 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffordGrasp: Cross-Modal Diffusion for Affordance-Aware Grasp Synthesis
Mar 09, 2026Generating human grasping poses that accurately reflect both object geometry and user-specified interaction semantics is essential for natural hand-object interactions in AR/VR and embodied AI. However, existing semantic grasping approaches struggle with the large modality gap between 3D object representations and textual instructions, and often lack explicit spatial or semantic constraints, leading to physically invalid or semantically inconsistent grasps. In this work, we present AffordGrasp, a diffusion-based framework that produces physically stable and semantically faithful human grasps with high precision. We first introduce a scalable annotation pipeline that automatically enriches hand-object interaction datasets with fine-grained structured language labels capturing interaction intent. Building upon these annotations, AffordGrasp integrates an affordance-aware latent representation of hand poses with a dual-conditioning diffusion process, enabling the model to jointly reason over object geometry, spatial affordances, and instruction semantics. A distribution adjustment module further enforces physical contact consistency and semantic alignment. We evaluate AffordGrasp across four instruction-augmented benchmarks derived from HO-3D, OakInk, GRAB, and AffordPose, and observe substantial improvements over state-of-the-art methods in grasp quality, semantic accuracy, and diversity.
Parallel Algorithms for Combined Regularized Support Vector Machines: Application in Music Genre Classification
Dec 08, 2025In the era of rapid development of artificial intelligence, its applications span across diverse fields, relying heavily on effective data processing and model optimization. Combined Regularized Support Vector Machines (CR-SVMs) can effectively handle the structural information among data features, but there is a lack of efficient algorithms in distributed-stored big data. To address this issue, we propose a unified optimization framework based on consensus structure. This framework is not only applicable to various loss functions and combined regularization terms but can also be effectively extended to non-convex regularization terms, showing strong scalability. Based on this framework, we develop a distributed parallel alternating direction method of multipliers (ADMM) algorithm to efficiently compute CR-SVMs when data is stored in a distributed manner. To ensure the convergence of the algorithm, we also introduce the Gaussian back-substitution method. Meanwhile, for the integrity of the paper, we introduce a new model, the sparse group lasso support vector machine (SGL-SVM), and apply it to music information retrieval. Theoretical analysis confirms that the computational complexity of the proposed algorithm is not affected by different regularization terms and loss functions, highlighting the universality of the parallel algorithm. Experiments on synthetic and free music archiv datasets demonstrate the reliability, stability, and efficiency of the algorithm.
Pack and Force Your Memory: Long-form and Consistent Video Generation
Oct 02, 2025Long-form video generation presents a dual challenge: models must capture long-range dependencies while preventing the error accumulation inherent in autoregressive decoding. To address these challenges, we make two contributions. First, for dynamic context modeling, we propose MemoryPack, a learnable context-retrieval mechanism that leverages both textual and image information as global guidance to jointly model short- and long-term dependencies, achieving minute-level temporal consistency. This design scales gracefully with video length, preserves computational efficiency, and maintains linear complexity. Second, to mitigate error accumulation, we introduce Direct Forcing, an efficient single-step approximating strategy that improves training-inference alignment and thereby curtails error propagation during inference. Together, MemoryPack and Direct Forcing substantially enhance the context consistency and reliability of long-form video generation, advancing the practical usability of autoregressive video models.
Hybrid Mesh-Gaussian Representation for Efficient Indoor Scene Reconstruction
Jun 08, 20253D Gaussian splatting (3DGS) has demonstrated exceptional performance in image-based 3D reconstruction and real-time rendering. However, regions with complex textures require numerous Gaussians to capture significant color variations accurately, leading to inefficiencies in rendering speed. To address this challenge, we introduce a hybrid representation for indoor scenes that combines 3DGS with textured meshes. Our approach uses textured meshes to handle texture-rich flat areas, while retaining Gaussians to model intricate geometries. The proposed method begins by pruning and refining the extracted mesh to eliminate geometrically complex regions. We then employ a joint optimization for 3DGS and mesh, incorporating a warm-up strategy and transmittance-aware supervision to balance their contributions seamlessly.Extensive experiments demonstrate that the hybrid representation maintains comparable rendering quality and achieves superior frames per second FPS with fewer Gaussian primitives.
