 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccluGaussian: Occlusion-Aware Gaussian Splatting for Large Scene Reconstruction and Rendering
Mar 20, 2025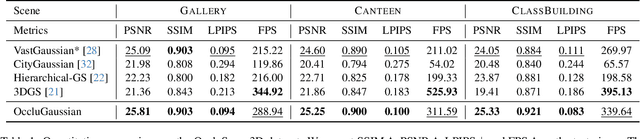
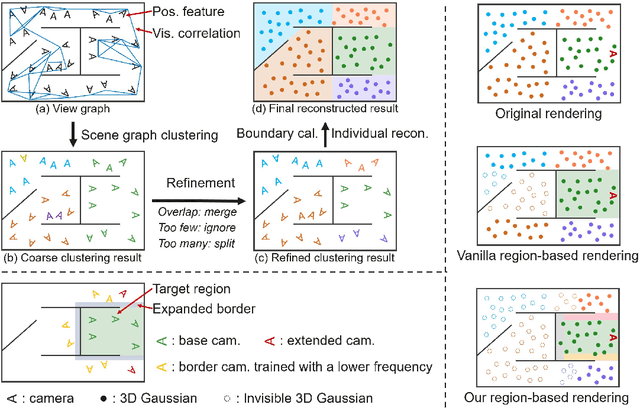
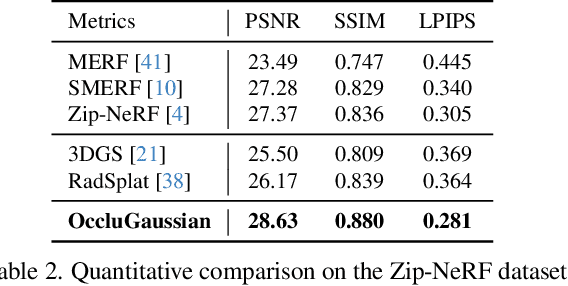
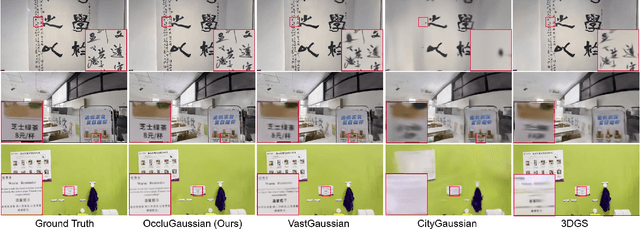
In large-scale scene reconstruction using 3D Gaussian splatting, it is common to partition the scene into multiple smaller regions and reconstruct them individually. However, existing division methods are occlusion-agnostic, meaning that each region may contain areas with severe occlusions. As a result, the cameras within those regions are less correlated, leading to a low average contribution to the overall reconstruction. In this paper, we propose an occlusion-aware scene division strategy that clusters training cameras based on their positions and co-visibilities to acquire multiple regions. Cameras in such regions exhibit stronger correlations and a higher average contribution, facilitating high-quality scene reconstruction. We further propose a region-based rendering technique to accelerate large scene rendering, which culls Gaussians invisible to the region where the viewpoint is located. Such a technique significantly speeds up the rendering without compromising quality. Extensive experiments on multiple large scenes show that our method achieves superior reconstruction results with faster rendering speed compared to existing state-of-the-art approaches. Project page: https://occlugaussian.github.io.
LASA: Instance Reconstruction from Real Scans using A Large-scale Aligned Shape Annotation Dataset
Dec 19, 2023Instance shape reconstruction from a 3D scene involves recovering the full geometries of multiple objects at the semantic instance level. Many methods leverage data-driven learning due to the intricacies of scene complexity and significant indoor occlusions. Training these methods often requires a large-scale, high-quality dataset with aligned and paired shape annotations with real-world scans. Existing datasets are either synthetic or misaligned, restricting the performance of data-driven methods on real data. To this end, we introduce LASA, a Large-scale Aligned Shape Annotation Dataset comprising 10,412 high-quality CAD annotations aligned with 920 real-world scene scans from ArkitScenes, created manually by professional artists. On this top, we propose a novel Diffusion-based Cross-Modal Shape Reconstruction (DisCo) method. It is empowered by a hybrid feature aggregation design to fuse multi-modal inputs and recover high-fidelity object geometries. Besides, we present an Occupancy-Guided 3D Object Detection (OccGOD) method and demonstrate that our shape annotations provide scene occupancy clues that can further improve 3D object detection. Supported by LASA, extensive experiments show that our methods achieve state-of-the-art performance in both instance-level scene reconstruction and 3D object detection tasks.