregation for Action Detection
Apr 16, 2020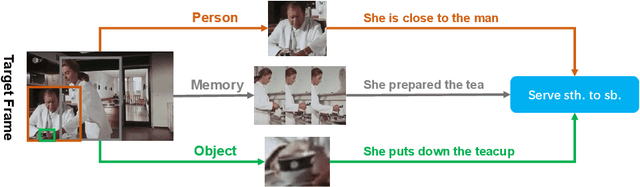
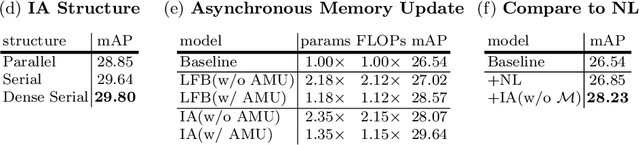
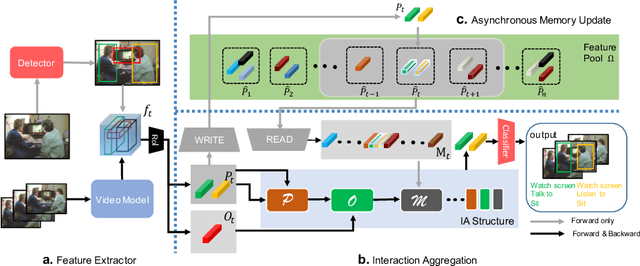

Understanding interaction is an essential part of video action detection. We propose the Asynchronous Interaction Aggregation network (AIA) that leverages different interactions to boost action detection. There are two key designs in it: one is the Interaction Aggregation structure (IA) adopting a uniform paradigm to model and integrate multiple types of interaction; the other is the Asynchronous Memory Update algorithm (AMU) that enables us to achieve better performance by modeling very long-term interaction dynamically without huge computation cost. We provide empirical evidence to show that our network can gain notable accuracy from the integrative interactions and is easy to train end-to-end. Our method reports the new state-of-the-art performance on AVA dataset, with 3.7 mAP gain (12.6% relative improvement) on validation split comparing to our strong baseline. The results on dataset UCF101-24 and EPIC-Kitchens further illustrate the effectiveness of our approach. Source code will be made public at: https://github.com/MVIG-SJTU/AlphAction .
Three Branches: Detecting Actions With Richer Features
Aug 13, 2019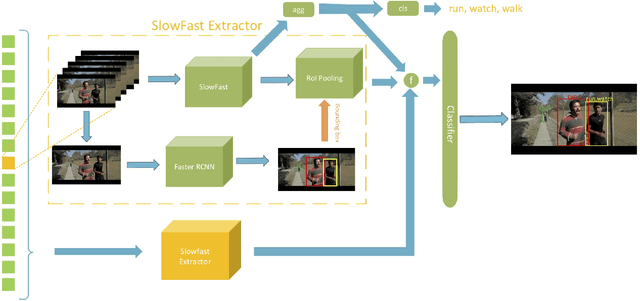

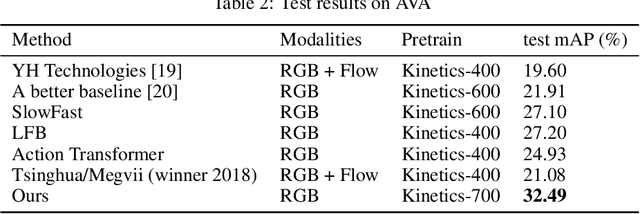
We present our three branch solutions for International Challenge on Activity Recognition at CVPR2019. This model seeks to fuse richer information of global video clip, short human attention and long-term human activity into a unified model. We have participated in two tasks: Task A, the Kinetics challenge and Task B, spatio-temporal action localization challenge. For Kinetics, we achieve 21.59% error rate. For the AVA challenge, our final model obtains 32.49% mAP on the test sets, which outperforms all submissions to the AVA challenge at CVPR 2018 for more than 10% mAP. As the future work, we will introduce human activity knowledge, which is a new dataset including key information of human activity.