Zero-P-to-3: Zero-Shot Partial-View Images to 3D Object
May 29, 2025



Generative 3D reconstruction shows strong potential in incomplete observations. While sparse-view and single-image reconstruction are well-researched, partial observation remains underexplored. In this context, dense views are accessible only from a specific angular range, with other perspectives remaining inaccessible. This task presents two main challenges: (i) limited View Range: observations confined to a narrow angular scope prevent effective traditional interpolation techniques that require evenly distributed perspectives. (ii) inconsistent Generation: views created for invisible regions often lack coherence with both visible regions and each other, compromising reconstruction consistency. To address these challenges, we propose \method, a novel training-free approach that integrates the local dense observations and multi-source priors for reconstruction. Our method introduces a fusion-based strategy to effectively align these priors in DDIM sampling, thereby generating multi-view consistent images to supervise invisible views. We further design an iterative refinement strategy, which uses the geometric structures of the object to enhance reconstruction quality. Extensive experiments on multiple datasets show the superiority of our method over SOTAs, especially in invisible regions.
Enhancing Variable Selection in Large-scale Logistic Regression: Leveraging Manual Labeling with Beneficial Noise
Apr 23, 2025In large-scale supervised learning, penalized logistic regression (PLR) effectively addresses the overfitting problem by introducing regularization terms yet its performance still depends on efficient variable selection strategies. This paper theoretically demonstrates that label noise stemming from manual labeling, which is solely related to classification difficulty, represents a type of beneficial noise for variable selection in PLR. This benefit is reflected in a more accurate estimation of the selected non-zero coefficients when compared with the case where only truth labels are used. Under large-scale settings, the sample size for PLR can become very large, making it infeasible to store on a single machine. In such cases, distributed computing methods are required to handle PLR model with manual labeling. This paper presents a partition-insensitive parallel algorithm founded on the ADMM (alternating direction method of multipliers) algorithm to address PLR by incorporating manual labeling. The partition insensitivity of the proposed algorithm refers to the fact that the solutions obtained by the algorithm will not change with the distributed storage of data. In addition, the algorithm has global convergence and a sublinear convergence rate. Experimental results indicate that, as compared with traditional variable selection classification techniques, the PLR with manually-labeled noisy data achieves higher estimation and classification accuracy across multiple large-scale datasets.
OccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Mar 20, 2025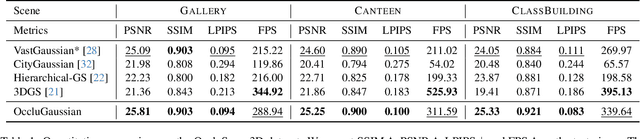
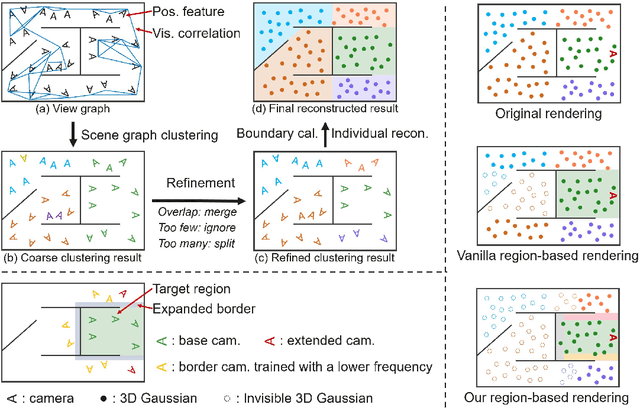
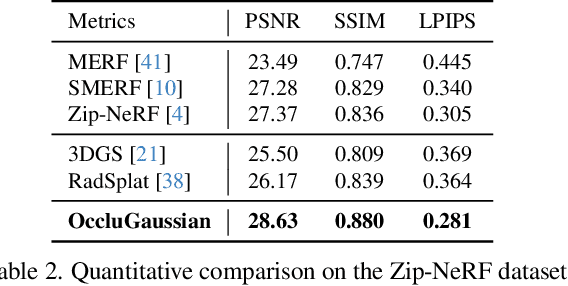
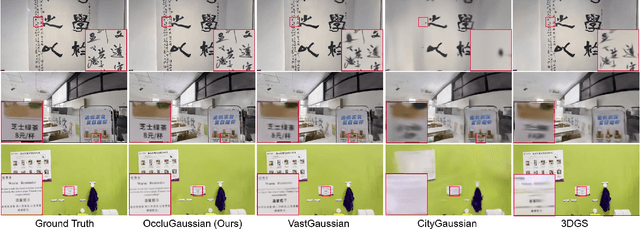
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
Decoupling Appearance Variations with 3D Consistent Features in Gaussian Splatting
Jan 18, 2025



Gaussian Splatting has emerged as a prominent 3D representation in novel view synthesis, but it still suffers from appearance variations, which are caused by various factors, such as modern camera ISPs, different time of day, weather conditions, and local light changes. These variations can lead to floaters and color distortions in the rendered images/videos. Recent appearance modeling approaches in Gaussian Splatting are either tightly coupled with the rendering process, hindering real-time rendering, or they only account for mild global variations, performing poorly in scenes with local light changes. In this paper, we propose DAVIGS, a method that decouples appearance variations in a plug-and-play and efficient manner. By transforming the rendering results at the image level instead of the Gaussian level, our approach can model appearance variations with minimal optimization time and memory overhead. Furthermore, our method gathers appearance-related information in 3D space to transform the rendered images, thus building 3D consistency across views implicitly. We validate our method on several appearance-variant scenes, and demonstrate that it achieves state-of-the-art rendering quality with minimal training time and memory usage, without compromising rendering speeds. Additionally, it provides performance improvements for different Gaussian Splatting baselines in a plug-and-play manner.
FastGrasp: Efficient Grasp Synthesis with Diffusion
Nov 22, 2024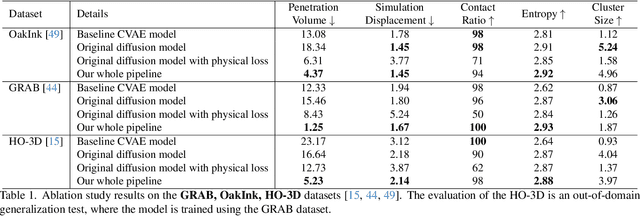
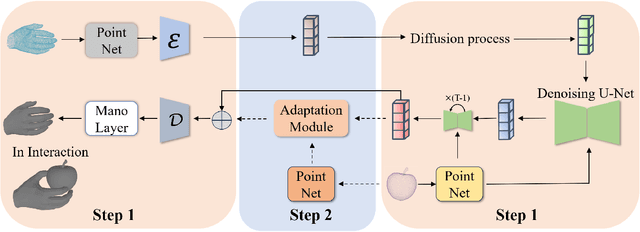
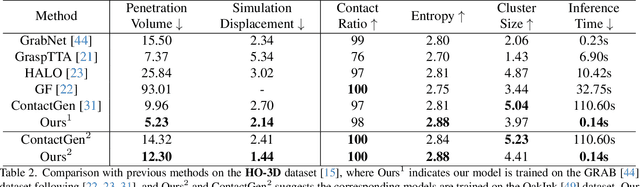
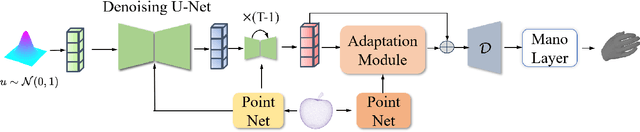
Effectively modeling the interaction between human hands and objects is challenging due to the complex physical constraints and the requirement for high generation efficiency in applications. Prior approaches often employ computationally intensive two-stage approaches, which first generate an intermediate representation, such as contact maps, followed by an iterative optimization procedure that updates hand meshes to capture the hand-object relation. However, due to the high computation complexity during the optimization stage, such strategies often suffer from low efficiency in inference. To address this limitation, this work introduces a novel diffusion-model-based approach that generates the grasping pose in a one-stage manner. This allows us to significantly improve generation speed and the diversity of generated hand poses. In particular, we develop a Latent Diffusion Model with an Adaptation Module for object-conditioned hand pose generation and a contact-aware loss to enforce the physical constraints between hands and objects. Extensive experiments demonstrate that our method achieves faster inference, higher diversity, and superior pose quality than state-of-the-art approaches. Code is available at \href{https://github.com/wuxiaofei01/FastGrasp}{https://github.com/wuxiaofei01/FastGrasp.}
EmoTalk3D: High-Fidelity Free-View Synthesis of Emotional 3D Talking Head
Aug 01, 2024



We present a novel approach for synthesizing 3D talking heads with controllable emotion, featuring enhanced lip synchronization and rendering quality. Despite significant progress in the field, prior methods still suffer from multi-view consistency and a lack of emotional expressiveness. To address these issues, we collect EmoTalk3D dataset with calibrated multi-view videos, emotional annotations, and per-frame 3D geometry. By training on the EmoTalk3D dataset, we propose a \textit{`Speech-to-Geometry-to-Appearance'} mapping framework that first predicts faithful 3D geometry sequence from the audio features, then the appearance of a 3D talking head represented by 4D Gaussians is synthesized from the predicted geometry. The appearance is further disentangled into canonical and dynamic Gaussians, learned from multi-view videos, and fused to render free-view talking head animation. Moreover, our model enables controllable emotion in the generated talking heads and can be rendered in wide-range views. Our method exhibits improved rendering quality and stability in lip motion generation while capturing dynamic facial details such as wrinkles and subtle expressions. Experiments demonstrate the effectiveness of our approach in generating high-fidelity and emotion-controllable 3D talking heads. The code and EmoTalk3D dataset are released at https://nju-3dv.github.io/projects/EmoTalk3D.